はじめに
この文書はWeb開発の入門ガイドです。 Web開発を進めていくための助けになれば幸いです。
目次
- はじめに
- Web開発入門
- Web開発研修
- Web開発環境構築
- 🔗 Reactフロントエンド開発入門
- REST APIと非同期処理
- Honoハンズオン
- Hono + React 連携
- 🔗 今日こそ理解するCORS
- SQLiteハンズオン
- 開発実践
- Node.js Test Runnerではじめる自動テスト
- Web
- JavaScript
- Webサイトを公開する
- Google Apps Script (GAS) で作るWebアプリ
- Raspberry Piで温度センサーのデータの送信
- Raspberry Piからスマートフォンにデータを送信する
- 🔗 Node.jsハンズオン
- 🔗 ソフトウェアテスト概論
- 🔗 Vitestハンズオン
- 🔗 Jestハンズオン
- 🔗 GraphQL概論
- 🔗 Hasura概論
- 🔗 Hasura RESTハンズオン
- 🔗 GitHub と CodeSandbox の使い方 (スライド資料)
- 🔗 CHIRIMENハンズオン
- 🔗 アジャイル開発概論
- 🔗 Scrapbox
- 質問・提案・問題の報告
― この文書は © 2023 MDN Web Docsプロジェクト協力者 クリエイティブ・コモンズ CC BY SA 2.5 ライセンスのもとに利用を許諾されています。 元の文書: https://developer.mozilla.org/ja/docs/Learn/Getting_started_with_the_web/What_will_your_website_look_like
Web開発入門
Web開発を始める前に考えておかなければいけないことがあります。Webサイトは様々なことができます。しかし複雑なものを開発するとしても、はじめはできるだけ単純なものから少しずつ理解を深めていくべきでしょう。
まずは、見出し、画像、段落のある単純なWebページを作ることから始めましょう。
- 何についてのWebページ? 犬、ニューヨーク、それともパックマン?
- どんな情報? タイトルといくつかの段落、それからページに表示させたい画像を考えます。
- どんな見た目? 簡単で大まかな言葉で言うと?背景色は?適切なフォントはフォーマル?漫画?太字で派手?繊細?
デザインをスケッチする
次に、ペンと紙を取ってサイトの見た目をどういう風にしたいのか大まかに描き出します。はじめてのシンプルなWebページでは、描き出すものもあまりないかもしれませんが、作る上での習慣にしましょう。(ヴァン・ゴッホのようになる必要はありません)
Note 現実の複雑なWebサイトの場合でも、デザインチームは普通、ラフスケッチを描くことから始めます。その後、グラフィックエディターや Web の技術を使って、デジタルのモックアップを作るのです。
多くの場合、Webの開発チームには、グラフィックデザイナーとユーザーエクスペリエンス (UX) デザイナーがいます。グラフィックデザイナーは、Webサイトの見た目を作り上げます。 UX デザイナーは、もう少し抽象的な役割を持っていて、サイトを訪れるユーザーがWebサイトでどういう経験をし、どのように操作するかということを考えます。
この時点で、Webページについて、どう表現したいかをまとめ始めていきましょう。
テキストエディター
Visual Studio Codeなどのテキストエディターを使用して忘れないようにメモしておきましょう。
- オンライン版 https://vscode.dev/
フォルダー
フォルダーは簡単に見つけることができる場所、たとえばデスクトップ上、ホームフォルダーの中、Cドライブのルートなどに置きましょう。
- Webサイトプロジェクトを保存する場所を選択してください。ここでは
web-projects(またはそのようなもの)という新しいフォルダーを作成します。これはWebサイトのプロジェクト全体を保存するところです。 - フォルダーの中に、最初のWebサイトを格納する別のフォルダーを作成します。それを
test-siteと呼びましょう(もっとユニークなものでもOK)。
コンテンツ
- タイトル: Mozilla is cool (例)
- 内容: Mozilla is cool (例)
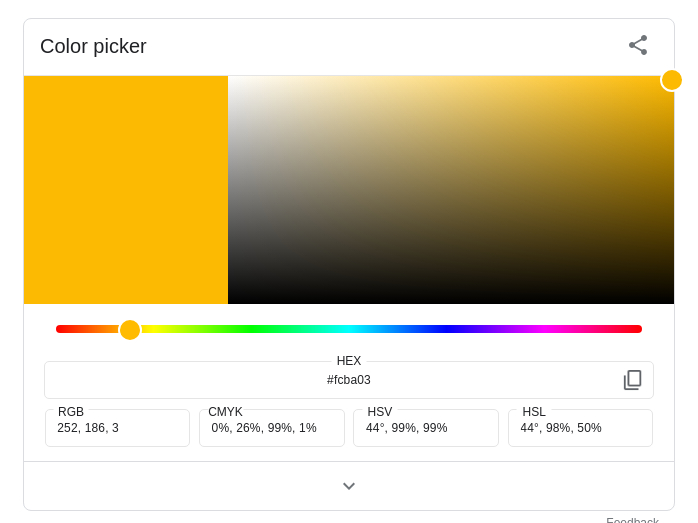
テーマカラー
色を選ぶときは、「カラー選択ツール」と検索し、好みの色を見つけましょう。色をクリックすると、 #fcba03 のような “#” + 6 桁の奇妙なコードが出てきます。これはヘキサコード(16 進数コード、0, 1, 2, …, 9, a, b, …, f までの16種類の数字を使うコード)と呼ばれ、選んだ色を表します。このコードはあとで使うのでコピーしておきましょう。
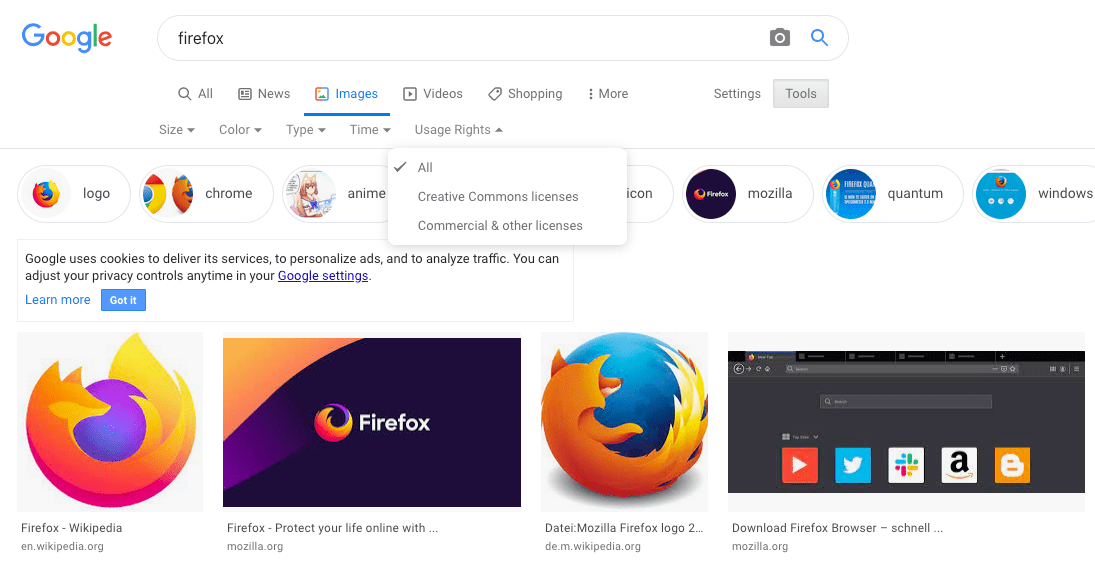
画像
画像を探すには、Google 画像検索にアクセスし、ぴったりなものを探しましょう。
- 欲しい画像が見つかったら、クリックして拡大表示にします。
- 画像を右クリック(Mac では Ctrl +クリック)し、[名前を付けて画像を保存…] を選択して、画像を安全に保存する場所を選択します。または、後で使用するためにブラウザーのアドレスバーから画像のWebアドレスをコピーします。

なお、Web上のほとんどの画像には、 Google 画像検索にあるものも含め、著作権があります。あなたが著作権を侵害してしまうことを防ぐために、 Google のライセンスフィルターを使うと良いでしょう。 [ツール] ボタンをクリックすると、 [ライセンス] オプションが下に表示されます。「クリエイティブ・コモンズ ライセンス」などの選択肢を選択してください。
Note
クリエイティブ・コモンズ・ライセンス (CCライセンス) とはCCライセンスとはインターネット時代のための新しい著作権ルールで、作品を公開する作者が「この条件を守れば私の作品を自由に使って構いません。」という意思表示をするためのツールです。
CCライセンスを利用することで、作者は著作権を保持したまま作品を自由に流通させることができ、受け手はライセンス条件の範囲内で再配布やリミックスなどをすることができます。
― この文書は © 2023 MDN Web Docsプロジェクト協力者 クリエイティブ・コモンズ CC BY SA 2.5 ライセンスのもとに利用を許諾されています。 元の文書: https://developer.mozilla.org/ja/docs/Learn/Getting_started_with_the_web/Dealing_with_files
ファイルの扱い
Webサイトは、テキストコンテンツ、コード、スタイルシート、メディアコンテンツなど、多くのファイルで構成されています。ここでは注意すべきいくつかの点を説明します。
コンピューター上でWebサイトがあるべき場所
コンピューター上のWebサイトの開発作業している時もWebサイトのファイルとフォルダーの構造は実際のWebサイトと同じようにしましょう。
フォルダーは簡単に見つけることができる場所、たとえばデスクトップ上、ホームフォルダーの中、Cドライブのルートなどに置きましょう。
- Webサイトプロジェクトを保存する場所を選択してください。ここでは
web-projects(またはそのようなもの)という新しいフォルダーを作成します。これはWebサイトのプロジェクト全体を保存するところです。 - フォルダーの中に、最初のWebサイトを格納する別のフォルダーを作成します。それを
test-siteと呼びましょう(もっとユニークなものでもOK)。
ファイル名・フォルダー名には日本語・大文字・空白を使わない
この文書ではフォルダーやファイルに空白のない全て半角小文字の名前を付けるよう求めています。理由は次の通りです。
- 多くのコンピューター、特にWebサーバーでは、大文字と小文字が区別されます。例えば、Webサイトの
test-site/MyImage.jpgに画像を置いて、別のファイルから画像をtest-site/myimage.jpgとして呼び出そうとすると、動作しないかもしれません。 - ブラウザー間、Webサーバー間、プログラミング言語間で、空白の扱いが一貫していません。例えば、ファイル名に空白を使用すると、システムによってはそのファイル名を 2 つのファイル名として扱うことがあります。サーバーによっては、ファイル名の空白を “%20” (URL の空白の文字コード)に置き換えるので、リンクが壊れてしまう結果になります。
my_file.htmlのように単語をアンダースコアで区切るよりは、my-file.htmlのようにハイフンで区切った方がよいでしょう。
Webサイトはどのような構成にするべきか
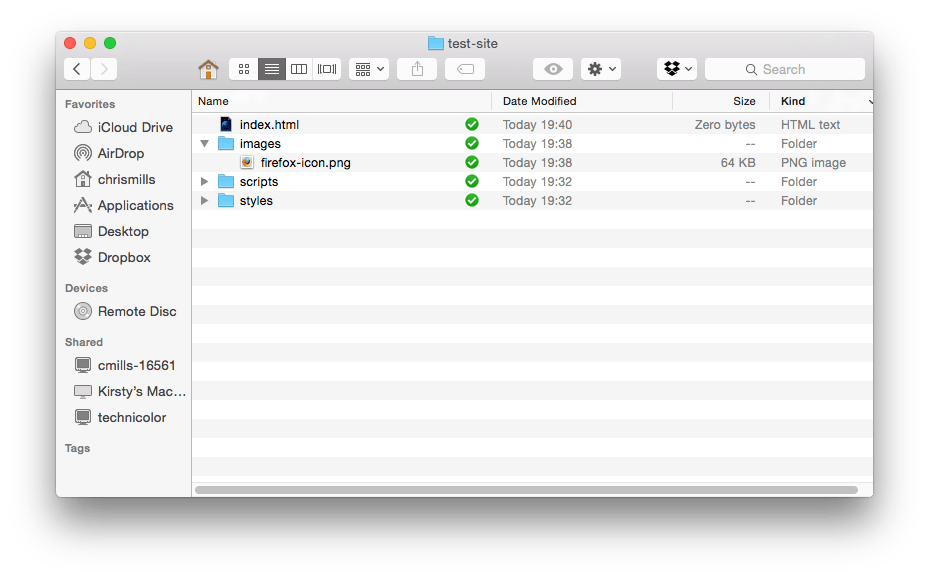
Webサイトプロジェクトで最も一般的なフォルダー構成は、(1) 目次の HTML ファイル、(2) 画像ファイル、(3) スタイルシート (見た目に関するコード)、(4) スクリプトファイル (JavaScriptのコード) を入れるフォルダーです。作成してみましょう。
index.html: このファイルには、一般的にあなたのホームページの内容、つまりあなたが最初にあなたのサイトに行ったときに見るテキストと画像が含まれています。テキストエディターを使用して、index.htmlという名前の新しいファイルを作成し、test-siteフォルダー内に保存します。imagesフォルダー: このフォルダーにはサイトで使用するすべての画像を入れます。test-siteフォルダーの中にimagesという名前のフォルダーを作成します。stylesフォルダー: このフォルダーには、コンテンツのスタイルを設定するための CSS コード(例えばテキストと背景色の設定など)を入れます。stylesというフォルダーをtest-siteのフォルダーの中に作成します。scriptsフォルダー: このフォルダーには、サイトに対話機能を追加するために使用されるすべての JavaScript コード(クリックされたときにデータを読み込むボタンなど)が含まれます。scriptsというフォルダーをtest-siteのフォルダーの中に作成します。
Note Windows では、既定で有効になっている既知のファイルの種類の拡張子を表示しないというオプションがあるため、ファイル名の表示に問題が発生することがあります。一般に、 Windows エクスプローラーで [フォルダーオプション…] オプションを選択し、[登録されている拡張子は表示しない] チェックボックスをオフにし、 [OK] をクリックすることで、これをオフにすることができます。お使いの Windows のバージョンに関する詳細な情報については、Webで検索してください。
ファイルパス
ファイルをお互いに呼び出すためには、ファイルパスを提供する必要があります。
画像ファイルは既存の画像を自由に選択して、以下の手順で使用することができます。
-
以前に選択した画像を
imagesフォルダーにコピーします。 -
index.htmlファイルを開き、次のコードをファイルに挿入します。それが今のところ何を意味するのか気にしないでください。シリーズの後半で構造を詳しく見ていきます。<!doctype html> <html lang="ja"> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width" /> <title>テストページ</title> </head> <body> <img src="" alt="テスト画像" /> </body> </html> -
<img src="" alt="テスト画像">という行は、ページに画像を挿入する HTML コードです。画像がどこにあるのかを HTML に伝える必要があります。画像は images ディレクトリー内にあり、index.htmlと同じディレクトリーにあります。ファイル構造の中でindex.htmlからその画像に移動するのに必要なファイルパスはimages/your-image-filenameです。例えば、私たちの画像はfirefox-icon.pngと呼ばれており、ファイルパスはimages/firefox-icon.pngになります。 -
src=""コードの二重引用符の間の HTML コードにファイルパスを挿入してください。 -
alt属性の内容を入れようとしている画像の説明に変更してください。今回は、alt="Firefoxのロゴ"とします。 -
HTML ファイルを保存し、Webブラウザーに読み込みます(ファイルをダブルクリックします)。新しいWebページに画像が表示されます。

ファイルパスの一般的なルールは次の通りです。
- 呼び出し元の HTML ファイルと同じディレクトリーにある対象ファイルにリンクするには、ファイル名を使用します。例えば
my-image.jpg。 - サブディレクトリー内のファイルを参照するには、パスの前にディレクトリー名とスラッシュを入力します。例えば
subdirectory/my-image.jpg。 - 呼び出し元の HTML ファイルの上階層のディレクトリー内にある対象ファイルにリンクするには、2 つのドットを記述します。例えば、
index.htmlがtest-siteのサブフォルダー内にあり、my-image.jpgがtest-site内にある場合、../my-image.jpgを使用してindex.htmlからmy-image.jpgを参照できます。 - 例えば
../subdirectory/another-subdirectory/my-image.jpgなど、好きなだけ組み合わせることができます。
Note Windows のファイルシステムでは、スラッシュ (/) ではなくバックスラッシュまたは¥記号を使用します(例 :
C:\Windows)。これは HTML では使用できません。Windows でWebサイトを開発している場合でも、コード内ではスラッシュを使用する必要があります。
他にするべきこと
今のところは以上です。フォルダー構造は次のようになります。
― この文書は © 2023 MDN Web Docsプロジェクト協力者 クリエイティブ・コモンズ CC BY SA 2.5 ライセンスのもとに利用を許諾されています。 元の文書: https://developer.mozilla.org/ja/docs/Learn/Getting_started_with_the_web/HTML_basics
HTMLの基本
HTML (HyperText Markup Language)は、Webページの構造を記述するための言語です。例えば、コンテンツは段落、箇条書きのリスト、画像の使用、データテーブルなどの組み合わせで構成されています。
HTML は一連の 要素 で構成されており、これらの要素がコンテンツのさまざまな部分を囲み、一定の表示や動作をさせることができます。タグで囲むと、単語や画像をどこかにハイパーリンクさせたり、単語を斜体にしたり、フォントを大きくしたり小さくしたりすることができます。 例えば、次のようなコンテンツがあるとします。
My cat is very grumpy
行を独立させたい場合は、段落タグで囲んで段落であることを指定することができます。
<p>My cat is very grumpy</p>
HTML 要素の中身
この段落要素についてもう少し詳しく見ていきましょう。

要素は主に以下のようなもので構成されています。
- 開始タグ (opening tag): これは、要素の名前(この場合は p)を山括弧で囲んだものです。どこから要素が始まっているのか、どこから効果が始まるのかを表します。 — 今回の場合どこから段落が始まるかを表しています。
- 終了タグ (closing tag): これは、要素名の前にスラッシュが入っていることを除いて開始タグと同じです。どこで要素が終わるのかを表しています。 — この場合は、段落が終わる場所を表します。終了タグの書き忘れは、初心者のよくある間違いで、おかしな結果になることがあります。
- コンテンツ (content): 要素の内容です。今回の場合はただのテキストです。
- 要素 (element): 開始タグ、終了タグ、コンテンツで要素を構成します。
要素には属性 (attribute) を設定することができます。このような感じです。

属性には、実際のコンテンツには表示させたくない、要素に関する追加情報が含まれています。ここでは、 class が属性の名前で、 editor-note が属性の値です。 class 属性では、要素に一意ではない識別子を与えることができ、それを使って要素(および同じ class 値を持つ他の要素)にスタイル情報などのターゲットを設定することができます。
一部の属性、たとえば required には値がありません。
値を設定する属性は常に次のような形式になります。
- 要素名(すでにいくつか属性がある場合はひとつ前の属性)との間の空白
- 属性名とそれに続く等号
- 引用符で囲まれた属性の値
Note ASCII のホワイトスペース(または
"'`=<>のいずれかの文字)を含まない単純な属性値は引用符を省略することができますが、コードを一貫性のあるものにし、理解を容易にするため、すべての属性値を引用符で囲むことをお勧めします。
要素の入れ子
要素の中に他の要素を入れることもできます。これをネスト(または入れ子)と言います。もしあなたの猫が「とっても」機嫌が悪いことを表したいとしたら、「とっても」という単語を <strong> 要素に入れて、単語の強調を表すことができます。
<p>My cat is <strong>very</strong> grumpy.</p>
しかしながら要素は正しく入れ子にしなければなりません。上記の例では、まず始めに <p> 要素が開始され、その次に <strong> 要素が開始されています。その場合は、必ず <strong> 要素、 <p> 要素の順で終了しなければなりません。次の例は間違いです。
<p>My cat is <strong>very grumpy.</p></strong>
要素は確実に他の要素の中もしくは外で開始し、終了する必要があります。上記の例のように要素が重複してしまうと、Webブラウザーは言おうとしていることを推測してもっとも良いと思われる解釈をするため、予期せぬ結果になることがあります。そうならないよう気を付けましょう!
空要素
コンテンツを持たない要素もあります。そのような要素を 空要素 (void element) と呼びます。すでに HTML ページにある <img> 要素を例に見ていきましょう。
<img src="images/firefox-icon.png" alt="テスト画像" />
この要素は 2 つの属性を持っていますが、終了タグ </img> がありませんし、内部にコンテンツもありません。これは画像要素は、その機能を果たすためにコンテンツを囲むものではないからです。画像要素の目的は、画像を HTML ページの表示させたいところに埋め込むことです。
HTML 文書の構造
ここまでは HTML 要素について見てきましたが、しかし、要素単体ではあまり役には立ちません。ここからはどのようにしてそれぞれの要素を組み合わせ、 HTML ページ全体を作っていくのかを勉強していきましょう。ファイルの扱いで出てきた index.html に書いてあるコードをもう一度見てみましょう。
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<title>テストページ</title>
</head>
<body>
<img src="images/firefox-icon.png" alt="テスト画像" />
</body>
</html>
この中にあるものは以下の通りです。
<!DOCTYPE html>— 文書型宣言です。これは必須の前置きです。昔々、 HTML がまだ出来たばかりの頃(1991 ~ 2 年)、文書型宣言は HTML ページが正しい HTML と見なされるために従わなければならない、一連のルールへのリンクとして機能することを意味していました。つまり、自動エラーチェックなどの有益なものを表すことができました。しかし、最近ではあまり機能しておらず、文書が正しく動作するために必要なだけです。今はこれだけ知っていれば大丈夫です。<html></html>— <html> 要素です。この要素は、このページのすべてのコンテンツを囲み、ルート要素と呼ばれることもあります。ここでは文書の主要な言語を設定するlang属性も指定します。<head></head>— <head> 要素です。この要素は、ページの閲覧者に向けて表示するためのコンテンツではない、 HTML ページに含めたいものをすべて収めるための入れ物です。検索エンジン向けの キーワード やページのディスクリプション(説明書き)、ページの見た目を変更するための CSS、文字コードの宣言などを含みます。<meta charset="utf-8">— この要素は、大部分の書き言葉の文字のほとんどを含む UTF-8 を文書で使用するように設定しています。基本的には、文書はどんなテキストコンテンツでも扱えるようになります。これを設定しない理由はありませんし、後でいくつかの問題を回避するのに役立ちます。<title></title>— <title> 要素です。ページのタイトルを指定しています。このタイトルはページが読み込まれた時にブラウザーのタブに表示されます。また、ブックマークやお気に入りに登録した時の説明にも使われます。<meta name="viewport" content="width=device-width">— このビューポート属性は、このページがある幅のビューポートで描画されることを保証し、モバイルブラウザーがビューポートより広い幅でページを描画した上で縮小して表示するのを防止します。<body></body>— <body> 要素です。これには、テキスト、画像、ビデオ、ゲーム、再生可能な音声トラックなど、ページを訪れたWebの利用者に表示したいすべてのコンテンツが含まれます。
画像
もう一度 <img> 要素について見ていくことにしましょう。
<img src="images/firefox-icon.png" alt="テスト画像" />
前に説明したように、ページのこれが現れたところに画像を埋め込みます。画像ファイルのパスを値に持つ src (source) 属性を指定することによってその画像を表示できます。
また、 alt (alternative; 代替) 属性も指定しています。 alt 属性は、以下のような理由で画像を見られない人に向けて説明するテキストを指定するものです。
- 目が不自由な人。著しく目の不自由な人はよくスクリーンリーダーと呼ばれるツールを使っていて、それが画像の
alt属性の内容を読み上げます。 - 何らかの理由で画像の表示に失敗した場合。例えば、
src属性の中のパスをわざと正しくないものに変更してみてください。ページを保存したり再読み込みしたりすると、画像の場所に下記のようなものが表示されるでしょう。

alt テキストのキーワードは「説明文」です。 alt テキストは、その画像が何を伝えているのかを読者が十分に理解できるような情報を提供する必要があります。この例では、現在のテキストである「テスト画像」は全く意味がありません。 Firefox のロゴであれば、「Firefox のロゴ: 地球の周りを燃えるような狐が囲んでいる。」の方がずっと良いでしょう。
画像に良い代替文字列を付けてみましょう。
Note アクセシビリティについて詳しくは MDN のアクセシビリティのページを参照してください。
テキストのマークアップ
この節では、文字列をマークアップするために使用する基本的な HTML 要素をいくつか見ていきます。
見出し
見出し要素により、コンテンツの特定の部分を見出し、または小見出しとして指定することができます。本にメインタイトル、章立て、サブタイトルがあるように、 HTML 文書にも見出しがあります。 HTML には <Heading_Elements“, “<h1> - <h6>> の 6 段階の見出しがありますが、よく使うのはせいぜい 3 から 4 まででしょう。
<!-- 4 段階の見出し -->
<h1>メインタイトル</h1>
<h2>最上位の見出し</h2>
<h3>小見出し</h3>
<h4>孫見出し</h4>
Note HTML の中で
<!--と-->の間にあるものは、すべて HTML コメントです。ブラウザーは、コードを表示する際にコメントを無視します。つまり、コメントはページ上では表示されず、コードの中に表示されるだけです。 HTMLコメントは、コードやロジックに関する有用なメモを書き込むためのものです。
それでは、あなたの HTML の <img> 要素の上に適切なタイトルを付けてみましょう。
Note 見出しレベル 1 には、暗黙のスタイルがあることがわかりますね。テキストを大きくしたり、太くしたりするために見出し要素を使用しないでください。見出し要素はアクセシビリティや SEO などの理由で使用されているからです。段階を飛ばすことなく、意味のある見出しの並びをページ上に作るようにしてください。
段落
先に説明したように、 <p> 要素は段落を示しています。通常の文章を書くときにはこの要素を頻繁に使うことになるでしょう。
<p>This is a single paragraph</p>
サンプルテキストを (「Webサイトをどんな外見にするか」から持ってきてください) 1 つまたは複数の段落に入れ、 <img> 要素のすぐ下に配置してください。
リスト
Webのコンテンツの多くはリストであり、 HTML にはリストのための特別な要素があります。リストのマークアップは、常に 2 つ以上の要素で構成されています。最も一般的なリストの種類は、順序付きリストと順序なしリストです。
- 順序なしリストは、お買い物リストのようにアイテムの順番が特に関係ない時に使います。順序なしリストは <ul> 要素で囲みます。
- 順序付きリストは料理のレシピのようにアイテムの順番が関係ある時に使います。順序付きリストは <ol> 要素で囲みます。
リストの中に入るそれぞれのアイテムは <li> (list item) 要素の中に書きます。
例えば、次の段落の一部をリストにしたい場合、
<p>
At Mozilla, we're a global community of technologists, thinkers, and builders
working together…
</p>
以下のようにマークアップします。
<p>At Mozilla, we're a global community of</p>
<ul>
<li>technologists</li>
<li>thinkers</li>
<li>builders</li>
</ul>
<p>working together…</p>
ページに番号付きリストと番号なしリストを追加してみましょう。
リンク
リンクはとても重要です。これがWebをWebたらしめているものです。リンクを追加するには、シンプルな要素 <a> を使う必要があります。 a は “anchor” を省略したものです。段落中の文字をリンクにするには次の手順で行います。
-
リンクにしたい文字を選びます。今回は “Mozilla Manifesto” を選びました。
-
選んだ文字を <a> 要素で囲みます。
<a>Mozilla Manifesto</a> -
このように <a> 要素に
href属性を追加します。<a href="">Mozilla Manifesto</a>このリンクのリンク先になるWebアドレスを、この属性の値に書き込みます。
<a href="https://www.mozilla.org/en-US/about/manifesto/"> Mozilla Manifesto </a>
アドレスの先頭にある https:// や http:// の部分(プロトコルと言います)を書き忘れると、予期せぬ結果となってしまうかもしれません。リンクを作ったら、ちゃんとそれが遷移したいところに行ってくれるかを確かめましょう。
Note
hrefは属性名として変に思うかもしれません。覚えにくかったら、hrefは hypertext reference を表しているということを覚えておきましょう。
もしまだやってないのなら、ページにリンクを追加してみましょう。
まとめ
説明に沿ってやってきたら以下のようなページが出来上がっているかと思います (もちろん画像やテキストの内容はみなさんの自由です)。
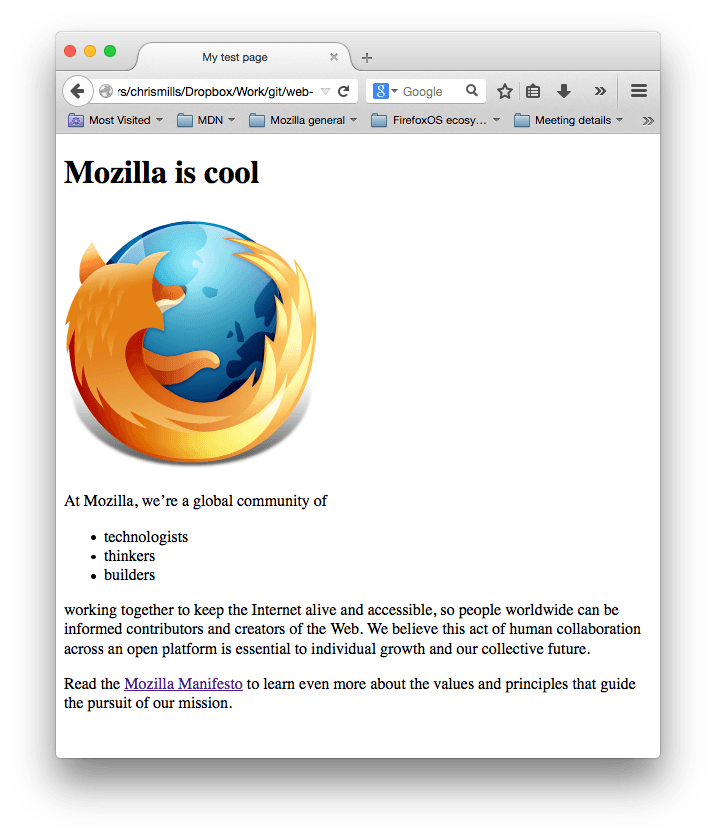
もし途中で行き詰まってしまったら、「サンプルコード」と見比べてみましょう。
― この文書は © 2023 MDN Web Docsプロジェクト協力者 クリエイティブ・コモンズ CC BY SA 2.5 ライセンスのもとに利用を許諾されています。 元の文書: https://developer.mozilla.org/ja/docs/Learn/Getting_started_with_the_web/CSS_basics
CSSの基本
CSS (Cascading Style Sheets) は、Webページのスタイルを設定するコードです。ここでは、始めるのに必要なものを紹介します。ここでは、テキストを赤くするにはどうすればいいのか?コンテンツを(Webページの)レイアウトの中で特定の場所に表示するにはどうすればいいのか?背景画像と色を使って Webページをどのように飾るのか?というような疑問に答えていきます。
例えば、この CSS は段落のテキストを選択し、色を赤に設定しています。
p {
color: red;
}
それでは試してみましょう。テキストエディターを使用して、(上記の) 3 行の CSS 新しいファイルに貼り付けてください。そのファイルを style.css として styles という名前のディレクトリーに保存してください。
コードを働かせるには、この(上記の) CSS を HTML 文書に適用する必要があります。そうしないと、このスタイルはブラウザーの HTML 文書の表示に影響しません。
-
index.htmlファイルを開き、先頭(<head> タグと</head>タグの間)に以下の行を貼り付けてください。<link href="styles/style.css" rel="stylesheet" /> -
index.htmlを保存し、ブラウザーで読み込んでください。次のように表示されるはずです。
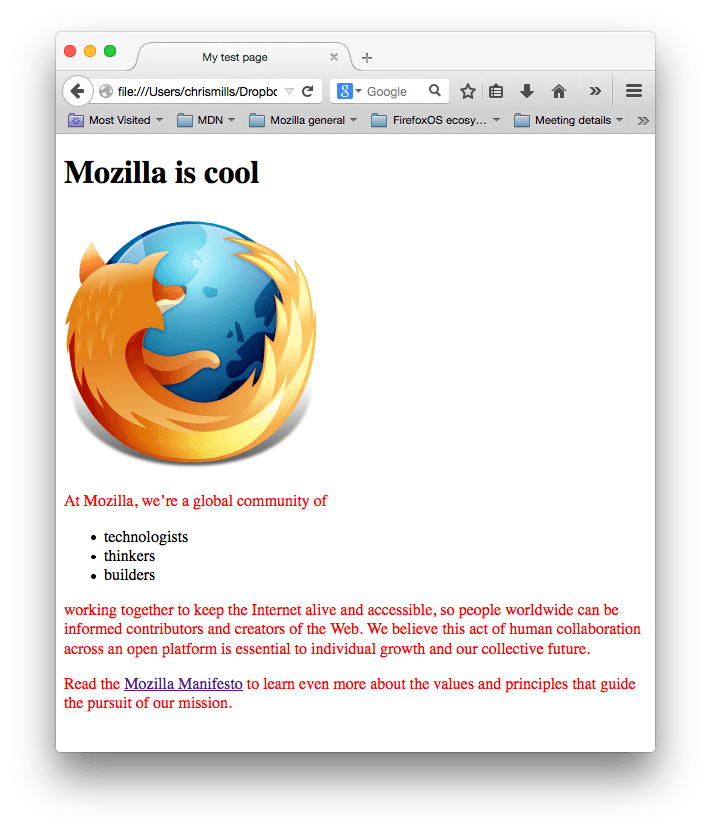
段落のテキストが赤くなっていれば、おめでとう! CSS が動作しています。
CSS ルールセットの構造
赤い段落テキストの CSS コードを分解して、その仕組みを理解してみましょう。
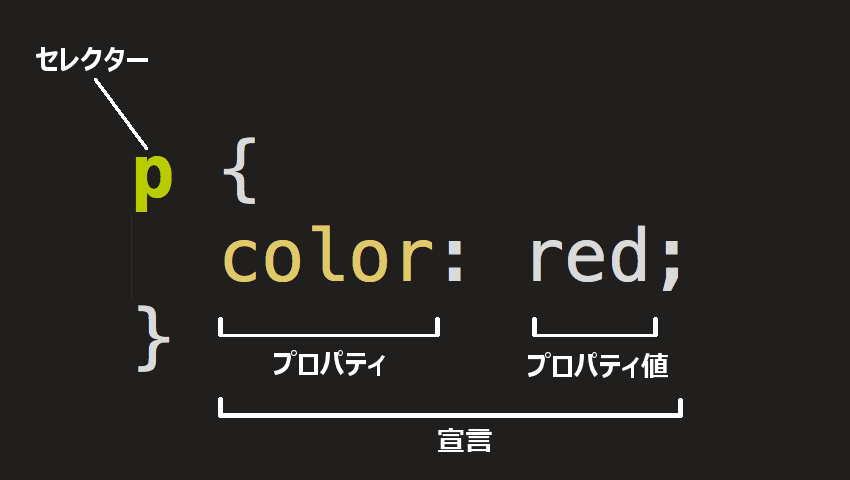
全体の構造はルールセットと呼びます (ルールセットという語はよく、単にルールとも呼ばれます)。それぞれの部分の名前にも注意してください。
- セレクター (Selector)
- : これはルールセットの先頭にある HTML 要素名です。これはスタイルを設定する要素 (この例の場合は <p> 要素) を定義します。別の要素をスタイル付けするには、セレクターを変更してください。
- 宣言 (Declaration)
- :
color: red;のような単一のルールです。これは要素のプロパティのうち、スタイル付けしたいものを指定します。
- :
- プロパティ (Property)
- : これらは、 HTML 要素をスタイル付けするための方法です。 (この例では、
colorは <p> 要素のプロパティです。) CSS では、ルールの中で影響を与えたいプロパティを選択します。
- : これらは、 HTML 要素をスタイル付けするための方法です。 (この例では、
- プロパティ値 (Property value)
- : プロパティの右側には—コロンの後に—プロパティ値があります。与えられたプロパティの多くの外観から 1 つを選択します。 (例えば、
colorの値はred以外にもたくさんあります。)
- : プロパティの右側には—コロンの後に—プロパティ値があります。与えられたプロパティの多くの外観から 1 つを選択します。 (例えば、
構文の他の重要な部分に注意してください。
- セレクターを除き、それぞれのルールセットは中括弧 (
{}) で囲む必要があります。 - それぞれの宣言内では、コロン (
:) を使用してプロパティと値を分離する必要があります。 - それぞれのルールセット内でセミコロン (
;) を使用して、それぞれの宣言と次のルールを区切る必要があります。
一つのルールセットで複数のプロパティ値を変更するには、次のようにセミコロンで区切って書いてください。
p {
color: red;
width: 500px;
border: 1px solid black;
}
複数の要素の選択
複数の要素を選択して、そのすべてに一つのルールセットを適用することもできます。複数のセレクターはカンマで区切ります。たとえば、以下のようになります。
p,
li,
h1 {
color: red;
}
さまざまな種類のセレクター
セレクターにはさまざまな種類があります。上記の例では、要素セレクターを使用しており、特定の種類の要素をすべて選択しています。しかし、もっと特定の要素を選択することもできます。ここでは、より一般的なセレクターの種類を紹介します。
| セレクター名 | 選択するもの | 例 |
|---|---|---|
| 要素セレクター(タグまたは型セレクターと呼ばれることもあります) | 指定された型のすべての HTML 要素。 | p<p> を選択 |
| ID セレクター | 指定された ID を持つページ上の要素です。指定された HTML ページでは、各 id 値は一意でなければなりません。 |
#my-id<p id="my-id"> または
<a id="my-id"> を選択
|
| クラスセレクター | 指定されたクラスを持つページ上の要素です。同じクラスの複数のインスタンスが 1 つのページに現れることがあります。 |
.my-class<p class="my-class"> および
<a class="my-class"> を選択
|
| 属性セレクター | 指定された属性を持つページ上の要素です。 |
img[src]<img src="myimage.png"> は選択するが
<img> は選択しない
|
| 擬似クラスセレクター | 指定された要素が指定された状態にあるとき。(例えば、マウスポインターが上に乗っている(ホバー)状態。) |
a:hover<a> を、マウスポインターがリンク上にあるときのみ選択。
|
他にも様々なセレクターがあります。詳しくは、 MDN のセレクターガイドをご覧ください。
フォントとテキスト
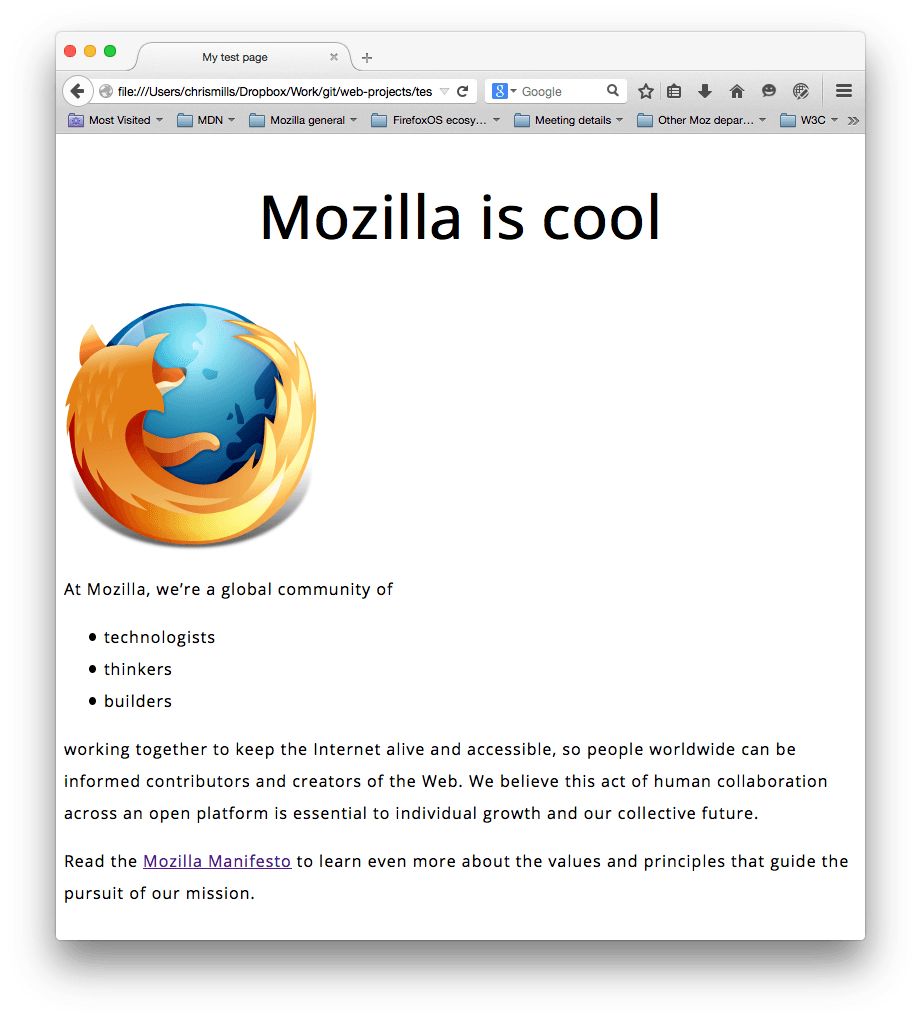
CSS の基本をいくつか勉強しましたので、style.css ファイルにいくつかのルールと情報を追加して、この例を見栄え良くしましょう。
HTML 本文内にテキストを配置する要素 (<h1>, <li>, <p>) のフォントの大きさを設定します。また、見出しを中央揃えにします。最後に、 2 つ目のルールセット (下記) を展開して、行の高さや文字の間隔などの設定を行い、本文のコンテンツを読みやすくしましょう。
h1 {
font-size: 60px; /* px は「ピクセル」 (pixels) の意味。60 ピクセルの高さのフォントになります */
text-align: center;
}
p,
li {
font-size: 16px;
line-height: 2;
letter-spacing: 1px;
}
px の値はお好みで調整してください。進行中の作品は、このようになるはずです。
CSS: ボックスのすべて
CSS を書いていて気づくことがあります。それは、その多くがボックスに関するものだということです。これには、サイズ、色、位置の設定が含まれます。ページ上のほとんどの HTML 要素は、他の箱の上に置かれた箱と考えることができます。

Photo from https://www.geograph.org.uk/photo/3418115 Copyright © Jim Barton cc-by-sa/2.0
CSS のレイアウトは、主にボックスモデルに基づいています。ページ上のスペースを占める各ボックスには、次のようなプロパティがあります。
padding: コンテンツの周囲のスペースです。以下の例では、段落テキストの周りのスペースです。border:paddingのすぐ外側にある実線margin: 要素の外側の周りの空間

この節では次のものを使用します。
width(要素の幅)background-color: 要素の内容と padding の背後にある色color: 要素のコンテンツ (通常はテキスト) の色text-shadow: 要素内のテキストに影を設定しますdisplay: 要素の表示モードを設定します (これについてはまだ心配しないでください)
続けて、さらに CSS を追加していきましょう。 style.css の一番下に、これらの新しいルールを追加し続けます。値を変えてどうなるか実験してみましょう。
ページの色を変更する
html {
background-color: #00539f;
}
このルールはページ全体の背景色に設定を行います。上記のカラーコードを、Webサイトをどんな外見にするかで選んだ色に変更しましょう。
本文のスタイル付け
body {
width: 600px;
margin: 0 auto;
background-color: #ff9500;
padding: 0 20px 20px 20px;
border: 5px solid black;
}
次は <body> 要素です。ここにはいくつかの宣言がありますので、 1 行ずつ見て行きましょう。
width: 600px;— これにより body は常に 600 ピクセルの幅になります。margin: 0 auto;—marginやpaddingなどのプロパティに 2 つの値を設定すると、最初の値は要素の上下の辺に影響します(この場合は0になります)。2 番目の値は左右に影響します(ここでautoは残った水平方向の余白を左右に均等に配分する特別な値です)。 margin の構文で説明しているように、 1 つ、2 つ、3 つ、4 つの値を使用することもできます。background-color: #FF9500;— これは要素の背景色を設定します。このプロジェクトでは body の背景色に明るいオレンジ色を使用して、 <html> 要素の暗い青とは対照的にしました。(気軽に試してみてください。)padding: 0 20px 20px 20px;— これはパディングに 4 つの値を設定します。これは、コンテンツの周りに少しのスペースを確保するためです。今回は body の上にパディングを設定せず、左・下・右に 20 ピクセルを設定します。値は上・右・下・左の順に設定されます。marginと同様、 padding の構文で説明されているように、 1 つ、 2 つ、または 3 つの値を使用することもできます。border: 5px solid black;— これは境界の太さ、スタイル、色の値を設定します。この場合は、 body の全側面に 5 ピクセルの太さの黒ベタの境界線を設定します。
メインページのタイトルの配置とスタイル付け
h1 {
margin: 0;
padding: 20px 0;
color: #00539f;
text-shadow: 3px 3px 1px black;
}
body の上部にひどい隙間があることに気づいたかもしれません。これは CSS をまったく適用していなくても、ブラウザーが(他のものの中で) <Heading_Elements“, “h1> 要素に既定のスタイルを適用するためです。それは悪い考えのように見えるかもしれませんが、スタイルのないページにも一定の読みやすさを求めるためのものです。隙間をなくすために、 margin: 0; を設定して既定のスタイルを上書きします。
次に見出しの上下のパディングを 20 ピクセルに設定します。
続いて、見出しテキストが HTML の背景色と同じ色になるように設定します。
最後に、 text-shadow は要素のテキストコンテンツに影を適用します。 4 つの値は次のとおりです。
- 最初はピクセル値で、影のテキストからの水平オフセット、どれだけ横に移動するかを設定します。
- 2 番目はピクセル値で、影のテキストから垂直オフセット、どれだけ下に移動するかを設定します。
- 3 番目のピクセル値で、影をぼかす半径を設定します。値が大きいほどぼやけた影を生成します。
- 4 番目の値は、影の基本色を設定します。
いろいろな値を試して、表示方法の変化を確認してみてください。
画像のセンタリング
img {
display: block;
margin: 0 auto;
}
次に、画像を中央に配置して見栄えを良くします。本文のときと同じように、 margin: 0 auto のトリックを使うこともできます。しかし、 CSS を機能させるために追加の設定が必要になる違いがあります。
<body> はブロック要素であるため、ページの中でスペースを占めます。ブロック要素は、マージンやその他の余白を開ける値を適用することができます。一方、画像はインライン要素です。インライン要素にマージンやその他の余白を開ける値を適用することはできません。画像にマージンを適用するには、display: block; を使用して画像にブロックレベルの動作を指定する必要があります。
Note 上記の手順は、本体に設定されている幅 (600 ピクセル) よりも小さい画像を使用していることを前提としています。画像が大きい場合、それは本文をあふれ、ページの残りの部分にはみ出します。これを修正するには、1) 画像編集ソフトを使用して画像の幅を縮小するか、2) CSS を使用して、
widthプロパティでより小さな値を<img>要素に設定し、画像の大きさを変更します。
Note
display: block;や、ブロックレベル/インラインの区別がまだ理解できなくても心配しないでください。 CSS の勉強を続けていくうちに意味が分かってくるはずです。さまざまな display の値の違いについて詳しくは、 MDN の display のリファレンスページを参照してください。
まとめ
完成すると次のようなページが表示されます。
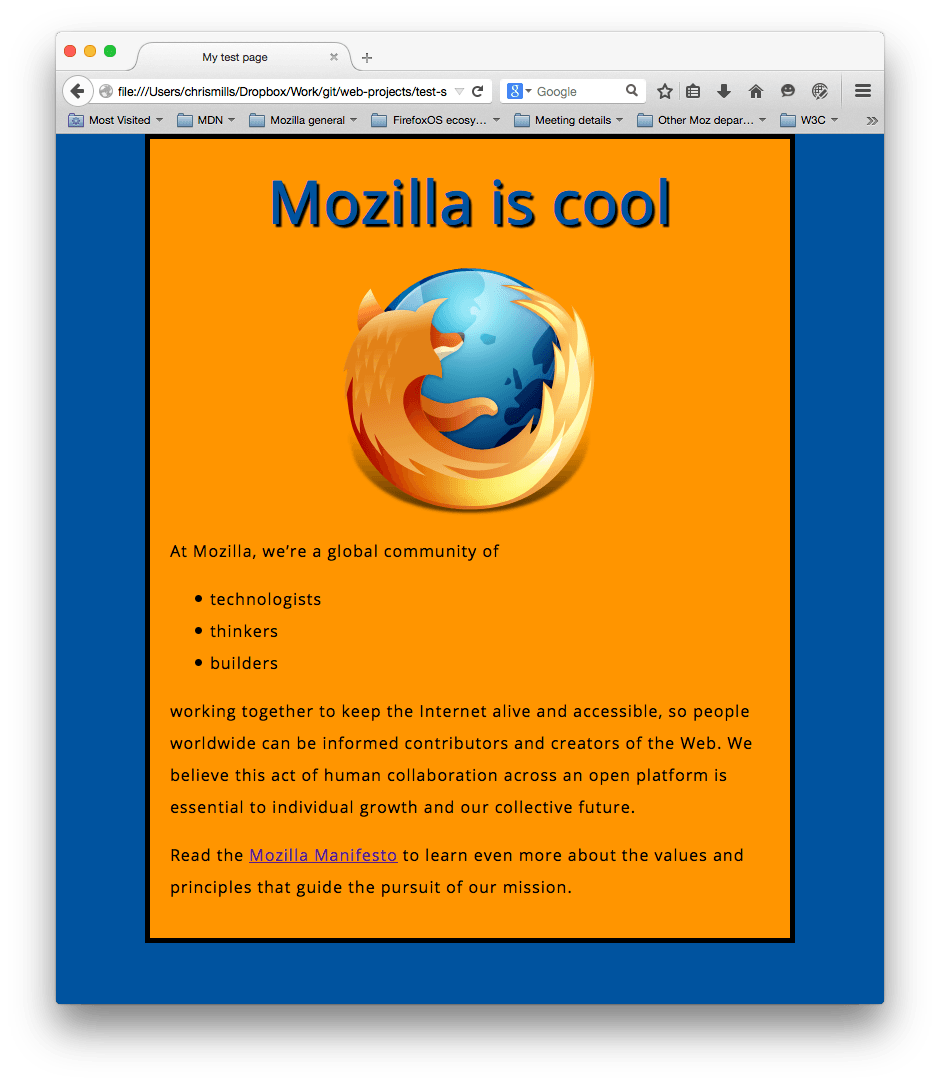
もし途中で行き詰まってしまったら、「サンプルコード」と見比べてみましょう。
― この文書は © 2023 MDN Web Docsプロジェクト協力者 クリエイティブ・コモンズ CC BY SA 2.5 ライセンスのもとに利用を許諾されています。 元の文書: https://developer.mozilla.org/ja/docs/Learn/Getting_started_with_the_web/JavaScript_basics
JavaScriptの基本
JavaScriptは世界で最も普及しているプログラミング言語です1。
JavaScriptは強力なプログラミング言語であり、Webサイトに対話操作を追加することができます。 ブレンダン・アイク (Brendan Eich) によって考案されました。
JavaScript は汎用性が高く、初心者にもやさしいものです。経験を積めば、ゲーム、 2D や 3D のアニメーション、包括的なデータベース駆動型のアプリなどが作れるようになります。
JavaScript は比較的コンパクトですが、一方でとても柔軟性があります。開発者は JavaScript 言語のコアをベースに多種多様なツールを作成し、最小限の労力で膨大な様々な機能を利用できるようにしました。例えば以下のようなものがあります。
- ブラウザーのアプリケーションプログラミングインターフェイス (API)。Webブラウザーに組み込まれた API により、動的な HTML の作成、 CSS スタイルの設定、ユーザーのWebカメラからの動画ストリームの収集や操作、三次元グラフィックや音声サンプルの生成などの機能を提供します。
- 開発者が他のコンテンツプロバイダーのサイト(Twitter や Facebook など)から機能を組み込むことを可能にする、サードパーティの API。
- すばやくサイトやアプリケーションを構築することができ、 HTML に組み込み可能なサードパーティのフレームワークやライブラリー。
コアの JavaScript 言語が上記のツールとどのように違うのか、その詳細を紹介することは、 JavaScript の軽い入門者向けの書籍であるこの記事の範囲外です。詳細は MDN の JavaScript 学習領域や、 MDN の他の部分で詳しく学ぶことができます。
以下では、コア言語のいくつかの側面について紹介します。またブラウザーの API 機能についてもいくつか説明します。楽しみましょう!
“Hello world!” の例
JavaScript は、最も人気のある現代のWeb技術のひとつです。 JavaScript のスキルが上がれば、Webサイトのパワーと創造性は新たな次元に入るでしょう。
しかし、 JavaScript を使いこなせるようになるのは HTML や CSS よりも少し難しいです。小さなものから始め、小さく確実な手順で作業を続ける必要があるかもしれません。始めるにあたって、“hello world!” を表示する例(基本的なプログラミング例の標準)を作りながら、基本的な JavaScript をページに追加する方法を紹介しましょう。
-
最初にテストサイトに行き、
scriptsという名前の新しいフォルダーを作成してください。それから、この scripts フォルダーの中にmain.jsという新しいファイルを作成して保存してください。 -
index.htmlファイルの</body>終了タグの直前に新しい行で、以下の新しい要素を追加してください。<script src="scripts/main.js"></script> -
これは CSS の <link> 要素の時の作業と基本的に同じです。これは JavaScript をページに適用するので、(CSS の時と同じく、ページ上の何に対しても) HTML に影響を与えることができます。
-
main.jsファイルに次のコードを追加してください。const myHeading = document.querySelector("h1"); myHeading.textContent = "Hello world!"; -
最後に、 HTML と JavaScript を書いたファイルを保存したことを確認し、ブラウザーで
index.htmlを読み込んでください。

Note 上記の説明で
<script>要素を HTML ファイルの末尾付近に置いたのは、ブラウザーがファイルに現れる順番でコードを読み込むからです。JavaScript が先に読み込まれ、まだ読み込まれていない HTML に影響を与えることになると、問題が生じる可能性があります。 JavaScript を HTML ページの下部に配置することは、この依存関係に対応する一つの方法です。その他の方法については、スクリプトの読み込み方針をご覧ください。
何が起きたのか
JavaScript を使用して、見出しの文字列が Hello world! に変更されました。最初に document.querySelector() 関数を使用して見出しを選択し、 myHeading と呼ばれる変数に格納しています。これは CSS のセレクターを使用するのととてもよく似ています。要素に対して何かをしたくなったら、まずその要素を選択する必要があります。
その後、 myHeading 変数の textContent プロパティ(見出しの内容を表す)の値を Hello world! に設定します。
Note 上の例で使用した機能はどちらもドキュメントオブジェクトモデル (DOM) API の一部であり、これを使って文書を操作することができます。
言語の短期集中コース
どのように動作するかをよりよく理解できるように、 JavaScript 言語の基本機能のいくつかを説明しましょう。これらの機能はすべてのプログラミング言語に共通しているので、これらの基本をマスターすれば、ほとんど何でもプログラムできるようになります!
Note この記事では、 JavaScript コンソールにサンプルコードを入力して、何が起こるのかを確認してみます。 JavaScript コンソールの詳細については、開発者ツールに慣れる (Firefoxの場合は ブラウザー開発ツールを探る)を参照しましょう。
変数
変数は、値を格納できる入れ物です。まず、 let というキーワードと、その後に任意の名前を指定することで、変数を宣言します。
let myVariable;
Note 行末のセミコロンは文が終わる場所を示します。単一の行で複数の文を区切る場合には絶対に必要です。しかし、個々の文の末尾に置くことが良い習慣だと信じている人もいます。使用する場面と使用しない場合については他のルールもあります。詳しくは Your Guide to Semicolons in JavaScript を参照してください。
Note 変数にはほとんど何でも名前を付けることができますが、いくらかの制約があります(変数の命名規則についてはこの記事を参照してください)。自信がない場合は、有効かどうか変数名を調べることができます。
Note JavaScript は大文字と小文字を区別します。
myVariableはmyvariableとは異なる変数です。コードで問題が発生している場合は、大文字・小文字をチェックしてください。
変数を宣言したら、以下のように値を割り当てることができます。
myVariable = "Bob";
好みに応じて、両方の操作を同一の行で行うことができます。
let myVariable = "Bob";
変数の値は、名前で呼び出すだけで取得することができます。
myVariable;
変数に値を代入した後で、変更することもできます。
let myVariable = "Bob";
myVariable = "Steve";
なお、変数は様々なデータ型の値を保持することもできます。
| 変数 | 説明 | 例 |
|---|---|---|
| 文字列 | 一連のテキストで、文字列と呼ばれます。値が文字列であることを示すには、単一引用符または二重引用符で囲む必要があります。 | let myVariable = 'Bob'; または let myVariable = "Bob"; |
| 数値 | 数値です。数値は引用符で囲みません。 | let myVariable = 10; |
| 論理型 |
論理値です。これは真か偽かの値です。 true と false は特別なキーワードで、引用符は必要ありません。
|
let myVariable = true; |
| 配列 | 単一の参照で複数の値を格納できる構造です。 |
let myVariable = [1,'Bob','Steve',10];配列の各メンバーは次のように参照します。 myVariable[0],
myVariable[1], など。
|
| オブジェクト | 基本的には何でも格納できます。 JavaScript のすべてがオブジェクトであり、変数に格納することができます。学ぶ際にはこれを覚えておいてください。 |
let myVariable = document.querySelector('h1');上記のすべての例も同様です。 |
ではなぜ変数が必要なのでしょうか。何か面白いプログラミングをするには変数が必要です。値が変更できなければ、挨拶のメッセージをパーソナライズしたり、画像ギャラリーに表示されている画像を変更するなどの動的な操作ができないのです。
コメント
コメントは、ブラウザーから無視される、コードの間に入れられた短いテキストスニペットです。CSS と同じように、JavaScript のコードではコメントを付けることができます。
/*
挟まれているすべてがコメントです。
*/
コメントに改行が含まれていない場合、次のように 2 つのスラッシュの後ろに記載する方が簡単です。
// これはコメントです
演算子
演算子は、2 つの値 (または変数) に基づいて結果を生成する数学的な記号です。次の表では、JavaScript コンソールで試してみるいくつかの例とともに、最も単純な演算子をいくつか見ることができます。
| 演算子 | 説明 | 記号 | 例 |
|---|---|---|---|
| 加算 | 2 つの数値を足し合わせたり、 2 つの文字列を結合したりします。 | + |
6 + 9;
|
| 減算、乗算、除算 | 基本的な数学の計算を実施します。 | -, *, / |
9 - 3;
|
| 代入 | すでに出てきました。変数に値を割り当てます。 | = |
let myVariable = 'Bob'; |
| 厳密等価 |
これは、2 つの値が等しく、かつデータ型が同じであるかどうかを調べます。
true/false (論理値)の結果を返します。
|
=== |
let myVariable = 3;
|
| 否定、非等価 |
その後にあるものと論理的に反対の値を返します。たとえば true を false に換えます。等価演算子と一緒に使用されると、否定演算子は 2 つの値が等しくないかどうかを調べます。
|
!, !== |
「否定」の場合は次の通りです。基本の式が
「非等価」は異なる構文ですが、基本的に同じ結果になります。ここでは「
|
他にも演算子はもっとたくさんありますが、今のところはこれで十分です。全体の一覧については、式と演算子を参照してください。
Note データ型を混在させると、計算を実行するときに奇妙な結果になる可能性があるため、変数を正しく参照し、期待通りの結果を得るように注意してください。例えばコンソールに
'35' + '25'と入力してみてください。期待通りの結果にならないのはなぜでしょうか。引用符は数字を文字列に変換するので、数字を加算するのではなく、文字列を連結する結果になったのです。35 + 25を入力すれば、正しい結果が得られます。
条件分岐
条件分岐は、ある式が true を返すかどうかをテストし、その結果次第でそれぞれのコードを実行するコード構造です。条件分岐のよくある形は if...else 文です。例えば以下の通りです。
let iceCream = "チョコレート";
if (iceCream === "チョコレート") {
alert("やった!チョコレートアイス大好き!");
} else {
alert("あれれ、でもチョコレートが好きなのに......");
}
if () の中の式が条件です。ここでは等価演算子を使用して、変数 iceCream とチョコレートという文字列を比較し、2 つが等しいかどうかを調べています。この比較が true を返した場合、コードの最初のブロックが実行されます。比較が真でない場合、最初のブロックはスキップされ、 else 文の後にある 2 番目のコードブロックが代わりに実行されます。
関数
関数は、再利用したい機能をパッケージ化する方法です。プロシージャが必要なときは、毎回コード全体を書くのではなく関数名を使って関数を呼び出すことができます。すでにいくつかの関数の仕様を見てきました。例えば次のようなものです。
let myVariable = document.querySelector("h1");
alert("hello!");
これらの関数、 document.querySelector と alert は、必要なときにいつでも使えるようブラウザーに組み込まれています。
もし変数名に見えるものがあったとしても、その後に括弧 () が付いていれば、おそらくそれは関数です。関数は普通、仕事をするのに必要な小さなデータである引数を取ります。引数は括弧の中に入れ、複数の引数がある場合はカンマで区切ります。
例えば、 alert() 関数はブラウザーのウィンドウにポップアップボックスを表示しますが、ポップアップボックスに何を書き込むかを関数に指示するために、文字列を引数として渡す必要があります。
嬉しいことに、自分で関数を定義することができます。次の例では、引数として 2 つの数値をとり、それらを乗算するという単純な関数を記載します。
function multiply(num1, num2) {
let result = num1 * num2;
return result;
}
上記の関数をコンソールで実行し、いくつかの引数を指定してテストしてみてください。例えば次のようなものです。
multiply(4, 7);
multiply(20, 20);
multiply(0.5, 3);
Note
return文はresultの値を関数内から関数の外に戻すことをブラウザーに指示し、それを利用できるようにします。これが必要な理由は、関数内で定義された変数が、その関数内でしか利用できないためです。これは変数のスコープと呼ばれています(変数のスコープのより詳しい説明をお読みください)。
イベント
Webサイトを本当にインタラクティブにするには、イベントが必要です。イベントは、ブラウザーの中で起きていることを検出し、その応答としてコードを実行するコード構造です。最も分かりやすい例は click イベントで、マウスで何かをクリックするとブラウザーによって発行されるものです。これを実行するには、コンソールに以下のように入力してから、現在のWebページ上をクリックしてください。
document.querySelector("html").addEventListener("click", function () {
alert("痛っ! つつかないで!");
});
要素にイベントハンドラーを取り付ける方法はいくつもあります。ここでは <html> 要素を選択しています。そして、addEventListener() 関数を呼び出し、待ち受けるイベントの名前 ('click') とイベントが発生したときに実行する関数を渡します。
先ほど addEventListener() に渡した関数は、名前を持たないので無名関数と呼ばれます。無名関数の書き方として、アロー関数と呼ばれるものがあります。アロー関数は () => を function () の代わりに使用します。
document.querySelector("html").addEventListener("click", () => {
alert("痛っ! つつかないで!");
});
Webサイトの例を膨らませる
さて、 JavaScript の基本のおさらいが終わったところで、例題のサイトに新しい機能を追加してみましょう。
先に進む前に、 main.js ファイルの現在の内容を削除して、空のファイルを保存してください。そうしないと、 “Hello world!” の例で使用した既存のコードが、これから追加する新しいコードと衝突してしまいます。
画像の切り替えの追加
このセクションでは、 DOM API 機能をもっと使用して、サイトに画像を追加しましょう。画像をクリックすると JavaScript を使用して 2 つの画像を切り替えることができます。
-
まずサイトに掲載したいと思う別な画像を見つけてください。最初の画像と同じサイズか、できるだけ近いものを使用してください。
-
この画像を
imagesフォルダーに保存してください。 -
この画像の名前を firefox2.png に変更してください。
-
main.jsファイルに次の JavaScript を入力してください。const myImage = document.querySelector("img"); myImage.onclick = () => { const mySrc = myImage.getAttribute("src"); if (mySrc === "images/firefox-icon.png") { myImage.setAttribute("src", "images/firefox2.png"); } else { myImage.setAttribute("src", "images/firefox-icon.png"); } }; -
index.htmlをブラウザーに読み込みます。画像をクリックすると、もう一方の画像に変わるでしょう。
何が起こったのでしょうか。<img> 要素への参照を変数 myImage に格納しました。次に、この変数の onclick イベントハンドラープロパティに、名前のない関数(「無名」関数)を代入しました。そうすれば、この要素がクリックされるたびに次の動きをします。
- 画像の
src属性の値を取得します。 - 条件分岐を使って、
srcの値が元の画像のパスと等しいかどうかをチェックします。- そうであれば、
srcの値を 2 番目の画像へのパスに変更し、もう一方の画像が強制的に <img> 要素の中に読み込まれるようにします。 - そうでない(すでに変更されている)場合、
srcの値を元の画像のパスに戻して、元の状態に戻ります。
- そうであれば、
パーソナライズされた挨拶メッセージの追加
次に、もう 1 つの小さなコードを追加し、ユーザーがサイトにアクセスしたときに、ページの表題をパーソナライズされた挨拶メッセージに変更してみましょう。この挨拶メッセージは、ユーザーがサイトを離れて後で戻った時にも保存されるようにします。Web Storage API を使用して保存しましょう。したがって、必要な時にいつでもユーザーと挨拶メッセージを変更できるオプションも用意しましょう。
-
index.htmlでは、 <script> 要素の直前に次の行を追加します。<button>ユーザーを変更</button> -
main.jsでは、次のコードを下記のとおりにファイルの最後に配置します。これは新しいボタンと見出しへの参照を変数に格納します。let myButton = document.querySelector("button"); let myHeading = document.querySelector("h1"); -
パーソナライズされた挨拶を設定する以下の関数を追加しましょう。まだ何も起こりませんが、すぐに修正します。
function setUserName() { const myName = prompt("あなたの名前を入力してください。"); localStorage.setItem("name", myName); myHeading.textContent = `Mozilla is Cool, ${myName}`; }setUserName()関数では、prompt()関数を使用して、alert()のようにダイアログボックスを表示しています。しかし、prompt()はalert()とは異なり、ユーザーにデータを入力するよう求め、ユーザーが OK を押した後に変数にそのデータを格納します。この場合、ユーザーに名前を入力するよう求めます。次に、localStorageと呼ばれる API を呼び出すことで、ブラウザーにデータを格納して後で受け取ることができます。 localStorage のsetItem()関数を使って、'name'と呼ばれるデータを作成し、myNameに入っているユーザーから入力されたデータを格納します。最後に、見出しのtextContentに文字列と新しく格納されたユーザーの名前を設定します。 -
以下のような条件ブロックを追加します。最初に読み込んだときにアプリを構造化するので、これを初期化コードと呼ぶこともできます。
if (!localStorage.getItem("name")) { setUserName(); } else { const storedName = localStorage.getItem("name"); myHeading.textContent = `Mozilla is Cool, ${storedName}`; }このブロックでは、最初に
nameのデータが存在しているかどうかをチェックするために否定演算子(!で表される論理否定)を使用しています。存在しない場合は、作成するためにsetUserName()関数が実行されます。存在する場合は(つまり、以前の訪問時にユーザーが設定した場合)、getItem()を使用して格納された名前を受け取り、setUserName()の中で行ったのと同様に、見出しのtextContentに文字列とユーザーの名前を設定します。 -
最後に、以下の
onclickイベントハンドラーをボタンに設定します。クリックすると、setUserName()関数が実行されます。これでユーザーがボタンを押すことで、好きな時に新しい名前を設定できるようになります。myButton.onclick = () => { setUserName(); };
ユーザー名か null か
この例を実行してユーザー名を入力するダイアログボックスが出たとき、キャンセルボタンを押してみてください。結果として “Mozilla is cool, null” というタイトルが表示されるでしょう。これはプロンプトをキャンセルしたときに、値が null、つまり値がないことを示す JavaScript の特殊な値に設定されるためです。
また何も入れずに OK を押してみてください。結果として “Mozilla is cool,” というタイトルが表示され、これは理由が明白です。
この問題を避けるには、ユーザーが null や空白の名前を入力していないかチェックするよう、setUserName() 関数を書き換えます。
function setUserName() {
const myName = prompt("あなたの名前を入力してください。");
if (!myName) {
setUserName();
} else {
localStorage.setItem("name", myName);
myHeading.textContent = `Mozilla is Cool, ${myName}`;
}
}
人間の言葉で言うと、 myName に値がない場合や、nullの場合、 最初から setUserName() を実行します。値がない場合(上記の式が真でない場合)には、localStorage に値を設定して、見出しのテキストにも設定します。
まとめ
最後までこの記事の手順に従った場合は、最終的に次のようなページが表示されているでしょう。
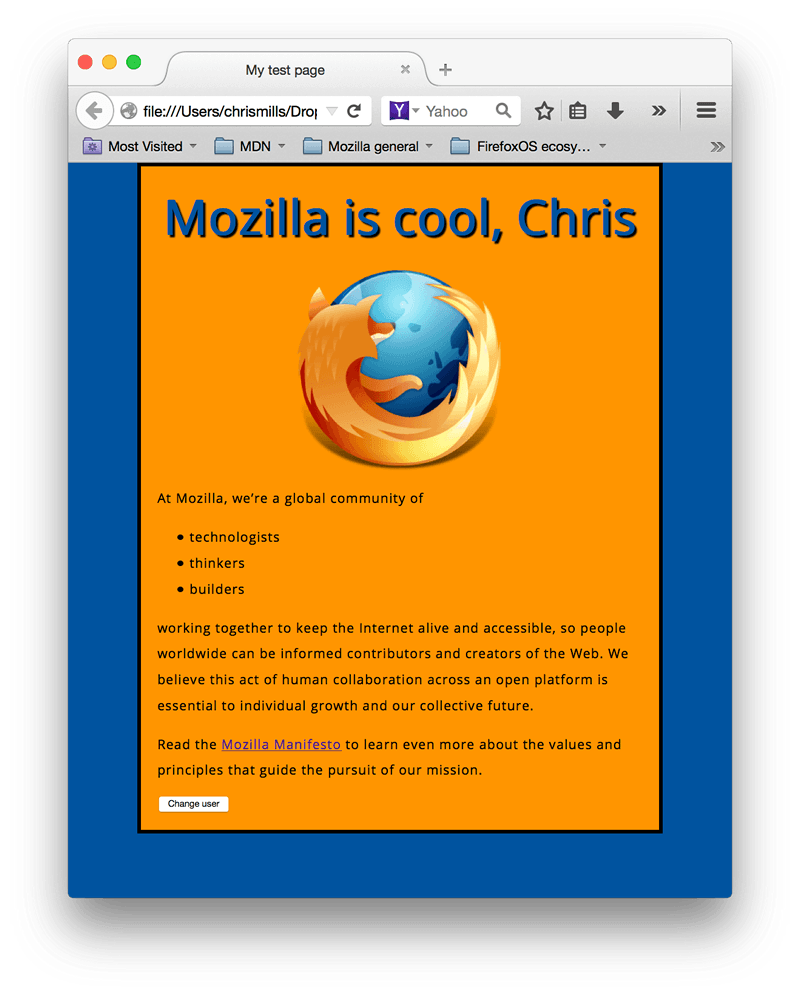
もし途中で行き詰まってしまったら、「サンプルコード」と見比べてみましょう。
Web開発研修
目的
フロントエンド (React) からバックエンド (Hono) まで、モダン Web 開発の全てのスキルを習得する実践研修プログラムです。REST API サーバの実装から UI 開発まで、現代の Web 開発に必要な技術スタックを体系的に学習します。
対象者
- JavaScript の基本構文を理解している方
- 実務でのモダンな Web フルスタック開発スキル習得を目指す方
研修の特徴
実際の Web アプリケーション開発に必要なフロントエンド・バックエンドの実装スキル習得を重視した実践的プログラム
フィードバック / 問い合わせ
学習中の質問・改善提案・教材の誤りなどは「質問・提案・問題の報告」をご覧ください。研修担当者やメンターに直接相談しても構いません。
Web開発環境構築
REST APIと非同期処理
Honoハンズオン
Hono + React 連携
SQLiteハンズオン
開発実践
Web開発環境構築
- モダンWebアーキテクチャ概要
- ローカル開発環境セットアップ
- miseによるツール管理
- VSCode入門
- Git・GitHub基礎
- React環境構築
- TypeScript導入
- Biomeによるコード品質管理
- AI支援ツール活用法
- 基本的な開発の流れ
モダンWebアーキテクチャ概要
現代のWebアプリケーション開発では、フロントエンド、バックエンド、インフラが連携しながらも、それぞれが独立した役割を担っています。モダンなWebアーキテクチャの全体像を把握し、実際の開発で使われているパターンや最新技術を一緒に学んでいきましょう。
フロントエンド、バックエンド、インフラの役割分担
フロントエンドの役割
フロントエンドは、ユーザーが直接触れる部分を担当します(まさにWebサイトの「顔」ですね)。
主な責務:
- ユーザーインターフェース(UI)の構築
- ユーザーエクスペリエンス(UX)の最適化
- データの表示・入力処理
- バックエンドとの通信
// Reactの例
import React, { useState, useEffect } from "react";
function UserProfile({ userId }) {
const [user, setUser] = useState(null);
useEffect(() => {
// バックエンドAPIからデータを取得
fetch(`/api/users/${userId}`)
.then((response) => response.json())
.then((userData) => setUser(userData));
}, [userId]);
return <div>{user ? <h1>Hello, {user.name}!</h1> : <p>Loading...</p>}</div>;
}
バックエンドの役割
バックエンドは、アプリケーションのロジックとデータ処理を担当します (頭脳のようなものです)。
主な責務:
- ビジネスロジックの実装
- データベースとの連携
- API(Application Programming Interface)の提供
- セキュリティ・認証の管理
// Node.js + Honoの例
import { Hono } from "hono";
const app = new Hono();
// ユーザー情報を取得するAPI
app.get("/api/users/:id", async (c) => {
try {
const user = await database.getUser(c.req.param("id"));
return c.json(user);
} catch (error) {
return c.json({ error: "User not found" }, 404);
}
});
インフラストラクチャの役割
インフラは、アプリケーションを動かすための基盤を提供します(筋肉・骨格のようなものです)。
主な責務:
- サーバーの管理・運用
- データベースの管理
- セキュリティ・監視
- スケーリング(負荷対応)
現代の代表的なアーキテクチャパターン
1. モノリシックアーキテクチャ
特徴: すべての機能が1つのアプリケーションに統合されている従来型のアーキテクチャです。
メリット:
- 開発・デプロイが簡単
- 小規模チームに適している
- トランザクション管理がしやすい
デメリット:
- 機能追加時の影響範囲が大きい
- 技術スタックの変更が困難
- スケーリングが非効率
モノリシックアプリのイメージ:
| アプリ |
|---|
| ユーザー管理 |
| 商品管理 |
| 注文処理 |
| 決済処理 |
2. マイクロサービスアーキテクチャ
特徴: 機能ごとに独立したサービスに分割し、API経由で連携するアーキテクチャです。
メリット:
- 各サービスを独立して開発・デプロイ可能
- 適切な技術スタックを選択可能
- 障害の影響を局所化できる
デメリット:
- システム全体の複雑性が増加
- サービス間通信のオーバーヘッド
- 分散システムの管理が必要
マイクロサービスのイメージ:
API Gatewayを介して各サービスが連携
| ユーザーサービス |
|---|
| ユーザー管理 |
| プロフィール管理 |
↑↓
| 商品サービス |
|---|
| 商品カタログ |
| 在庫管理 |
↑↓
| 注文サービス |
|---|
| 注文処理 |
↑↓
| 決済サービス |
|---|
| 決済処理 |
サーバーレス・エッジコンピューティングの最新技術動向
サーバーレスとは?
特徴: サーバー管理を不要にし、関数単位でコードを実行できるクラウドサービスの形態です。
メリット:
- サーバー管理が不要
- オートスケーリング
- 使用量に応じた料金体系
代表的なサービス:
- AWS Lambda
- Vercel Functions
- Cloudflare Workers
// Cloudflare Workers の例
export default {
async fetch(request) {
return new Response("Hello from Serverless!");
},
};
エッジコンピューティングとは?
エッジコンピューティングは、データ処理をユーザーに近い場所(エッジ)で行うサーバーレス技術です(まるでコンビニのように、身近な場所でサービスを提供するイメージです)。
なぜエッジコンピューティングが注目されているのか?
従来の課題:
- 中央サーバーまでの通信遅延
- 帯域幅の制限
- 単一障害点のリスク
エッジコンピューティングの解決策:
- レイテンシの削減: ユーザーに近い場所での処理
- 帯域幅の節約: 必要最小限のデータ転送
- 可用性の向上: 分散処理による障害耐性
実際の活用事例
1. CDN(Content Delivery Network)
// Cloudflare Workers の例
export default {
async fetch(request) {
const country = request.cf.country;
return new Response(`Hello from ${country}!`);
},
};
2. サーバーレス・エッジプラットフォーム
主要サービス:
| サービス | 特徴 | 主な用途 |
|---|---|---|
| Cloudflare Workers | V8エンジンベース、高速起動 | API、リダイレクト処理 |
| AWS Lambda@Edge | CloudFront統合 | 認証、A/Bテスト |
| Vercel Edge Functions | Next.js統合 | パーソナライゼーション |
実践例:地域別コンテンツ配信
// Vercel のサーバーレス関数(Edge Functions)の例
import { NextRequest, NextResponse } from "next/server";
export function middleware(request: NextRequest) {
const country = request.geo?.country || "US";
// 国別に異なるコンテンツを配信
const url = request.nextUrl.clone();
url.pathname = `/${country.toLowerCase()}${url.pathname}`;
return NextResponse.rewrite(url);
}
アーキテクチャ選択のトレードオフ
コンウェイの法則:組織とアーキテクチャの関係
コンウェイの法則(Conway’s Law)
「システムを設計する組織は、その組織のコミュニケーション構造をコピーした設計を生み出すように制約される」
— Melvin Conway, 1967
この法則が示唆することは明快です。アーキテクチャは技術的な選択である前に、組織的な選択であるということです。
なぜアーキテクチャと組織構造は一致するのか?
チーム間の調整コストがその答えです。
モノリシックな組織 → モノリシックなコード
├─ 全員が同じコードベースで作業
└─ 変更時は全員の調整が必要
分散した組織 → マイクロサービス
├─ 各チームが独立したサービスを所有
└─ API契約さえ守れば独立して開発可能
各アーキテクチャが前提とする組織構造
1. モノリシック:密なコミュニケーションが可能な小規模チーム
最適な組織:
- 1つのチーム(3-8人程度)
- 物理的に近い場所で作業
- 頻繁な対面コミュニケーション
なぜこの構造が必要か?
すべてのコードが1つのリポジトリにあり、変更の影響範囲が広いため、チームメンバー全員が全体を把握している必要があります。これは小規模チームでしか実現できません。
// 1つの変更が広範囲に影響
function updateUserProfile(userId, data) {
// ユーザー管理
const user = await db.users.update(userId, data);
// 通知システム(同じコードベース内)
await notificationService.send(user);
// メール送信(同じコードベース内)
await emailService.sendWelcome(user);
// 全ての機能が密結合している
}
2. マイクロサービス:自律的なチームが並行で動く大規模組織
最適な組織:
- 複数の独立したチーム(各3-8人)
- チームごとに異なる専門性・技術スタック
- 明確なAPI契約による非同期コミュニケーション
なぜこの構造が必要か?
サービス間の境界がチーム間の境界と一致することで、各チームは他チームへの依存を最小限に抑えながら開発できます。
+───────API──────+
| | |
[ユーザーサービス] [注文サービス] [決済サービス] … システム
| | |
[ユーザーチーム] [注文チーム] [決済チーム] … 組織
各チームは自分のサービスに責任を持ち、他のチームとはAPI経由でのみやり取りします。
技術特性の比較
| 特性 | モノリシック | マイクロサービス |
|---|---|---|
| 初期開発速度 | ⭐⭐⭐ | ⭐ |
| トランザクション管理 | 容易 | 困難 |
| チーム調整コスト | 高 | 低 |
| 障害の影響範囲 | 全体 | 局所的 |
逆コンウェイ戦略:アーキテクチャから組織を設計する
興味深いことに、この法則は逆方向にも適用できます。目指すアーキテクチャに合わせて組織構造を設計するという戦略です。
例:モノリスからマイクロサービスへの移行
Step 1: アーキテクチャの分割計画
├─ ユーザー管理サービス
├─ 商品管理サービス
└─ 注文管理サービス
Step 2: チーム構造の再編成
├─ ユーザーチーム(3名)
├─ 商品チーム(4名)
└─ 注文チーム(5名)
Step 3: 責任範囲の明確化
各チームが対応するサービスのエンドツーエンドを担当
(設計、開発、テスト、運用、監視)
この戦略により、組織構造とアーキテクチャが一致し、開発効率が向上します。
意思決定のフレームワーク
アーキテクチャを選択する際は、以下の質問に答えてみてください。
1. チームの現在の構造は?
- 全員が密にコミュニケーションできる → モノリシック or サーバーレス
- 複数の独立したチームがある → マイクロサービス
- 1-3人の小規模チーム → サーバーレス
2. 将来のチーム拡張計画は?
- 大きくしない(〜10人) → モノリシック or サーバーレス
- 複数チームに拡大予定 → マイクロサービスを検討
- 不確定 → サーバーレス(柔軟性が高い)
3. チーム間の調整コストをどう考えるか?
- 頻繁な調整が苦にならない → モノリシック
- 調整コストを最小化したい → マイクロサービス or サーバーレス
- インフラ管理を避けたい → サーバーレス
4. 既存の組織文化は?
- 密なコラボレーション文化 → モノリシック
- 自律的なチーム文化 → マイクロサービス
- スタートアップ的な柔軟性 → サーバーレス
失敗パターン:組織とアーキテクチャのミスマッチ
❌ 失敗パターン1:小規模チームでマイクロサービス
- 問題:3人チームが10個のサービスを管理
- 結果:サービス間の調整に時間を取られ、開発速度が低下
❌ 失敗パターン2:大規模組織でモノリシック
- 問題:20人が同じコードベースで作業
- 結果:変更の度に全員の調整が必要、デプロイが週1回に
❌ 失敗パターン3:インフラ知識がないままマイクロサービス
- 問題:Kubernetes、サービスメッシュ、分散トレーシングの運用負荷
- 結果:機能開発よりインフラ管理に時間を取られる
設計のポイント
- 組織構造とアーキテクチャを一致させる
- 無理に流行りのアーキテクチャを採用せず、チームの実態に合わせる
- 段階的に移行する
- 一気に変えず、モノリス→サーバーレス→マイクロサービスのように段階的に
- チームの自律性を最大化する
- 各チームが独立してデプロイできる粒度でサービスを分割する
- API契約を明確にする
- チーム間のコミュニケーションコストを減らすため、明確なインターフェースを定義
- 測定可能な指標を持つ
- デプロイ頻度
- リードタイム
- 変更失敗率
- 復旧時間(MTTR)
Note
アーキテクチャの選択は、技術的な最適解を求めることではなく、組織の現実と目標を反映したトレードオフの選択です。完璧なアーキテクチャは存在しません。あるのは、現在のチームと事業フェーズに最も適したアーキテクチャだけです。
2025年のトレンドと将来展望
- フルスタック フレームワークの進化
- Next.js 15、Nuxt 4 などの新機能
- App Router、Server Components の普及
- サーバーレス優先アーキテクチャ
- エッジでの動的レンダリング
- 最適化の自動化
- AI統合アーキテクチャ
- LLM API の活用
- リアルタイム AI処理
- 型安全性
- TypeScript の標準化
- エンドツーエンドの型安全性
注目のフレームワーク: Astro
---
// サーバーサイドで実行
const posts = await fetch('/api/posts').then(r => r.json())
---
<Layout>
<h1>My Blog</h1>
<!-- 静的HTML -->
<PostList posts={posts} />
<!-- 必要な部分のみ JavaScript -->
<SearchBox client:load />
</Layout>
https://docs.astro.build/ja/getting-started/
ポイント
🎯 重要なコンセプト
- フロントエンド: ユーザーインターフェースとユーザー体験を担当
- バックエンド: ビジネスロジックとデータ処理を担当
- インフラ: アプリケーションの実行基盤を提供
- サーバーレス: 運用負荷軽減、自動スケーリング、エッジでの実行が可能
- エッジコンピューティング: ユーザーに近い場所での処理により、速度と効率を向上
🏗️ アーキテクチャパターン
- モノリシック: シンプルだが拡張性に制限
- マイクロサービス: 高い柔軟性だが複雑性も増加
🚀 選択のポイント
- プロジェクト規模: チームサイズと要件の複雑さを考慮
- 技術的制約: 既存システムとの統合要件
- 運用リソース: 管理・保守の工数とスキル
- 将来の拡張性: ビジネス成長への対応力
💡 実践への第一歩
まずは小さなプロジェクトでサーバーレス関数を試してみることから始めましょう。理論だけでなく、実際に手を動かすことで、それぞれのアーキテクチャの特性を体感できるはずです。
現代のWeb開発は選択肢が豊富ですが(時には選択肢が多すぎて迷ってしまいますが)、基本的な役割分担と各パターンのトレードオフを理解していれば、適切な技術選択ができるようになります。一緒に頑張りましょう!
ローカル開発環境セットアップ
自分のパソコンでWeb開発を始めるために必要な環境の準備について一緒に学んでいきましょう。最初は設定することがたくさんあって大変に感じるかもしれませんが、一度セットアップしてしまえば快適に開発できるようになります。
学習目標
- Web開発に必要なツールの全体像を理解する
- どのパソコンでも同じように開発できる環境を構築する
- 効率的で使いやすい開発環境を作る
開発環境の全体像
基本的なツール構成
Web開発に必要なツールはいくつかあり、それぞれに役割があります。
必須ツール:
- エディタ: VS Code (推奨), Cursor, Zed(コードを書くためのソフト)
- ランタイム: Node.js (推奨), Deno, Bun
- バージョン管理: Git (推奨)
- ツール管理: mise (推奨), asdf, volta
- AI支援ツール: GitHub Copilot, Codex, Claude Code, Gemini CLI
推奨ツール:
- 仮想環境: WSL2 (Windows), Docker
- ターミナル: Windows Terminal, Warp, WezTerm, iTerm2
- シェル: Bash, Zsh, Fish
- ブラウザ: Chrome, Safari, Firefox
- HTTP クライアント: curl
OS別セットアップガイド
Windows (推奨: WSL2 使用)
- WSL2 セットアップ
# PowerShellで実行
wsl --set-default-version 2
wsl --install -d Ubuntu
# WSL2での作業推奨
wsl
- Windows Tools
# Windows Terminal (推奨)
winget install Microsoft.WindowsTerminal
# VS Code
winget install Microsoft.VisualStudioCode
# Git for Windows
winget install Git.Git
- WSL2内でのセットアップ
# Ubuntu/Debian内で実行
sudo apt update && sudo apt upgrade -y
sudo apt install curl build-essential git -y
macOS
- Homebrew インストール
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 基本ツール
# 開発ツール
xcode-select --install
# エディタとブラウザ
brew install --cask visual-studio-code
brew install --cask google-chrome
# ターミナル
brew install --cask wezterm # または iterm2
Linux (Ubuntu/Debian)
- システム更新とビルドツール
sudo apt update && sudo apt upgrade -y
sudo apt install curl build-essential git -y
- VS Code インストール
# 公式リポジトリから
curl -sSL https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
echo "deb [arch=amd64] https://packages.microsoft.com/repos/vscode stable main" | sudo tee /etc/apt/sources.list.d/vscode.list
sudo apt update
sudo apt install code
- Google Chrome インストール
# 公式リポジトリから
curl -sSL https://dl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list
sudo apt update
sudo apt install google-chrome-stable
コマンドライン操作
基本的なターミナル操作
# ナビゲーション
pwd # 現在のディレクトリを表示
ls -la # ファイル一覧(詳細表示)
ls -la | grep node # grep でフィルタリング
cd directory # ディレクトリ移動
cd - # 前のディレクトリに戻る
cd ~ # ホームディレクトリに移動
# ディレクトリ・ファイル操作
mkdir -p path/to/dir # 階層ディレクトリ作成
touch file.txt # 空ファイル作成
cp -r source dest # ディレクトリをコピー
mv old_name new_name # ファイル/ディレクトリ名変更
rm -rf directory # ディレクトリを強制削除
# ファイル内容操作
cat file.txt # ファイル全体表示
head -n 10 file.txt # 先頭10行表示
tail -n 10 file.txt # 末尾10行表示
grep "pattern" file.txt # パターン検索
find . -name "*.js" # ファイル検索
プロセス管理
# プロセス操作
ps aux # 全プロセス表示
pgrep node # Node.jsプロセスを検索
top # リアルタイムプロセス監視
kill pid # プロセスID指定で終了
pkill node # プロセス名で全て終了
# バックグラウンド実行
node --run dev & # バックグラウンドで実行
Ctrl+Z # プロセスを一時停止
jobs # ジョブ一覧
fg # フォアグラウンドに復帰
モダンシェル環境の構築
Git設定
# グローバル設定
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"
git config --global init.defaultBranch main
git config --global core.editor "code --wait"
# SSH キー生成
ssh-keygen -t ed25519 -C "your.email@example.com"
# SSH設定 (~/.ssh/config)
Host github.com
HostName github.com
User git
開発支援ツールのインストール
# mise経由でツールインストール
mise install node@lts
mise use --global node@lts
# グローバルパッケージ
npm i -g @biomejs/biome
環境確認とテスト
# 研修用ディレクトリに移動
mkdir -p web-dev-2025/test
cd test-environment
# mise.toml 作成
mise use node@lts
mise use pnpm@latest
# 動作確認
node -v
node -e 'console.log(process.version)'
# package.json 作成
pnpm init --init-type=module
# 依存関係インストール
pnpm add -D react react-dom typescript @types/react @types/react-dom
トラブルシューティング
Windows/WSL 環境で問題が起きた場合は「WSLトラブルシューティング」をご確認ください。
まとめ
開発環境構築のポイント
- 一貫性: mise によるツールバージョン管理
- 再現性: 設定ファイルによる環境の再現
- 効率性: ターミナル操作の習得と自動化
🔄 継続的改善
- 新しいツールの評価と導入
- チームでの共有
WSLトラブルシューティング
WSL (Windows Subsystem for Linux) 環境で Web 開発を行う際に遭遇しやすい問題と、その対処法をまとめています。
プロジェクトの作業ディレクトリについて
基本方針: プロジェクトは /home/ユーザー 以下に作成し、VS Code の Remote - WSL 拡張機能でアクセスすることを推奨します。
| パス | ファイルシステム | おすすめ度 |
|---|---|---|
/home/ユーザー | Linux (ext4) | ✅ 推奨 |
/mnt/c/Users/… | Windows (NTFS) | ⚠️ 非推奨 |
/mnt/c/ 以下は Windows のファイルシステムを WSL からマウントしたものです。ここで作業すると、ファイル監視やパフォーマンスの問題が発生しやすくなります(詳しくは後述)。
/mnt/c/ 以下でファイル監視が動かない
症状
/mnt/c/Users/… にあるプロジェクトで pnpm dev を実行すると、ファイルを編集しても開発用サーバーが自動で再起動しない(ホットリロードが効かない)ことがあります。
原因
/mnt/c/ は Windows のファイルシステム (NTFS) を WSL からマウントしたパスです。Linux のファイル変更検知の仕組み(inotify)が正しく動作しないため、tsx watch や Vite の HMR などがファイル変更を検出できません。
対処法
プロジェクトを /home/ 以下に移動する(推奨)
# プロジェクトを移動
cp -r /mnt/c/Users/yourname/projects/my-app ~/my-app
cd ~/my-app
pnpm install
pnpm dev
これが最も確実な解決方法です。/home/ 以下であれば Linux ネイティブのファイルシステム (ext4) が使われるため、ファイル監視が正常に動作します。
VS Code で /home/ 以下のファイルが開けない
症状
プロジェクトを /home/ に移動したものの、VS Code でファイルを開く方法がわからない、または Windows 側の VS Code から直接アクセスできない。
対処法
Remote - WSL 拡張機能を使う
VS Code の Remote - WSL 拡張機能をインストールすると、WSL 内のファイルを直接編集できるようになります。
- Windows 側の VS Code で拡張機能
ms-vscode-remote.remote-wslをインストール - WSL のターミナルからプロジェクトディレクトリに移動して
code .を実行
cd ~/my-app
code .
VS Code が WSL モードで開き、/home/ 以下のファイルをシームレスに編集できます。左下に「WSL: Ubuntu」のような表示が出ていれば正しく接続されています。
pnpm create hono など実行時に GitHub API エラーが出る
症状
pnpm create hono@latest を実行し、テンプレート選択後に以下のようなエラーが出る場合があります。
throw new Error(`Error running hook for ${templateName}: ${e instanceof Error ? e.message : e}`);
Error: Error running hook for nodejs: Failed to fetch https://api.github.com/repos/honojs/starter/tarball/v0.19
テンプレートの tarball を GitHub API からダウンロードする段階で失敗しています。
考えられる原因
- ネットワーク環境(プロキシ、ファイアウォール、VPN)が GitHub API へのアクセスをブロックしている
- プロキシ確認ガイド を参照
- Windows 側のバイナリが意図せず参照されている
- WSL の DNS 設定の問題
対処法
1. 環境情報の確認
まず、WSL 内で正しいバイナリが使われているか確認します。
# 各コマンドのパスを確認
which node
which pnpm
which git
which curl
/mnt/c/ から始まるパスが表示された場合、Windows 側のバイナリが参照されています。WSL 内にインストールされたツールが正常に使われるように設定してください(mise によるツール管理 を参照)。
2. GitHub API への接続テスト
curl -I https://api.github.com
ステータスコード 200 が返れば接続は正常です。エラーが出る場合はネットワーク環境を確認してください。(プロキシ確認ガイド を参照)。
3. テンプレートを手動で取得する
GitHub API 経由のダウンロードが失敗する場合でも、Web ブラウザーや git clone で直接取得できることがあります。
Hono のテンプレートの場合:
# git clone でテンプレートを取得
git clone https://github.com/honojs/starter.git
cp -r starter/templates/nodejs my-hono-app
cd my-hono-app
pnpm install
テンプレートの一覧は https://github.com/honojs/starter/tree/main/templates から確認できます。
Vite のテンプレートの場合:
# git clone でテンプレートを取得
git clone https://github.com/vitejs/vite.git --depth 1
cp -r vite/packages/create-vite/template-react-ts my-vite-app
cd my-vite-app
pnpm install
テンプレートの一覧は https://github.com/vitejs/vite/tree/main/packages/create-vite から確認できます。
ポイント
| やること | 説明 |
|---|---|
プロジェクトは /home/ 以下に置く | /mnt/c/ ではファイル監視やパフォーマンスに問題が出やすいので注意 |
| VS Code Remote - WSL を使う | /home/ 以下のファイルを快適に編集可能 |
which コマンドで確認 | Node.js や pnpm が Windows 側のものではなく WSL 内のものか確認 |
| GitHub API エラー時の最終手段は手動で取得 | git clone などでテンプレートリポジトリから直接コピー |
miseによるツール管理
この章では、開発ツールのバージョン管理を簡単にしてくれる「mise」と、Web開発に欠かせない「Node.js」について一緒に学んでいきましょう。最初は設定が少し面倒に感じるかもしれませんが、一度覚えてしまえば開発がグッと楽になります。
学習目標
- Node.jsの役割とJavaScriptランタイムについて理解する
- miseを使った開発ツールの管理方法を覚える
- プロジェクトごとに違うバージョンを使い分ける方法を学ぶ
- パッケージマネージャの基本的な使い方を学ぶ
Node.jsって何?
JavaScriptが動く場所
ブラウザー
- Chrome (V8エンジン)
- Firefox (SpiderMonkeyエンジン)
- Safari (JavaScriptCoreエンジン)
サーバーサイド
- Node.js (V8エンジン)
- Deno (V8エンジン)
- Bun (JavaScriptCoreエンジン)
従来、JavaScriptはブラウザでしか動きませんでした。しかし、Node.jsの登場により、サーバーでもJavaScriptが使えるようになったのです。
Node.jsの魅力
技術的な特徴:
- V8 エンジン: Googleが開発した高性能なJavaScriptエンジン
- イベントループ: 非同期処理がとても得意
- 豊富なエコシステム: npmで何十万ものパッケージが利用可能
主な用途:
- Webサーバーの作成(Express、Fastify、Hono等)
- ビルドツールの実行(Vite、Webpack等)
- コマンドラインツールの開発
- フロントエンド開発環境(React、Vue等)
Node.jsのバージョンについて
Node.jsは定期的に新しいバージョンがリリースされます。基本的にはLTS(Long Term Support)版を選んでおけば安心です。
# Node.js のリリースサイクル
偶数バージョン (20, 22, 24) → LTS版(長期サポート)
奇数バージョン (21, 23, 25) → Current版(最新機能)
# おすすめのLTSバージョン
24.x.x # 最新のアクティブLTS
miseって何?
基本的な概念
mise は、プログラミング言語や開発ツールのバージョンを管理してくれる便利なツールです。「このプロジェクトではNode.js 22を使って、あのプロジェクトではNode.js 24を使いたい」といった要望を簡単に実現できます。
mise で管理できる主なツール:
他にも多数の言語やツールをサポートしています。詳しくは 公式ドキュメント を参照してください。
miseの魅力
- 統一されたコマンド: 異なる言語やツールを同じ方法で管理できる
- プロジェクト単位の設定:
mise.tomlファイルでバージョンを指定 - 高速: Rustで作られているのでとても速い
- 自動切り替え: フォルダ移動時に自動でバージョンが切り替わる
従来のバージョン管理ツールとの比較
従来は言語ごとに異なるツールを使う必要がありました:
| ツール | 管理対象 | 速度 | 設定ファイル |
|---|---|---|---|
| mise | 多言語・ツール | とても速い | mise.toml |
| asdf | 多言語・ツール | 普通 | .tool-versions |
| nvm | Node.jsのみ | 普通 | .nvmrc |
| pyenv | Pythonのみ | 普通 | .python-version |
| rbenv | Rubyのみ | 普通 | .ruby-version |
miseなら1つのツールで全部管理できるので、覚えることが少なくて済みます。
miseをインストールしよう
1. インストール方法
# mise のインストール (全プラットフォーム共通)
curl https://mise.run | sh
# または、各OS固有の方法
# Windows (PowerShell): irm https://mise.run/install.ps1 | iex
# macOS: brew install mise
# Linux: curl https://mise.run | sh
2. シェル設定
Bash
echo "eval \"\$(${HOME}/.local/bin/mise activate bash)\"" >> ~/.bashrc
source ~/.bashrc
Zsh
echo "eval \"\$(${HOME}/.local/bin/mise activate zsh)\"" >> ~/.zshrc
source ~/.zshrc
Fish
echo "${HOME}/.local/bin/mise activate fish | source" >> ~/.config/fish/config.fish
3. Node.jsのインストール
# プロジェクトディレクトリで実行
cd my-project
# Node.js最新LTS版をインストール
mise use node@lts
# パッケージマネージャ pnpm もインストール
mise use pnpm@latest
これで mise.toml というファイルが自動的に作成されます:
[tools]
node = "24"
pnpm = "latest"
このファイルをGitで管理することで、チーム全員が同じバージョンのツールを使えるようになります。
Node.jsが使えるか確認しよう
# Node.jsのバージョン確認
node --version
# → v24.x.x と表示されればOK
# npmのバージョン確認(Node.jsに標準で付属)
npm --version
# pnpmのバージョン確認
pnpm --version
パッケージマネージャについて
パッケージマネージャって何?
Node.jsの世界では、他の人が作った便利なコード(パッケージ)を簡単に使うことができます。そのパッケージを管理してくれるのが「パッケージマネージャー」です。
主なパッケージマネージャー
1. npm(Node Package Manager)
Node.jsと一緒にインストールされる標準のパッケージマネージャーです。
npm install package-name # パッケージをインストール
npm install --save-dev package-name # 開発用パッケージとしてインストール
npm run script-name # スクリプトを実行
2. pnpm(推奨)
「performant npm」の略で、高速で効率的なパッケージマネージャーです。
pnpm add package-name # パッケージをインストール
pnpm add -D package-name # 開発用パッケージとしてインストール
pnpm run script-name # スクリプトを実行
pnpmの利点:
- 高速: npmより3倍以上速い
- 省ディスク: 同じパッケージを複数プロジェクトで共有
- 厳格: 依存関係の問題を早期発見
このカリキュラムでは pnpm を使用することを推奨します。
package.jsonの基本
package.jsonって何?
package.json は、プロジェクトの設定と依存関係を記録するファイルです。
{
"name": "my-project",
"version": "1.0.0",
"scripts": {
"dev": "vite",
"build": "vite build",
"test": "vitest"
},
"dependencies": {
"react": "^18.2.0"
},
"devDependencies": {
"vite": "^5.0.0"
}
}
重要なフィールド
- name: プロジェクト名
- version: バージョン番号
- scripts:
pnpm runで実行できるコマンド - dependencies: 本番環境で必要なパッケージ
- devDependencies: 開発環境のみで必要なパッケージ
スクリプトの実行
# package.jsonのscriptsに定義されたコマンドを実行
pnpm run dev # 開発サーバー起動
pnpm run build # ビルド実行
pnpm run test # テスト実行
基本的な使い方(mise)
1. 利用可能なツールの確認
# 利用可能なツール一覧
mise search
# Node.jsの利用可能バージョン
mise ls-remote node
# インストール済みツール確認
mise ls
2. バージョンの設定
グローバル設定
# システム全体のデフォルトバージョン
mise use --global node@lts
mise use --global pnpm@latest
プロジェクト設定
# プロジェクトディレクトリで実行
cd my-project
mise use node@lts
mise use pnpm@latest
3. 現在のバージョン確認
# 現在使用中のバージョン
mise current
トラブルシューティング
- mise が見つからない
# パスの確認
which mise
echo $PATH
# シェル設定の再読み込み
source ~/.bashrc # or ~/.zshrc
- 古いバージョンマネージャとの競合
# nvm, pyenv などを無効化
# ~/.bashrc から該当行を削除またはコメントアウト
# export PATH="$HOME/.nvm:$PATH" # ← これをコメントアウト
- プラグインのインストールエラー
# キャッシュクリア
mise cache clear
# プラグイン再インストール
mise plugin uninstall node
mise plugin install node
実習課題
1. 環境確認
# miseのバージョン確認
mise --version
# Node.jsのバージョン確認
node --version
# pnpmのバージョン確認
pnpm --version
2. 簡単なプロジェクトの作成
# プロジェクトフォルダ作成
mkdir my-first-project
cd my-first-project
# Node.jsとpnpmの設定
mise use node@lts
mise use pnpm@latest
# package.jsonの作成
pnpm init --init-type=module
3. パッケージのインストールと実行
# Viteをインストール
pnpm add -D vite
# package.jsonにスクリプトを追加(手動で編集)
# "scripts": {
# "dev": "vite"
# }
# 開発サーバー起動
pnpm run dev
ポイント
この章で学んだことをまとめておきます。
Node.jsについて:
- JavaScriptランタイム: ブラウザ以外でもJavaScriptを実行できる環境
- V8エンジン: Googleが開発した高性能なJavaScriptエンジンを使用
- LTS版: 長期サポート版で、安定性を重視するプロジェクトにおすすめ
- 豊富なエコシステム: npmで何十万ものパッケージが利用可能
miseについて:
- 統一管理: 複数の開発ツールのバージョンを1つのツールで管理
- プロジェクト単位: フォルダごとに異なるバージョンを自動切り替え
- チーム開発:
mise.tomlで全員が同じ環境を構築可能
パッケージマネージャについて:
- npm: Node.js標準のパッケージマネージャ
- pnpm: 高速で効率的、このカリキュラムで推奨
- package.json: プロジェクトの設定と依存関係を記録
これらを使うことで:
- ✅ 異なるプロジェクトで異なるNode.jsバージョンを簡単に使い分けられる
- ✅ チーム全員が同じツールバージョンで開発できる
- ✅ 新しいメンバーの環境構築が簡単になる
- ✅ 豊富なnpmパッケージを活用できる
- ✅ モダンなWeb開発ツールが使える
最初は覚えることが多くて大変かもしれませんが、miseとNode.jsに慣れてしまえば、Web開発がとても効率的になりますよ。実際に手を動かしながら、少しずつ覚えていきましょう!
VS Code環境設定
この章では、Web開発に欠かせないエディタ「Visual Studio Code(VS Code)」について一緒に学んでいきましょう。VS Codeは無料で使えて、しかもとても高機能なエディタです。最初は設定が少し大変かもしれませんが、一度設定してしまえばとても快適に開発できるようになります。
学習目標
- VS Codeの基本的な使い方を覚える
- Web開発に便利な拡張機能を知る
- 効率的なコーディング環境を作る
- AI開発ツールとの連携方法を学ぶ
VS Codeってどんなエディタ?
VS Codeの魅力
VS Codeにはこんな素晴らしい特徴があります:
使いやすさ:
- Language Server Protocol (LSP): プログラミング言語のサポートが充実
- 豊富な拡張機能: 必要な機能を自由に追加できる
- TypeScript統合: マイクロソフト製なので、TypeScriptとの相性が抜群
- リモート開発: コンテナやクラウド環境でも開発できる
パフォーマンス:
- Electronベースながら軽快に動作(非常に最適化されています)
- 大きなファイルでも安定して動作
- メモリ使用量も効率的
VS Codeの画面構成を覚えよう
ワークスペースの構成
VS Codeの画面は、いくつかのエリアに分かれています。最初は覚えにくいかもしれませんが、慣れてしまえばとても使いやすいですよ。

キーボードショートカット
ファイル・ナビゲーション
# ファイル操作
Ctrl/Cmd + N # 新規ファイル
Ctrl/Cmd + O # ファイルを開く
Ctrl/Cmd + P # クイックオープン(ファイル検索)
Ctrl/Cmd + Shift + P # コマンドパレット
Ctrl/Cmd + W # タブを閉じる
Ctrl/Cmd + Shift + T # 最近閉じたタブを再度開く
# ナビゲーション
Ctrl/Cmd + G # 行番号で移動
Ctrl/Cmd + Shift + O # シンボル検索(関数・変数)
F12 # 定義へ移動
Alt + F12 # 定義をピーク表示
Ctrl/Cmd + - # 前の位置に戻る
編集・検索
# 基本編集
Ctrl/Cmd + / # コメントアウト
Ctrl/Cmd + [ # インデント減らす
Ctrl/Cmd + ] # インデント増やす
Shift + Alt + F # フォーマット
# マルチカーソル
Ctrl/Cmd + D # 選択した単語と同じものを次々選択
Ctrl/Cmd + Shift + L # 選択した単語と同じものを全て選択
Alt + Click # マルチカーソル
Ctrl/Cmd + Alt + Up/Down # カーソルを上下に追加
# 検索・置換
Ctrl/Cmd + F # ファイル内検索
Ctrl/Cmd + H # 置換
Ctrl/Cmd + Shift + F # 全体検索
Ctrl/Cmd + Shift + H # 全体置換
ワークスペース管理
# パネル・サイドバー
Ctrl/Cmd + B # サイドバー表示切り替え
Ctrl/Cmd + J # パネル表示切り替え
Ctrl/Cmd + ` # ターミナル表示切り替え
# エディタ管理
Ctrl/Cmd + \ # エディタを分割
Ctrl/Cmd + 1/2/3 # エディタグループ間移動
Ctrl/Cmd + Shift + E # Explorer表示
Ctrl/Cmd + Shift + G # Git表示
Web開発推奨拡張機能
コード品質・フォーマッター
Biome
{
"biome.enabled": true,
"editor.defaultFormatter": "biomejs.biome",
"editor.formatOnSave": true
}
- ESLint + Prettier の代替
- 超高速なリンター・フォーマッター
- Rust製で軽量
Git統合強化
GitLens
- インラインブレーム表示
- コミット履歴のリッチな可視化
- ファイル履歴とHeatmap
HTTP・API開発
AI支援開発
GitHub Copilot
{
"github.copilot.enable": {
"typescript": true,
"typescriptreact": true,
"javascript": true,
"javascriptreact": true
}
}
- AIによるコード提案
- コンテキストを理解したコード生成
- ドキュメント生成支援
開発効率化
言語サポート
Pretty TypeScript Errors
- TypeScriptのエラーメッセージを読みやすく整形
- エラーの原因と解決策を視覚的に表示
- 型エラーの理解を大幅に向上
TypeScriptのエラーメッセージは、初心者にとって理解しにくいことがあります。この拡張機能は、エラーメッセージを色分けし、構造化して表示することで、問題の把握と解決を容易にします。
特に複雑な型エラーや、ジェネリクスに関するエラーメッセージが読みやすくなり開発効率が向上します。
UI/UXサポート
Tailwind CSS IntelliSense
- クラス名補完
- カラープレビュー
- CSS値のホバー表示
まとめ
ポイント
この章で学んだ重要なことをまとめておきますね。
- VS Code: 無料で高機能なコードエディタ
- 拡張機能: 必要な機能を自由に追加できる仕組み
- IntelliSense: コード補完や型情報の表示機能
- 統合ターミナル: エディタ内でコマンドを実行できる機能
- デバッガー: コードの動作を詳細に確認できるツール
VS Codeを使うことで:
- ✅ 効率的なコード編集ができる
- ✅ 豊富な拡張機能で機能を拡張できる
- ✅ 統合開発環境としてすべての作業を一箇所で完結できる
- ✅ Gitとの連携でバージョン管理が簡単
- ✅ AI支援でコード作成が効率化される
最初は設定や拡張機能の選択に迷うかもしれませんが、まずは基本的な機能から慣れていき、必要に応じて少しずつカスタマイズしていくのがおすすめです。VS Codeは開発者にとって強力な味方になってくれますよ!
Git・GitHub基礎
この章では、Web開発に欠かせないGitとGitHubについて一緒に学んでいきましょう。Gitは最初は少し難しく感じるかもしれませんが、慣れてしまえばとても便利なツールです。気楽に読み進めてくださいね。
学習目標
- Gitの基本的な仕組みとバージョン管理について理解する
- GitHubを使って自分のコードを管理できるようになる
- ブランチを使った開発の流れを覚える
- チームでの開発に必要なPull Requestの使い方を学ぶ
Gitって何?
バージョン管理システム(VCS)
みなさんは、大切な文書やファイルを編集するとき、「保存するまえに念のためコピーを作っておこう」と思ったことはありませんか?Gitはそのような「ファイルの履歴管理」を自動的にやってくれる便利なツールです。
Gitの特徴
Gitには他のツールにない素晴らしい特徴があります。
- 分散型: チーム全員が完全な履歴を持つ(一人が消しても大丈夫!)
- 高速: ほとんどの操作がサクサク動く
- ブランチ: 並行開発がとても簡単
- 非線形開発: 複数人での開発に最適化されている
基本的な仕組み
Gitには3つの重要な場所があります。最初は覚えにくいかもしれませんが、この図を頭に入れておくと後で理解が深まりますよ。
Gitの3つの領域
画像: https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F より引用

- Working Directory - 作業ディレクトリ。ファイルやフォルダーの実体があります。ここでファイルを編集します。
- Staging Area - コミットする前に変更内容を一時的にまとめておく (ステージング) するための領域です。
git addすることで変更内容が「ステージング」として扱われます。 - Repository - あらゆる変更履歴を保存しておく保管庫。
git commitすることで「ステージング」にある変更内容が「メッセージ」とともに「コミット」に移されます。.gitディレクトリ内のファイルによって管理されます。この.gitディレクトリを同期 (push/pull) することによって共同編集を可能にします。
Gitをインストールしてみよう
それでは、実際にGitをインストールして使ってみましょう!お使いのOSに合わせて進めてくださいね。
Windows (WSL) ・Linux の場合
# Ubuntu/Debian の場合
sudo apt update
sudo apt install git
# CentOS/RHEL の場合
sudo yum install git
Windows (ネイティブ) の場合
# Git for Windows のインストール
# https://gitforwindows.org/ からダウンロードして実行してください
# または Chocolatey を使う場合(上級者向け)
choco install git
# または winget を使う場合(Windows 10/11)
winget install Git.Git
macOSの場合
# Homebrew でインストール(推奨)
brew install git
# Xcode Command Line Tools でも可能
xcode-select --install
最初の設定をしよう
Gitをインストールしたら、必ず最初に自分の情報を設定しましょう。これをしないとコミットができませんからね。
# あなたの名前とメールアドレスを設定します
git config --global user.name "あなたの名前"
git config --global user.email "your.email@example.com"
# デフォルトブランチ名を設定(最近は main が一般的です)
git config --global init.defaultBranch main
# エディタの設定(VS Codeを使う場合)
git config --global core.editor "code --wait"
# 設定の確認
git config --list
Note: GitHubで使用するメールアドレスと同じものを設定することをおすすめします。
基本的なGitの操作を覚えよう
それでは、実際にGitを使って作業をしてみましょう。最初は一つずつゆっくりと進めていきますね。
1. はじめてのリポジトリを作ってみよう
# 新しいプロジェクト用のフォルダを作ります
mkdir my-project
cd my-project
# Gitリポジトリとして初期化(これでGit管理が開始されます)
git init
# 最初のファイルを作ってみましょう
echo "# My Project" > README.md
git add README.md
git commit -m "Initial commit"
これで最初のコミット(保存ポイント)ができました!
2. 日常的な作業の流れ
普段の開発では、この3つの操作を繰り返します。慣れてしまえば自然にできるようになりますよ。
# ファイルを編集した後...
git status # 何が変更されたかチェック
git add . # すべての変更をステージング(次のコミットに含める準備)
git commit -m "新しい機能を追加" # コミット(保存ポイントを作成)
# 特定のファイルだけコミットしたい場合
git add src/index.js
git commit -m "index.jsを更新"
3. 履歴を確認してみよう
作業の履歴を見ることができます。これがGitの魅力の一つですね。
# コミットの履歴を見る
git log # 詳細な履歴
git log --oneline # 簡潔に一行で表示(見やすいです)
git log --graph # ブランチの分岐を視覚的に表示
# 変更内容を詳しく確認
git diff # まだコミットしていない変更内容
git diff --cached # コミット予定の変更内容
git show HEAD # 最新コミットの詳細
ブランチを使ってみよう
ブランチは、Gitの中でも特に便利な機能です。「元のコードを壊さずに新しい機能を試せる」と考えてください。
1. ブランチの基本操作
# 現在のブランチを確認
git branch # ローカルのブランチ一覧
git branch -r # リモートのブランチ一覧
git branch -a # すべてのブランチ
# 新しいブランチを作って移動
git branch feature/new-feature # ブランチを作成
git checkout feature/new-feature # ブランチに移動
# 上記を一度にやる(便利です!)
git checkout -b feature/new-feature
# さらに新しいGitでは(2.23以降)
git switch -c feature/new-feature
Note:
Gitはどうしてこんなに難しいの?
git add、git commit、git pushなど、バージョン管理するために覚えることが多くて大変ですよね。なぜこんなに複雑なのでしょうか? それは根本的に「Gitが解こうとしている問題が非常に複雑」だからなのです。もともとGitはLinus Torvalds氏によってLinuxカーネルのような大規模で分散したプロジェクトを効率的に管理するために開発されました。 Gitでは各開発者のマシンにコードすべてをコピーし、ローカルでも管理することが可能な分散型バージョン管理モデルを採用しています。 これは中央集権型バージョン管理モデルの SVN (Subversion) とは対象的で、開発者はオフラインでもあらゆる履歴にアクセスでき、また開発者の手で自由に履歴を操作できるように設計されています。 こうした分散型バージョン管理モデルはオープンソース開発のような大規模で分散したチームにとって非常に重要な特徴なのです。 Gitにはそのための仕組みが多く備わっており、そのトレードオフとして複雑になってしまっているのです。
2. ブランチ戦略について
チームで開発するときの基本的なパターンをご紹介しますね。
GitHub Flow(シンプルで推奨)
main ─────●─────●─────●─────
↗ ↓ ↗ ↓
feature ●─●─●──●─● ●─●──●─●
このやり方は:
mainブランチは常に安定版- 機能追加は
featureブランチで行う - 完成したら
mainにマージ
Git Flow(複雑なプロジェクト向け)
main ─────●─────●─────●─────
↗ ↓ ↗ ↓ ↗ ↓
develop ─────●─────●─────●─────
↗ ↓ ↗ ↓
feature ●───●───● ●───●
初心者の方はまずGitHub Flowから始めることをおすすめします。
3. ブランチをまとめよう(マージとリベース)
機能ができたら、メインのブランチに統合する必要があります。2つの方法があります。
マージ(Merge): 2つのブランチを合体させる
# feature ブランチの作業を main に取り込む
git switch main
git merge feature/new-feature
# マージコミットを作らない場合(きれいな履歴になります)
git merge --ff-only feature/new-feature
リベース(Rebase): 履歴をきれいに整理する
# feature ブランチを main の最新状態に合わせる
git switch feature/new-feature
git rebase main
# 履歴を整理したい場合(上級者向け)
git rebase -i HEAD~3
最初はマージだけ覚えれば十分ですよ。
GitHubを使ってみよう
GitHubは、Gitで管理しているプロジェクトをクラウド上で保存・共有できるサービスです。GitHubがあることで、チームでの開発がとても簡単になります。
1. リモートリポジトリに接続してみよう
# GitHubでリポジトリを作成した後、以下のコマンドで接続します
git remote add origin https://github.com/ユーザー名/リポジトリ名.git
git push -u origin main
2. 基本的なGitHub操作
# 作業を同期する
git fetch origin # リモートの最新情報を取得
git pull origin main # main ブランチの最新を取得
# 自分の作業をアップロード
git push origin feature/new-feature
# 強制的にプッシュ(履歴を書き換えた場合など、注意が必要です)
git push --force-with-lease origin feature/new-feature
HTTPS vs SSH: GitHubとの接続方法は2つあります
- HTTPS:
https://github.com/ユーザー名/リポジトリ名.git(ファイアウォールやプロキシの内側にいる場合でもアクセス可能) - SSH:
git@github.com:ユーザー名/リポジトリ名.git(GitHub CLIを使わずに設定可能)
3. GitHub CLI を使う方法 (おすすめ)
GitHub CLI を使うことでWebブラウザーを使ってより安全にHTTPSでアクセスすることができます。
Windows (WSL)・Linux でのインストール方法:
# Ubuntu/Debian の場合
sudo apt update
sudo apt install gh
gh auth login
詳しくは「gh auth login」をご覧ください。
別の方法: SSH鍵の設定
SSH鍵を設定することでGitHub CLIを使わずに設定することも可能です。
# SSH鍵を生成(初回のみ)
ssh-keygen -t ed25519
# 生成された公開鍵をGitHubに登録
# ~/.ssh/id_ed25519.pub の内容をコピーして
# GitHubの Settings > SSH and GPG keys で登録
# 接続テスト
ssh -T git@github.com
Pull Requestを使ってみよう
Pull Request(PR)は、GitHubでチーム開発をする際の基本的な仕組みです。「この変更をレビューしてもらって、問題なければメインブランチに取り込んでください」という意味ですね。
1. Pull Requestの基本的な流れ
# 1. 新しい機能用のブランチを作成
git switch -c fix/issue-123
# 2. 機能を実装してテスト
echo "新機能実装" >> src/feature.js
git add .
git commit -m "Fix #123: 新しい機能を追加"
# 3. GitHubにプッシュ
git push origin fix/issue-123
- GitHubのWebサイトでPull Requestを作成
- チームメンバーがレビュー
- 問題なければ
mainブランチにマージ
2. Pull Requestの具体例
## 概要
ユーザー認証機能を追加しました。
## 変更内容
- [ ] ログイン画面の実装
- [ ] JWT トークンの実装
- [ ] パスワードハッシュ化
- [ ] 単体テストの追加
## 確認方法
1. `npm run dev` で開発サーバー起動
2. `http://localhost:3000/login` にアクセス
3. テストユーザーでログイン確認
## 関連Issue
Fixes #123
レビューしやすいように、なぜこの変更が必要なのか、具体的に何を変えたのか、どうやって確認するのか書いておくと良いですね。
3. コードレビューのポイント
# レビュー前のセルフチェック
git diff main...HEAD --name-only # 変更ファイル一覧
git diff main...HEAD # 変更内容の確認
# コミット履歴の整理
git rebase -i main # squash、fixup等で整理
実践的なGitワークフロー
1. チーム開発での標準フロー
# 1. 最新のmainを取得
git checkout main
git pull origin main
# 2. 機能ブランチ作成
git checkout -b feature/user-profile
# 3. 開発・コミット
git add .
git commit -m "Add user profile component"
# 4. 定期的にmainをマージ(競合回避)
git fetch origin
git rebase origin/main
# 5. PR作成前の最終チェック
git log --oneline main..HEAD # 追加したコミット確認
# 6. プッシュとPR作成
git push origin feature/user-profile
2. 緊急修正(Hotfix)フロー
# production 環境の緊急修正
git checkout main
git pull origin main
git checkout -b hotfix/security-fix
# 修正・テスト
git add .
git commit -m "Fix security vulnerability"
# 即座にマージ・デプロイ
git checkout main
git merge hotfix/security-fix
git push origin main
git tag v1.2.1 # タグ付け
git push origin v1.2.1
高度なGit操作
1. 履歴の修正
# 最後のコミットメッセージを修正
git commit --amend -m "正しいメッセージ"
# 過去のコミットを修正(Interactive Rebase)
git rebase -i HEAD~3
# pick → edit でコミット選択し、修正後
git commit --amend
git rebase --continue
2. 変更の取り消し
# 作業ディレクトリの変更を破棄
git checkout -- filename.js
git restore filename.js # 新しいコマンド
# ステージングを取り消し
git reset HEAD filename.js
git restore --staged filename.js # 新しいコマンド
# コミットを取り消し
git reset --soft HEAD~1 # コミットのみ取り消し
git reset --hard HEAD~1 # すべて取り消し(危険)
3. 作業の一時保存
# 作業を一時保存
git stash push -m "作業中の変更"
git stash
# 一時保存した作業を復元
git stash pop
git stash apply stash@{0}
# 一時保存の確認
git stash list
git stash show stash@{0}
.gitignoreの活用
基本的な.gitignore
# 依存関係
node_modules/
venv/
env/
# ビルド成果物
dist/
build/
*.min.js
# ログファイル
*.log
logs/
# OS固有
.DS_Store
Thumbs.db
# IDE固有
.vscode/
.idea/
*.swp
# 環境設定
.env
.env.local
プロジェクト別例
React プロジェクト
node_modules/
build/
.env
npm-debug.log
.DS_Store
Python プロジェクト
__pycache__/
*.py[cod]
venv/
.env
.pytest_cache/
トラブルシューティング
よくある問題と解決方法
開発中によく遭遇する問題と、その解決方法をご紹介しますね。
1. マージコンフリクト(競合)が起きた場合
# マージで競合が発生したとき
git status # どのファイルで競合しているかチェック
# ファイルを手動で編集して競合を解決後
git add conflicted-file.js
git commit -m "競合を解決"
2. 間違ったブランチで作業してしまった場合
# 現在の変更を一時的に保存
git stash
# 正しいブランチに移動
git checkout correct-branch
git stash pop # 保存した変更を復元
3. プッシュできない場合
# リモートの最新情報を取得して統合
git fetch origin
git rebase origin/main
# または、マージで統合する場合
git pull --rebase origin main
セキュリティについて
機密情報の管理
大切なパスワードやAPIキーなどは、絶対にGitにコミットしないように注意しましょう。
# .env ファイルの例(機密情報を保存)
DB_PASSWORD=secret123
API_KEY=abcdef123456
# .gitignore に追加して、Gitが無視するように設定
echo ".env" >> .gitignore
ポイント
この章で学んだ重要なことをまとめておきますね。
- Git: ファイルの変更履歴を自動で管理してくれる便利なツール
- リポジトリ: プロジェクトの全履歴が保存される場所
- コミット: 作業の区切りとなる保存ポイント
- ブランチ: 元のコードを壊さずに新機能を開発できる仕組み
- GitHub: Gitで管理しているプロジェクトをクラウドで共有・管理できるサービス
- Pull Request: チームでのコードレビューと統合の仕組み
Git・GitHubを使うことで:
- ✅ コードの変更履歴を完全に追跡できる
- ✅ チーム開発での効率的な作業分担ができる
- ✅ 分散型による自然なバックアップが作られる
- ✅ Pull Requestでコードの品質を維持できる
最初は覚えることが多くて大変かもしれませんが、慣れてしまえばとても便利なツールです。実際に手を動かしながら、少しずつ覚えていきましょう!
React環境構築
この章では、現代のWebアプリ開発に欠かせない「React」の環境構築について一緒に学んでいきましょう。Reactは最初は少し難しく感じるかもしれませんが、コンポーネントという考え方に慣れてしまえば、とても効率的にWebアプリが作れるようになりますよ。
学習目標
- Reactの基本的な考え方とコンポーネントについて理解する
- Viteを使った最新のReact開発環境を作る
- シンプルなTodoアプリを作りながらReactに慣れる
- ビルドとデプロイの基本を覚える
Reactって何?
基本的な概念
React は、Meta(旧Facebook)が開発したユーザーインターフェース(UI)を作るためのJavaScriptライブラリです。「部品(コンポーネント)を組み合わせてWebページを作る」という考え方が特徴です。
Reactの魅力
- コンポーネントベース: UIを再利用できる部品として作成
- 宣言的なUI: 「どう表示するか」ではなく「何を表示するか」を記述
- 仮想DOM: 画面更新が高速で効率的
- 単方向データフロー: データの流れが分かりやすい
Reactの基本的な概念
Reactには押さえておくべき重要な概念がいくつかあります。ここでは最低限必要なものだけ紹介します。
Note: より詳しい内容はReact公式ドキュメント(日本語)で学べます。
1. コンポーネント
コンポーネントは、UIの一部分を担当する再利用可能な部品です。
// 関数コンポーネント(現在の主流)
const Welcome = ({ name }) => {
return <h1>こんにちは、{name}さん!</h1>;
};
「コンポーネント」という名前が難しそうに聞こえるかもしれませんが、入力(Props)を受け取り、出力として見た目(JSX)を返すただのJavaScriptの関数です。
Reactではこれを <Welcome name="太郎" /> のように使うことができ、画面上に「こんにちは、太郎さん!」と表示されます。
2. Props(プロップス)
親コンポーネントから子コンポーネントへデータを渡す仕組みです。
// Props - 親から子への値の渡し方
function Button({ text, onClick }) {
return <button onClick={onClick}>{text}</button>;
}
ただの関数の引数です。JavaScriptの関数なので文字列だけでなく数値や関数、オブジェクトなどあらゆるものを渡すことができます。
3. State(状態)
コンポーネントが持つ内部データです。useStateを使って管理します。
// State - コンポーネントの内部状態
import { useState } from "react";
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>カウント: {count}</p>
<button onClick={() => setCount(count + 1)}>+1</button>
</div>
);
}
Viteによるプロジェクト作成
1. Viteとは
Vite(ヴィート)は、高速で軽量なビルドツール・開発サーバーです。
特徴:
- ⚡ 高速: ES modules とネイティブESMを活用
- 🔥 HMR: Hot Module Replacement
- 📦 最適化: Rollup ベースのプロダクションビルド
- 🔧 設定不要: ゼロコンフィグで開始可能
2. プロジェクト作成
# Viteでプロジェクト作成
pnpm create vite my-react-app --template react-ts
# プロジェクトに移動
cd my-react-app
# 依存関係インストール
pnpm install
# 開発サーバー起動
pnpm run dev
3. プロジェクト構造
my-react-app/
├── public/ # 静的ファイル
│ └── vite.svg
├── src/ # ソースコード
│ ├── assets/ # アセット(画像、CSS等)
│ ├── components/ # コンポーネント
│ ├── hooks/ # カスタムフック
│ ├── types/ # TypeScript型定義
│ ├── App.tsx # メインアプリコンポーネント
│ ├── main.tsx # エントリーポイント
│ └── index.css # グローバルCSS
├── index.html # HTMLテンプレート
├── package.json # 依存関係・スクリプト
├── tsconfig.json # TypeScript設定
└── vite.config.ts # Vite設定
TypeScript設定
Viteで作成されたプロジェクトには、既に最適な設定が含まれています。パスエイリアスを使いたい場合は以下を追加します。
// tsconfig.json
{
"extends": "@tsconfig/vite-react/tsconfig.json",
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
},
"include": ["src"]
}
# ベース設定のインストール
pnpm add -D @tsconfig/vite-react
Note Viteはtsconfig.jsonの
paths設定を自動的に認識するため、vite.config.tsでの追加設定は不要です。
基本的なReactアプリケーション構築
シンプルなTodoアプリ
型定義
// src/types/todo.ts
export interface Todo {
id: number;
text: string;
completed: boolean;
}
メインアプリケーション
// src/App.tsx
import { useState } from "react";
import type { Todo } from "@/types/todo";
function App() {
const [todos, setTodos] = useState<Todo[]>([]);
const [input, setInput] = useState("");
const addTodo = () => {
if (input.trim()) {
setTodos([...todos, { id: Date.now(), text: input, completed: false }]);
setInput("");
}
};
const toggleTodo = (id: number) => {
setTodos(
todos.map((todo) =>
todo.id === id ? { ...todo, completed: !todo.completed } : todo,
),
);
};
return (
<div className="app">
<h1>Todo App</h1>
<div>
<input
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="Add a new todo..."
/>
<button onClick={addTodo}>Add</button>
</div>
<ul>
{todos.map((todo) => (
<li key={todo.id} onClick={() => toggleTodo(todo.id)}>
<span
style={{
textDecoration: todo.completed ? "line-through" : "none",
}}
>
{todo.text}
</span>
</li>
))}
</ul>
</div>
);
}
export default App;
Note 実際のアプリでは、コンポーネントを分割して再利用性を高めます。上記は学習用の最小構成です。
React Hooks の基本
Reactには「Hooks」という機能があります。最もよく使う2つを紹介します。
useState - 状態管理
import { useState } from "react";
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>カウント: {count}</p>
<button onClick={() => setCount(count + 1)}>+1</button>
</div>
);
}
useEffect - 副作用処理
import { useState, useEffect } from "react";
function UserProfile({ userId }: { userId: number }) {
const [user, setUser] = useState(null);
useEffect(() => {
fetch(`/api/users/${userId}`)
.then((res) => res.json())
.then(setUser);
}, [userId]); // userIdが変わったら再実行
return <div>{user?.name}</div>;
}
Note より詳しくはReact公式ドキュメントを参照してください。
ビルドとデプロイ
プロダクションビルド
pnpm run build # ビルド実行
pnpm run preview # ビルド結果の確認
環境変数
# .env.local
VITE_API_BASE_URL=http://localhost:3001/api
// 使用例
const apiUrl = import.meta.env.VITE_API_BASE_URL;
Vercel デプロイ (任意)
npm i -g vercel
vercel --prod
Note VercelはViteプロジェクトを自動検出するため、設定ファイルは通常不要です。
トラブルシューティング
ホットリロードが効かない
# 開発サーバーを再起動
Ctrl+C
pnpm run dev
ビルドエラー
# 依存関係を再インストール
rm -rf node_modules pnpm-lock.yaml
pnpm install
参考リンク
まとめ
この章では、React環境構築の基本を学びました。
ポイント
- Vite: 高速な開発サーバーとビルドツール
- コンポーネント: UIを部品として作る考え方
- Props: 親から子へデータを渡す仕組み
- State: コンポーネントが持つ内部データ
- Hooks: 「画面に影響するデータ(状態)」を保存・更新するための
useStateが基本
Reactは最初は難しく感じるかもしれませんが、コンポーネントを作りながら慣れていくことが一番の近道です。まずは小さなアプリから始めて、少しずつ機能を追加していきましょう!
TypeScript導入
この章では、JavaScriptに型の安全性を追加してくれる「TypeScript」について一緒に学んでいきましょう。TypeScriptは最初は少し複雑に感じるかもしれませんが、慣れてくるとバグが格段に減って、より安心してコードが書けるようになりますよ。
学習目標
- TypeScriptの基本的な考え方と型システムを理解する
- JavaScriptプロジェクトにTypeScriptを導入する方法を学ぶ
- 型を使ってバグを予防する方法を覚える
- 最新のTypeScript開発環境を構築する
TypeScriptって何?
基本的な概念
TypeScriptは、Microsoftが開発したJavaScriptの「型付き版」です。普通のJavaScriptに「型」という概念を追加することで、コードをより安全に、そして書きやすくしてくれます。
TypeScriptの魅力
- 早期エラー発見: コードを書いている段階でバグを発見できる
- 開発体験の向上: 自動補完やリファクタリング機能が充実
- コードがドキュメントになる: 型が仕様書の役割を果たす
- 大規模開発に強い: チーム開発でも安心してコードが書ける
- JavaScript互換: 既存のJavaScriptコードをそのまま使える
JavaScriptとの違い
| 項目 | JavaScript | TypeScript |
|---|---|---|
| 型システム | 動的(実行時に決まる) | 静的(事前に決める) |
| エラー発見 | 実行してみないと分からない | 書いている時点で分かる |
| 開発支援 | 基本的なもの | とても充実 |
| 学習コスト | 低い | 少し高い |
| ビルド工程 | そのまま実行可能 | コンパイルが必要 |
最初は少し大変かもしれませんが、慣れてしまえばJavaScriptには戻れなくなるほど便利ですよ。
TypeScriptの基本的な書き方
1. 基本的な型
プリミティブ型
// 基本型
let message: string = "Hello TypeScript";
let count: number = 42;
let isActive: boolean = true;
let data: null = null;
let value: undefined = undefined;
// 型推論(推奨)
let name = "Alice"; // string 型として推論
let age = 30; // number 型として推論
let isStudent = false; // boolean 型として推論
配列とオブジェクト
// 配列
let numbers: number[] = [1, 2, 3, 4, 5];
let names: Array<string> = ["Alice", "Bob", "Charlie"];
// オブジェクト
let person: {
name: string;
age: number;
isStudent?: boolean; // オプショナルプロパティ
} = {
name: "Alice",
age: 30,
};
// より複雑なオブジェクト
let config: {
apiUrl: string;
timeout: number;
features: {
auth: boolean;
cache: boolean;
};
} = {
apiUrl: "https://api.example.com",
timeout: 5000,
features: {
auth: true,
cache: false,
},
};
2. インターフェースと型エイリアス
インターフェース定義
// User インターフェース
interface User {
readonly id: number; // 読み取り専用
name: string;
email: string;
age?: number; // オプショナル
}
// インターフェースの使用
const createUser = (userData: User): User => {
return {
id: Date.now(),
...userData,
};
};
const user: User = {
id: 1,
name: "Alice",
email: "alice@example.com",
};
型エイリアス
// 基本的な型エイリアス
type UserId = number;
type UserRole = "admin" | "user" | "guest";
// 複雑な型
type APIResponse<T> = {
data: T;
status: "success" | "error";
message?: string;
};
// 使用例
type UserResponse = APIResponse<User>;
const fetchUser = async (id: UserId): Promise<UserResponse> => {
// API呼び出しロジック
return {
data: { id, name: "Alice", email: "alice@example.com" },
status: "success",
};
};
3. 関数の型定義
関数シグネチャ
// 基本的な関数
function add(a: number, b: number): number {
return a + b;
}
// アロー関数
const multiply = (a: number, b: number): number => a * b;
// オプション引数とデフォルト値
const greet = (name: string, title?: string, prefix = "Mr."): string => {
return `Hello, ${title || prefix} ${name}`;
};
// 可変長引数
const sum = (...numbers: number[]): number => {
return numbers.reduce((total, num) => total + num, 0);
};
高階関数の型定義
// コールバック関数の型
type EventHandler<T> = (event: T) => void;
type Transformer<T, U> = (input: T) => U;
// 使用例
const handleClick: EventHandler<MouseEvent> = (event) => {
console.log("Clicked at:", event.clientX, event.clientY);
};
const doubleNumbers: Transformer<number[], number[]> = (numbers) => {
return numbers.map((n) => n * 2);
};
4. ジェネリクス
基本的なジェネリクス
// ジェネリック関数
function identity<T>(arg: T): T {
return arg;
}
// 使用例
const stringValue = identity("hello"); // string型
const numberValue = identity(42); // number型
// 複数の型パラメータ
function pair<T, U>(first: T, second: U): [T, U] {
return [first, second];
}
const nameAge = pair("Alice", 30); // [string, number]
ジェネリクス制約
// インターフェース制約
interface Lengthwise {
length: number;
}
function logLength<T extends Lengthwise>(arg: T): T {
console.log(arg.length);
return arg;
}
logLength("hello"); // OK
logLength([1, 2, 3]); // OK
// logLength(42) // Error: number に length プロパティはない
5. ユニオン型とインターセクション型
ユニオン型(複数の型のうち一つ)
type Status = "loading" | "success" | "error";
type StringOrNumber = string | number;
// 判別可能なユニオン
interface LoadingState {
status: "loading";
}
interface SuccessState {
status: "success";
data: any;
}
interface ErrorState {
status: "error";
error: string;
}
type AppState = LoadingState | SuccessState | ErrorState;
const handleState = (state: AppState) => {
switch (state.status) {
case "loading":
console.log("Loading...");
break;
case "success":
console.log("Data:", state.data);
break;
case "error":
console.log("Error:", state.error);
break;
}
};
インターセクション型(複数の型を結合)
type Person = { name: string } & { age: number };
const person: Person = { name: "Alice", age: 30 };
プロジェクトへのTypeScript導入
1. 新規プロジェクトでのセットアップ
Vite + React + TypeScript
# プロジェクト作成
pnpm create vite my-ts-app --template react-ts
cd my-ts-app
pnpm install
# 開発サーバー起動
pnpm run dev
2. 既存JavaScriptプロジェクトの移行
# TypeScriptの追加
pnpm add -D typescript @types/node
# tsconfig.json作成
npx tsc --init
移行の流れ
.js→.tsファイル名変更- 型注釈を段階的に追加
// Before (JavaScript)
function calculateTotal(items) {
return items.reduce((sum, item) => sum + item.price, 0);
}
// After (TypeScript)
interface Item {
price: number;
name: string;
}
function calculateTotal(items: Item[]): number {
return items.reduce((sum, item) => sum + item.price, 0);
}
3. tsconfig.json の設定
React プロジェクト向け設定
# 推奨ベース設定のインストール
pnpm add -D @tsconfig/vite-react
{
"extends": "@tsconfig/vite-react/tsconfig.json",
"compilerOptions": {
// パスエイリアス設定
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
},
"include": ["src"]
}
Note:
@tsconfig/vite-reactは Vite + React に最適化された設定を提供します。必要に応じてcompilerOptionsで上書き可能です。
React + TypeScript実践
1. コンポーネントの型定義
基本的なコンポーネント
import { ReactNode } from "react";
// Props インターフェース
interface ButtonProps {
children: ReactNode;
variant?: "primary" | "secondary";
size?: "small" | "medium" | "large";
disabled?: boolean;
onClick?: (event: React.MouseEvent<HTMLButtonElement>) => void;
}
// コンポーネント定義
export const Button = ({
children,
variant = "primary",
size = "medium",
disabled = false,
onClick,
}: ButtonProps) => {
return (
<button
className={`btn btn--${variant} btn--${size}`}
disabled={disabled}
onClick={onClick}
>
{children}
</button>
);
};
// 使用例
const App = () => {
const handleClick = (event: React.MouseEvent<HTMLButtonElement>) => {
console.log("Clicked!", event.currentTarget);
};
return (
<Button variant="primary" onClick={handleClick}>
Click me
</Button>
);
};
フォームコンポーネント
import { useState, FormEvent, ChangeEvent } from "react";
interface LoginFormData {
email: string;
password: string;
}
interface LoginFormProps {
onSubmit: (data: LoginFormData) => Promise<void>;
}
export const LoginForm = ({ onSubmit }: LoginFormProps) => {
const [formData, setFormData] = useState<LoginFormData>({
email: "",
password: "",
});
const [isSubmitting, setIsSubmitting] = useState(false);
const handleChange = (event: ChangeEvent<HTMLInputElement>) => {
const { name, value } = event.target;
setFormData((prev) => ({ ...prev, [name]: value }));
};
const handleSubmit = async (event: FormEvent<HTMLFormElement>) => {
event.preventDefault();
setIsSubmitting(true);
try {
await onSubmit(formData);
} catch (error) {
console.error("Login failed:", error);
} finally {
setIsSubmitting(false);
}
};
return (
<form onSubmit={handleSubmit}>
<input
type="email"
name="email"
value={formData.email}
onChange={handleChange}
placeholder="Email"
required
/>
<input
type="password"
name="password"
value={formData.password}
onChange={handleChange}
placeholder="Password"
required
/>
<button type="submit" disabled={isSubmitting}>
{isSubmitting ? "Logging in..." : "Login"}
</button>
</form>
);
};
2. カスタムHooksの型定義
useLocalStorage Hook
import { useState } from "react";
type SetValue<T> = T | ((val: T) => T);
function useLocalStorage<T>(
key: string,
initialValue: T,
): [T, (value: SetValue<T>) => void] {
const [storedValue, setStoredValue] = useState<T>(() => {
try {
const item = window.localStorage.getItem(key);
return item ? JSON.parse(item) : initialValue;
} catch {
return initialValue;
}
});
const setValue = (value: SetValue<T>) => {
try {
const valueToStore =
value instanceof Function ? value(storedValue) : value;
setStoredValue(valueToStore);
window.localStorage.setItem(key, JSON.stringify(valueToStore));
} catch (error) {
console.error(`Error setting localStorage:`, error);
}
};
return [storedValue, setValue];
}
// 使用例
const UserSettings = () => {
const [theme, setTheme] = useLocalStorage<"light" | "dark">("theme", "light");
return (
<button onClick={() => setTheme(theme === "light" ? "dark" : "light")}>
Toggle theme: {theme}
</button>
);
};
useApi Hook
import { useState, useEffect } from "react";
interface UseApiResult<T> {
data: T | null;
loading: boolean;
error: Error | null;
refetch: () => void;
}
function useApi<T>(url: string): UseApiResult<T> {
const [state, setState] = useState<{
data: T | null;
loading: boolean;
error: Error | null;
}>({ data: null, loading: true, error: null });
const fetchData = async () => {
try {
setState((prev) => ({ ...prev, loading: true, error: null }));
const response = await fetch(url);
if (!response.ok) throw new Error(`HTTP ${response.status}`);
const data: T = await response.json();
setState({ data, loading: false, error: null });
} catch (error) {
setState({
data: null,
loading: false,
error: error instanceof Error ? error : new Error("Unknown error"),
});
}
};
useEffect(() => {
fetchData();
}, [url]);
return { ...state, refetch: fetchData };
}
型定義ファイルの管理
プロジェクト構造
src/
├── types/
│ ├── index.ts # 再エクスポート
│ ├── user.ts # ユーザー型
│ └── api.ts # API型
├── components/
└── hooks/
型定義の例
// src/types/user.ts
export interface User {
id: number;
name: string;
email: string;
role: "admin" | "user" | "guest";
}
export interface CreateUserRequest {
name: string;
email: string;
password: string;
}
// src/types/api.ts
export interface ApiResponse<T> {
data: T;
status: "success" | "error";
message?: string;
}
// src/types/index.ts
export * from "./user";
export * from "./api";
型ガードと型の絞り込み
型ガード関数
export function isUser(value: unknown): value is User {
return (
typeof value === "object" &&
value !== null &&
"id" in value &&
"name" in value &&
"email" in value
);
}
// 使用例
const processUserData = (data: unknown) => {
if (isUser(data)) {
console.log(`User: ${data.name}`);
}
};
高度なTypeScript機能
ユーティリティ型
よく使う組み込み型
interface User {
id: number;
name: string;
email: string;
password: string;
}
// Partial - すべてオプショナル
type PartialUser = Partial<User>;
// Pick - 特定のプロパティのみ
type PublicUser = Pick<User, "id" | "name" | "email">;
// Omit - 特定のプロパティを除外
type UserWithoutPassword = Omit<User, "password">;
// Required - すべて必須
type RequiredUser = Required<Partial<User>>;
条件型とマップ型
// 条件型
type NonNullable<T> = T extends null | undefined ? never : T;
// マップ型
type ReadOnly<T> = {
readonly [K in keyof T]: T[K];
};
type PickByType<T, U> = {
[K in keyof T as T[K] extends U ? K : never]: T[K];
};
トラブルシューティング
よくある問題と解決法
-
any型の乱用
// ❌ 悪い例 const fetchData = (): any => { // ... }; // ✅ 良い例 interface ApiResponse<T> { data: T; status: number; } const fetchData = <T,>(): Promise<ApiResponse<T>> => { // ... }; -
null/undefined エラー
// ❌ 危険 const getUserName = (user: User | null) => { return user.name; // user が null の可能性 }; // ✅ 安全 const getUserName = (user: User | null): string | null => { return user?.name ?? null; }; -
型アサーションの過度な使用
// ❌ 危険 const data = response as User; // ✅ 安全 const isUser = (data: unknown): data is User => { // 型ガード実装 }; if (isUser(data)) { // data は User 型として使用可能 }
まとめ
TypeScriptの利点:
- ✅ 型安全性: コンパイル時のエラー検出でバグ予防
- ✅ 開発効率: IntelliSense・リファクタリング支援
- ✅ 可読性: 型情報がドキュメントとして機能
- ✅ スケーラビリティ: 大規模開発での保守性向上
導入のベストプラクティス:
- 段階的な導入で学習コストを分散
- strict モードで厳密な型チェック
- 適切な型定義ファイル管理
- ユーティリティ型の活用でDRY原則
Biomeによるコード品質管理
この章では、コードの品質を自動的にチェック・整形してくれる「Biome」について一緒に学んでいきましょう。Biomeは比較的新しいツールですが、従来のESLintやPrettierよりもずっと高速で、設定も簡単です。使い始めると、コードがとてもきれいに保たれるようになりますよ。
学習目標
- Biomeを使ったコードチェックと整形方法を覚える
- ESLintやPrettierの代わりとしてBiomeを使う
- コードの品質を自動で保つ仕組みを理解する
- エディタとの連携やチーム開発での活用方法を学ぶ
Biomeって何?
基本的な概念
Biomeは、JavaScript、TypeScript、JSON、CSSのコードを「きれいに」「正しく」してくれるツールです。従来は複数のツールを組み合わせて使っていた機能を、一つのツールで提供してくれます。
Biomeの魅力
- とても高速: Rustという言語で作られているので、従来ツールより10倍以上速い
- オールインワン: リンティング・フォーマット・import整理を一つで
- 設定不要: デフォルトの設定ですぐに使える
- エディタ連携: VS Codeでリアルタイムにチェックしてくれる
- 簡単導入: 既存のプロジェクトにも簡単に追加できる
従来のツールとの比較
今まではいくつかのツールを組み合わせる必要がありました:
| 機能 | ESLint | Prettier | Biome |
|---|---|---|---|
| コードチェック | ✅ | ❌ | ✅ |
| 見た目整形 | 一部 | ✅ | ✅ |
| 処理速度 | 普通 | 普通 | とても速い |
| 設定の難しさ | 複雑 | 簡単 | とても簡単 |
| プラグイン依存 | 多い | 少ない | なし |
Biome一つで全部できるので、覚えることが少なくて済みますね。
Biomeをインストールしよう
1. プロジェクトへのインストール
pnpm add -D @biomejs/biome
2. 初期設定
# Biome設定ファイルの生成
npx @biomejs/biome init
3. package.jsonスクリプト設定
{
"scripts": {
"lint": "biome lint ./src",
"lint:fix": "biome lint --write ./src",
"format": "biome format ./src",
"format:fix": "biome format --write ./src",
"check": "biome check ./src",
"check:fix": "biome check --write ./src"
}
}
コマンドラインでの実行
リンティング
# リンティングチェック
pnpm run lint
# 自動修正付きリンティング
pnpm run lint:fix
# 特定ファイルのリンティング
pnpm exec biome lint src/App.tsx
フォーマッティング
# フォーマットチェック
pnpm run format
# フォーマット適用
pnpm run format:fix
# 特定ファイルのフォーマット
pnpm exec biome format --write src/App.tsx
統合コマンド(推奨)
# リンティング・フォーマット・import整理を一括実行
pnpm run check:fix
# ドライラン(何が変更されるかプレビュー)
pnpm run check
2. 基本的な設定例
基本的なbiome.json
{
"$schema": "https://biomejs.dev/schemas/2.0.5/schema.json",
"formatter": {
"enabled": true
},
"linter": {
"enabled": true
},
"assist": {
"enabled": true
}
}
エディタ統合
VS Code 設定
拡張機能のインストール
# VS Code拡張機能
code --install-extension biomejs.biome
settings.json
{
// Biome を優先フォーマッタに設定
"editor.defaultFormatter": "biomejs.biome",
// 保存時にフォーマット適用
"editor.formatOnSave": true,
// 保存時にコード修正
"editor.codeActionsOnSave": {
"quickfix.biome": "explicit",
"source.organizeImports.biome": "explicit"
},
// 他のフォーマッタを無効化
"prettier.enable": false,
"eslint.enable": false
}
トラブルシューティング
よくある問題と解決法
特定ルールの無効化
// ファイル全体で無効化
// @biome-ignore lint/suspicious/noExplicitAny: legacy code
// 行単位で無効化
const data: any = getValue(); // @biome-ignore lint/suspicious/noExplicitAny: external API
フォーマット結果が期待と違う
{
"formatter": {
"indentStyle": "space",
"indentSize": 2,
"lineWidth": 100,
"ignore": ["**/*.generated.ts"]
}
}
まとめ
この章で学んだポイント:
- Biomeの基本: リンティング・フォーマット・import整理を一つのツールで可能
- インストールと設定:
pnpm add -D @biomejs/biomeとnpx @biomejs/biome initで簡単導入 - VS Code連携: 保存時に自動でコード品質チェック・整形
- 実践的な使い方:
pnpm run check:fixでコード品質を自動改善
Biomeを使うことで、コードの品質を保ちながら、フォーマットやリンティングの設定に悩む時間を減らせます。まずはVS Codeの拡張機能をインストールして、保存時の自動フォーマットから試してみましょう!
AI支援ツール活用法
AI支援ツールは、コーディング作業を支援してくれる強力なツールです。コード補完、リファクタリングの提案、バグ修正、ドキュメント生成など、様々な場面で活躍します。 ここでは主要なAI支援ツールの導入方法と使い方を学びましょう。
AI支援ツールの導入
# Claude Code
npm i -g @anthropic-ai/claude-code
# インストール後 claude コマンドで起動
# Codex
npm i -g @openai/codex
# インストール後 codex コマンドで起動
# GitHub Copilot CLI
npm i -g @github/copilot
# インストール後 copilot コマンドで起動
# Google Antigravity CLI
curl -fsSL https://antigravity.google/cli/install.sh | bash
# インストール後 agy コマンドで起動
学習リソース
プロジェクトでの活用例
実際のプロジェクトで活用する場合の例:
# プロジェクトディレクトリで起動
cd your-project
claude
# 例: HTMLファイルの生成
> 簡単なHTMLファイルを作成して
# 例: ファイルの検索
> このディレクトリにあるJavaScriptファイルを一覧表示して
# 例: 依存関係の説明
> package.jsonを読んで、使用している依存関係を説明して
# 例: コンポーネントの生成
> Reactのユーザープロフィールコンポーネントを作成して
> 名前、メールアドレス、アバター画像を表示する機能が欲しい
# 例: バグ修正の支援
> src/utils/formatDate.jsにバグがあるみたい。確認して修正して
# 例: リファクタリング
> このファイルのコードをTypeScriptに変換して、型定義も追加して
指示に応じて適切なファイル操作やコード生成を行ってくれます。
注意点
AI支援ツールは強力ですが、いくつか注意すべき点があります:
セキュリティ
- 機密情報を含めない: APIキーやパスワードなどの機密情報をプロンプトに含めないようにしましょう
- 依存関係の確認: 生成されたコードが安全なライブラリやフレームワークを使用しているか確認しましょう
効果的な使い方
- 具体的な指示: 曖昧な指示より具体的な指示の方が良い結果が得られます
- コンテキストの提供: 関連するファイルや要件を明示することで、より適切な提案が得られます
コードの品質管理
- 生成コードのレビュー: AIが生成したコードは必ず自分で確認しましょう
- テストの実施: 生成されたコードが期待通り動作するかテストしましょう
ポイント
- AI支援ツールを使う際は、セキュリティとコード品質に注意が必要
- 具体的な指示とコンテキスト提供で、より良い結果が得られる
- 生成されたコードは必ずレビューとテストを行う
基本的な開発の流れ
この章では、Web開発の基本的な流れについて学びましょう。最初は工程が多く感じるかもしれませんが、一つずつ理解していけば、効率的で安全な開発ができるようになります。
学習目標
- モダンなWeb開発の作業の流れを理解する
- コードを書いてから公開するまでの工程を知る
- チームで効率的に開発する方法を学ぶ
現代のソフトウェア開発
- 変化の加速: 技術革新や市場の需要は急速に変化しており予測可能性は低下
- エコシステムの複雑化: マイクロサービス、クラウド、モバイル、IoTなど、多様な技術が絡み合うことで、システム全体の複雑さは増加
- 利用者中心の要求: ユーザーエクスペリエンスの重要性が高まり、迅速なフィードバックループを通じた継続的な改善が求められるように
開発の全体像
前提
これから紹介する一連の開発の流れはあくまで一例です。 実践の方法は現場によって異なります。そして最も大切な点はまず現実の問題に向き合い然るべき価値を提供するということです。
開発から公開までの流れ

開発者がやること
- 計画: どんな機能を作るか考える
- 開発: 実際にコードを書く
- テスト: 正しく動くか確認する
- レビュー: 他の人にコードを見てもらう
- 公開: ユーザーが使えるようにする
1. 計画:何を作るか決める
Issue(課題)を作る
GitHubで「これを作りたい」「これを修正したい」という課題(Issue)を作ります。
## やりたいこと
ユーザープロフィール画面を追加したい
## 詳細
- ユーザー名を表示
- アイコン画像を表示
- 自己紹介文を表示
## 確認事項
- [ ] デザインは決まっているか
- [ ] データはどこから取得するか
- [ ] 編集機能は必要か
タスクを分解する
大きな機能は小さなタスクに分けると、進めやすくなります。
プロフィール画面の作成
├─ プロフィールページのUI作成
├─ ユーザーデータ取得API連携
├─ 画像アップロード機能
└─ プロフィール編集機能
2. 開発:コードを書く
ブランチを作る
まず、作業用のブランチを作ります。
# mainブランチから最新のコードを取得
git checkout main
git pull origin main
# 新しいブランチを作成
git checkout -b feature/user-profile
コードを書く
開発を進めていきます。
# 開発サーバーを起動
pnpm run dev
# ブラウザで確認しながらコードを書く
# http://localhost:5173
こまめに保存(コミット)する
# 変更したファイルを確認
git status
# 変更を追加
git add src/pages/Profile.tsx
# コミット(保存)
git commit -m "feat: add user profile page UI"
コミットメッセージの書き方:
feat: 新機能の追加
fix: バグ修正
docs: ドキュメント更新
style: コードの見た目の修正(動作は変わらない)
refactor: コードの整理
test: テストの追加・修正
3. テスト:動作確認する
手動テスト
実際にブラウザで動かして確認します。
# 開発サーバーで確認
pnpm run dev
# 本番環境に近い状態で確認
pnpm run build
pnpm run preview
確認項目:
- ✅ 画面が正しく表示されるか
- ✅ ボタンを押したら期待通りの動作をするか
- ✅ エラーが出ていないか
- ✅ スマホでも正しく表示されるか
自動テスト(慣れてきたら)
コードが正しく動くか、自動でチェックできます。
# テストを実行
pnpm run test
# 型チェック
pnpm run type-check
# コード品質チェック
pnpm run check
4. レビュー:見てもらう
GitHubにプッシュする
# リモートにプッシュ
git push origin feature/user-profile
Pull Requestを作る
GitHubでPull Request(PR)を作成します。
## 変更内容
ユーザープロフィール画面を追加しました
## スクリーンショット
(画面のスクリーンショットを貼る)
## 確認方法
1. ログインする
2. 右上のアイコンをクリック
3. 「プロフィール」をクリック
## チェックリスト
- [x] 動作確認済み
- [x] テスト追加済み
- [x] ドキュメント更新済み
レビューを受ける
チームメンバーがコードを確認してくれます。
よくあるレビューコメント:
- 「この部分、もっとシンプルに書けそう」
- 「エラー処理を追加した方がいいかも」
- 「変数名をもっとわかりやすくしよう」
修正する
レビューでの指摘を修正します。
# コードを修正
# 修正をコミット
git add .
git commit -m "fix: improve error handling"
# プッシュ
git push origin feature/user-profile
5. 公開:ユーザーに届ける
マージする
レビューが承認されたら、mainブランチにマージします。
# GitHubのUIで「Merge Pull Request」ボタンをクリック
自動デプロイ
mainブランチにマージされると、自動的に公開されます(CI/CDが設定されている場合)。
GitHubにプッシュ
↓
自動でテスト実行
↓
テストが成功
↓
自動でビルド
↓
自動で公開(デプロイ)
↓
ユーザーが使える!
よくある開発パターン
パターン1:小さな修正
# ブランチ作成
git switch -c fix/button-color
# 修正
# (コードを修正)
# コミット・プッシュ
git add .
git commit -m "fix: change button color to blue"
git push origin fix/button-color
# PR作成 → レビュー → マージ
パターン2:新機能の追加
# Issue作成(GitHubで)
# ブランチ作成
git switch -c feature/search-function
# 開発
# (複数回コミット)
git commit -m "feat: add search UI"
git commit -m "feat: add search API"
git commit -m "test: add search tests"
# テスト実行
pnpm run test
pnpm run check
# プッシュ
git push origin feature/search-function
# PR作成 → レビュー → 修正 → マージ
チーム開発のルール
1. mainブランチは常に動く状態にする
- mainブランチに直接コミットしない
- 必ずブランチを作って作業する
- PRでレビューを受けてからマージ
2. わかりやすいコミットメッセージを書く
良い例:
git commit -m "feat: add user login functionality"
git commit -m "fix: resolve profile image upload error"
悪い例:
git commit -m "update"
git commit -m "fix bug"
3. 小さく分けて、こまめにコミット
良い例:
git commit -m "feat: add login form UI"
git commit -m "feat: add login validation"
git commit -m "feat: add login API integration"
悪い例:
# 1週間分の変更を一度にコミット
git commit -m "add login feature"
4. PRは早めに作る
- 完成してからPRを作るのではなく
- 早めに作って「Draft PR」として共有
- 途中でも見てもらえる
便利なツール
開発を助けるツール
| ツール | 用途 | コマンド例 |
|---|---|---|
| Vite | 開発サーバー・ビルド | pnpm run dev |
| Biome | コード品質チェック | pnpm run check |
| TypeScript | 型チェック | pnpm run type-check |
| Vitest | テスト実行 | pnpm run test |
| Git | バージョン管理 | git status |
よく使うコマンド
# 開発開始
pnpm run dev
# コード品質チェック
pnpm run check
# 自動修正
pnpm run check:fix
# テスト実行
pnpm run test
# ビルド
pnpm run build
トラブルシューティング
1. コミットできない
# エラー: コード品質チェックで失敗
# 自動修正を試す
pnpm run check:fix
# それでもダメなら、エラー内容を確認して手動で修正
pnpm run check
2. ブランチを間違えた
# 現在のブランチを確認
git branch
# 正しいブランチに切り替え
git switch feature/correct-branch
# ブランチを作り直す場合
git switch main
git switch -c feature/new-branch
3. コンフリクトが起きた
# mainの最新を取得
git checkout main
git pull origin main
# 自分のブランチに戻る
git checkout feature/my-branch
# mainの変更を取り込む
git merge main
# コンフリクトを解消(ファイルを手動で編集)
# <<<<<<< HEAD と >>>>>>> の部分を修正
# 解消後、コミット
git add .
git commit -m "merge: resolve conflicts with main"
ポイント
この章で学んだことをまとめます。
開発の流れ:
- 計画: Issueで何を作るか決める
- 開発: ブランチを作ってコードを書く
- テスト: 動作確認とコード品質チェック
- レビュー: PRを作ってチームに見てもらう
- 公開: マージして自動デプロイ
大切なこと:
- ✅ mainブランチは常に動く状態を保つ
- ✅ 小さく分けて、こまめにコミット
- ✅ わかりやすいメッセージを書く
- ✅ 早めにPRを作って相談する
- ✅ レビューは学びの機会
使うツール:
- Git: バージョン管理
- GitHub: コード共有・レビュー
- Vite: 開発サーバー
- Biome: コード品質チェック
- TypeScript: 型チェック
最初は覚えることが多くて大変かもしれませんが、この流れに慣れると、安全で効率的な開発ができるようになります。チームで協力しながら、少しずつ慣れていきましょう!
Reactフロントエンド開発入門
REST APIと非同期処理
- REST API基礎
- HTTPリクエストとJSON
- GitHubで学ぶREST API実践
- fetch APIの基本
- useEffectによる非同期処理
- useSWR入門
- TanStack Query入門
- プロキシ確認ガイド
REST API基礎
Web開発において重要なREST APIの基本的な概念と仕組みについて学んでいきましょう。REST APIを理解することで、Webアプリケーション開発の土台を築けます。
なぜREST APIが必要なのか
現代のWebアプリケーション(TwitterやInstagram、Googleマップなど)を使うとき、画面を操作するだけでデータが表示されたり更新されたりしますよね。 もし、これらのアプリケーションがサーバーとデータをやり取りするための共通のルールがなければ、開発は非常に複雑で非効率的になります。
REST APIを使うことで、開発者は以下のメリットを得られます:
- 関心の分離 … フロントエンドとバックエンドでの独立した開発が可能
- マルチプラットフォーム対応 … Web、iOS、Androidで同じAPIを利用可能
- 外部サービス連携 … ログインにGoogleやFacebookアカウントを使うなど、他サービスとの連携が可能
REST APIとは
REST(Representational State Transfer)APIは、Webサービス間でのデータのやり取りを行うための非常にシンプルなアーキテクチャパターンです。簡単に言うと、「統一されたルールに基づいてデータを取得・送信する仕組み」というわけです。
HTTPメソッドの基本
REST APIは主に以下のHTTPメソッドを使ってリソースを操作します:
CRUD操作とHTTPメソッドの対応
| 操作 | HTTPメソッド | 意味 | 例 |
|---|---|---|---|
| Create | POST | 新しいリソースを作成 | ユーザー登録 |
| Read | GET | リソースを取得 | ユーザー情報の表示 |
| Update | PUT/PATCH | リソースを更新 | プロフィール変更 |
| Delete | DELETE | リソースを削除 | アカウント削除 |
実際のAPIエンドポイントの例
GET /api/users # 全ユーザーの一覧を取得
GET /api/users/123 # ID 123のユーザー情報を取得
POST /api/users # 新しいユーザーを作成
PUT /api/users/123 # ID 123のユーザー情報を更新
DELETE /api/users/123 # ID 123のユーザーを削除
見覚えのあるパターンですよね。この一貫性がRESTの魅力です。
ステータスコード
APIからのレスポンスには、処理結果を示すHTTPステータスコードが付きます。例えば:
- 200 OK:成功
- 404 Not Found:リソースが見つからない
- 500 Internal Server Error:サーバーエラー
ステータスコードの詳細や実際の使い分けについては、次の記事で学びます。
JSON形式でのデータ交換
REST APIでは、JSONフォーマットでデータのやり取りを行うのが一般的です。JSONは読みやすく、JavaScriptとの相性も抜群です(便利ですよね)。
JSONの詳しい構造や実際のJavaScriptでの扱い方については、次の記事で詳しく学びます。
実際のREST APIの例
JSONPlaceholder API
練習によく使われる無料のテストAPIをご紹介します:
GET https://jsonplaceholder.typicode.com/posts/1
このリクエストを送ると、以下のようなレスポンスが返ってきます:
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum..."
}
やってみよう!
ブラウザで以下のURLにアクセスしてみてください:
実際のJSON形式のデータが確認できます。これがREST APIの基本的な動作です。
REST APIの設計原則
リソース指向の設計
- URLはリソース(モノ)を表現します
- 動詞ではなく名詞を使用します
Good: GET /api/users/123
Bad: GET /api/getUser?id=123
ネストしたリソースの表現
関連するリソースは階層構造で表現します:
GET /api/users/123/posts # ユーザー123の投稿一覧
GET /api/posts/456/comments # 投稿456のコメント一覧
認証とセキュリティ
実際のAPIを使う際には、認証が必要になることがあります。
Note: 多くの公開APIでは、リクエストヘッダーにAPIキーを含めて認証を行います。また、APIには通常リクエスト回数の制限(レート制限)があるため、利用規約を確認しましょう。セキュリティ上、APIキーは環境変数で管理し、コードに直接書かないようにしましょう。
ポイント(まとめ)
REST APIは、現代のWeb開発においてフロントエンドとバックエンドを分離し、複数のプラットフォームで同じデータを活用するための重要な仕組みです。統一されたルールに基づくことで、開発の効率化や保守性の向上を実現できます。
- REST APIの必要性: フロントエンドとバックエンドの分離、複数プラットフォーム対応、外部サービス連携を可能にする
- REST API: Web上でデータをやり取りするための統一された設計原則・方式
- HTTPメソッド: GET(取得)、POST(作成)、PUT(更新)、DELETE(削除)といった操作を表す
- ステータスコード: リクエストの処理結果を示す3桁の数字(例:200 OK、404 Not Found)
- JSON形式: APIにおける標準的なデータ交換フォーマット
- リソース指向: URLは操作ではなく、対象となるリソース(モノ)を表現する
次のステップ
次は HTTPリクエストとJSON で、HTTPの詳しい仕組みとJSONデータの扱い方を実践的に学んでいきます。開発者ツールを使い、実際のAPI通信を確認しながら理解を深めていきましょう。
HTTPリクエストとJSON
前回の REST API基礎 で、REST APIの概念とメリットを学びました。今回は、HTTPリクエストの詳しい仕組みとJSONデータの実践的な扱い方を身につけます。実際に動かしながら気楽にいきましょう。
この記事で学べること
- HTTPリクエスト/レスポンスのしくみ(メソッド・URL・ヘッダーフィールド・ボディ)
- ステータスコードとContent-Type
- JSONの基本と注意点(数値/日付/ネスト)
- ブラウザとJavaScriptでJSONを扱う実例
- 実践的なパターン(認証、クエリパラメータ、エラーハンドリング、複数API呼び出し)
HTTPのしくみを分解
HTTP(HyperText Transfer Protocol)は、クライアント(例: ブラウザ)とサーバーが会話するためのルールです。会話の1往復をもう少し細かく見てみましょう。
プロトコル
― この画像は © 2012 Karl Dubost クリエイティブ・コモンズ CC BY 3.0 ライセンスのもとに利用を許諾されています。
二者間でのコミュニケーションが成立するためには3つの要素が含まれています。
- シンタックス (コードの文法)
- セマンティクス (コードの意味)
- タイミング (速度合わせと順序付け)
「挨拶」を例に考えてみましょう。 腰を曲げるジェスチャー、これはお辞儀のためのシンタックスです。日本ではそういう慣習ですね。お辞儀をすることで「どうも、こんにちは」という意味づけが行われます。これはセマンティクスです。二者間で特定のタイミングでこれらが発生したとき、一連の出来事として成立します。どちらもお辞儀をし、お互いに理解することによって「挨拶」として成立した、となるわけです。
Web上でのやり取りも同じです。 HTTPはサーバー・クライアントの二者関係で行われます。 クライアントはサーバーに対して要求を送り、クライアントからの要求を受け取るとサーバーは応答を返します。
HTTPの仕様にある具体例を挙げます。 次のようなコードの送受信を行います。
リクエストの構成
- メソッド: 何をしたいか(GET/POST/PUT/PATCH/DELETE など)
- URL: どこに(https://www.example.com/hello.txt など)
- ヘッダー: 追加情報(認証やデータ形式)※HTTP/1.1仕様では「ヘッダーフィールド (Header Fields)」とも表記されます
- ボディ: 本文(POST/PUT で送るJSONなど)
具体例:
GET /hello.txt HTTP/1.1
User-Agent: curl/7.64.1
Host: www.example.com
Accept-Language: en, mi
Note
HTTP/1.1 と HTTP/2HTTP/1.1は1995年に公開され、2022年に最新版に改定されました。 HTTP/1.1は現在も使われ続けています。 一方、HTTP/2は2022年に公開されました。 HTTP/2はHTTP/1.1とは異なり複数のメッセージを同時に扱える、コンピューターにとってより効率的な形式の仕様です。 HTTP/2ではリクエストラインの代わりに一貫してフィールドを使うなどHTTP/1.1と文法が大きく異なりますがその意味は全く変わりません。
GET /resource HTTP/1.1 HEADERS Host: example.org ==> + END_STREAM Accept: image/jpeg + END_HEADERS :method = GET :scheme = https :authority = example.org :path = /resource host = example.org accept = image/jpeg
レスポンスの構成
- ステータスライン: (例) HTTP/1.1 200 OK
- ヘッダーフィールド: (例) Content-Type: text/plain
- ボディ: データ本体
具体例:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
Hello World! My content includes a trailing CRLF.
ステータスコード (Status Codes)
― 画像: HTTP Cats より

「ステータスコード (Status Codes)」はそのリソースの存在やアクセス可否などをサーバーが伝えるためのものです。 サーバーはレスポンスを返すとき、最初にステータスコードを返します。
サーバーレスポンス:
HTTP/1.1 200 OK
この例ではステータスコード 200 を返しています。
ステータスコードは100〜599までの3桁の整数で表されます。
レスポンスはステータスコードの100の位で大きく分類されます。
- 1xx (情報): リクエストを受信しました。プロセスを続行します。
- 2xx (成功): リクエストは正常に受信、理解され、受け入れられました。
- 3xx (リダイレクト): リクエストを完了するにはさらにアクションを実行する必要があります。
- 4xx (クライアントエラー): リクエストに不正な構文が含まれているか、リクエストを実行できません。
- 5xx (サーバーエラー): サーバーは有効なリクエストを実行できません。
Note
418 I’m a teapot私はティーポットなのでコーヒーを入れることを拒否しました、という意味のステータスコードです。 1998年のエイプリルフールに公開されました。 現在でもステータスコード
418は IANA HTTP Status Code Registry によって管理されています。
JSONの基本(JavaScript Object Notation)
JSONは「データをテキストで表す決まり」です。JavaScriptとの相性が良く、Web APIでよく使われます。
よく使う型
- オブジェクト:
{ "id": 1, "name": "Taro" } - 配列:
[1, 2, 3]や[{"id":1},{"id":2}] - 文字列/数値/真偽値/null:
"hello",42,true,null
Note: JSONに日付型はありません。通常はISO文字列(例:
"2025-01-01T00:00:00Z")として扱い、必要に応じてアプリ側でDate型に変換します。
具体例:公開APIを叩いてみる
まずは読み取りだけの安全なAPIで体験しましょう。学習用途で有名なJSONPlaceholderを使います。
エンドポイント例:
ブラウザでURLを開くだけでもOKです。ネットワーク通信を詳しく見たいときは、Chromeの開発者ツール > Network タブを開いてみましょう(面白いですよ)。
レスポンス例(抜粋):
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit..."
}
JavaScriptでJSONを扱う
JavaScriptではfetchを使って簡単にJSONを取得できます。
基本のパターン
async function getData() {
const res = await fetch("https://jsonplaceholder.typicode.com/posts/1");
if (!res.ok) {
throw new Error(`HTTP ${res.status}`);
}
// res.text() ではなく res.json() なのがポイント
const data = await res.json();
return data;
}
const data = await getData();
console.log(data);
console.log(typeof data);
この例では:
fetch()でURLにリクエストを送るres.okでステータスコードが2xxかどうか確認res.json()でJSONをJavaScriptオブジェクトに変換
Content-Typeを確認する
レスポンスが本当にJSONかどうか確認してからres.json()を呼ぶと安全です。
async function getData() {
const res = await fetch("https://jsonplaceholder.typicode.com/posts/1");
const contentType = res.headers.get("content-type");
if (contentType && contentType.includes("application/json")) {
return await res.json();
} else {
return await res.text();
}
}
const data = await getData();
console.log(data);
console.log(typeof data); // "object" か "string"
なぜこうするのか:サーバーがエラーメッセージをHTMLやテキストで返すことがあります。そのときにres.json()を呼ぶとエラーになるため、Content-Typeヘッダーで判断します。
リクエストボディにJSONを送る(POSTの例)
データを送るときはmethodとheaders、bodyを指定します。
async function createPost(post) {
const res = await fetch("https://jsonplaceholder.typicode.com/posts", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(post),
});
if (!res.ok) {
throw new Error(`HTTP ${res.status}`);
}
return await res.json();
}
const data = await createPost({ title: "Hello", body: "World", userId: 1 });
console.log(data);
ポイント:
method: "POST"→ サーバーにデータを送るContent-Type: application/json→ 送るデータの形式を伝えるJSON.stringify(post)→ JavaScriptオブジェクトをJSON文字列に変換
Note:
JSON.stringifyを忘れると、サーバーは[object Object]という文字列を受け取ってしまい、400エラーになることがあります。
ステータスコードとエラーの見分け方
- 2xx: 成功 →
res.okがtrue - 4xx: クライアント側の問題 →
res.okがfalse - 5xx: サーバー側の問題 →
res.okがfalse
JavaScriptのfetchは、ネットワークに到達できれば例外を投げません。つまりHTTP 404やHTTP 500でもres.okがfalseになるだけです(ちょっと紛らわしいですよね)。
だから、必ずres.okをチェックしましょう:
async function fetchUser(id) {
const res = await fetch(`https://jsonplaceholder.typicode.com/users/${id}`);
if (!res.ok) {
throw new Error(`エラー: HTTP ${res.status}`);
}
return await res.json();
}
// 使用例
const data = await fetchUser(9999);
console.log(data);
なぜこうするのか:res.okをチェックしないと、404エラーでもres.json()を呼んでしまい、意図しない動作になります。
やってみよう!
- ブラウザで
https://jsonplaceholder.typicode.com/usersを開く - Chrome開発者ツールのNetworkタブでレスポンスヘッダー(Content-Type)を確認
fetchで同じURLを読み込み、配列長をconsole.logしてみる
const res = await fetch("https://jsonplaceholder.typicode.com/users");
const data = await res.json();
console.log("件数:", data.length);
実践的なパターン
ここまでの基礎を踏まえて、実際のアプリ開発でよく使うパターンを見ていきましょう。
認証が必要なAPIを呼び出す
多くの実用的なAPIでは、API キーやトークンを使った認証が必要です。これらはAuthorizationヘッダーに含めて送ります。
async function fetchWithAuth() {
const res = await fetch("https://api.example.com/user/profile", {
headers: {
Authorization: "Bearer YOUR_API_TOKEN",
},
});
if (!res.ok) {
throw new Error(`HTTP ${res.status}`);
}
return await res.json();
}
await fetchWithAuth();
なぜこうするのか:サーバーはAuthorizationヘッダーで「誰がアクセスしているか」を確認します。Bearerはトークン認証の標準的な方式です。
Note: APIキーやトークンは環境変数(
.envファイル)で管理し、コードに直接書かないようにしましょう。GitHubなどに誤って公開してしまうと、第三者に悪用される危険があります。
クエリパラメータでデータを絞り込む
GETリクエストでは、URLにパラメータを付けてデータを絞り込むことができます(検索機能やページネーションで頻繁に使います)。
// 手動でURLを組み立てる方法
const userId = 1;
const res = await fetch(
`https://jsonplaceholder.typicode.com/posts?userId=${userId}`,
);
// URLSearchParamsを使う方法(推奨)
const query = new URLSearchParams({ userId: 1, _limit: 5 });
const res2 = await fetch(
`https://jsonplaceholder.typicode.com/posts?${query}`,
);
const data = await res2.json();
console.log(data); // 最大5件のデータが返ってくる
なぜこうするのか:URLSearchParamsを使うと、特殊文字のエンコード(例:スペースを%20に変換)を自動でやってくれるため安全です。
ステータスコードに応じたエラー処理
基本のres.okチェックに加えて、ステータスコードごとに適切なエラーメッセージを返すとユーザー体験が向上します。
async function fetchWithDetailedError(url) {
const res = await fetch(url);
if (!res.ok) {
// ステータスコードごとに適切なエラーメッセージを返す
switch (res.status) {
case 400:
throw new Error("リクエストが不正です");
case 401:
throw new Error("認証が必要です");
case 404:
throw new Error("データが見つかりません");
case 500:
throw new Error("サーバーエラーが発生しました");
default:
throw new Error(`HTTP ${res.status}`);
}
}
return await res.json();
}
// サーバーエラーが発生!
await fetchWithDetailedError("https://httpbin.org/status/500");
なぜこうするのか:エラーの原因が分かれば、ユーザーに「再ログインしてください」「URLを確認してください」といった具体的な対処法を案内できます。
複数のAPIを順番に呼び出す
実際のアプリ開発では、1つのリソースに関連する複数のデータを取得することがよくあります。
async function getUserWithPosts(userId) {
try {
// 1. ユーザー情報を取得
const userRes = await fetch(
`https://jsonplaceholder.typicode.com/users/${userId}`,
);
if (!userRes.ok) throw new Error("ユーザー情報の取得に失敗");
const user = await userRes.json();
// 2. そのユーザーの投稿を取得
const postsRes = await fetch(
`https://jsonplaceholder.typicode.com/posts?userId=${userId}`,
);
if (!postsRes.ok) throw new Error("投稿の取得に失敗");
const posts = await postsRes.json();
// 3. データを結合して返す
return { ...user, posts };
} catch (error) {
console.error("エラー:", error);
throw error;
}
}
// 使用例
const data = await getUserWithPosts(1);
console.log(`${data.name}さんの投稿数: ${data.posts.length}`);
なぜこうするのか:ユーザーのプロフィールページを表示するとき、「ユーザー情報」と「そのユーザーの投稿一覧」を両方取得する必要があります。このように複数のAPIを組み合わせることで、より豊かなアプリケーションが作れます。
ポイント(まとめ)
- HTTPは「メソッド・URL・ヘッダー・ボディ」のセット
- JSONはテキスト表現のオブジェクト。日付は文字列で扱うのが基本
Content-Typeを見て正しくパース(response.json()orresponse.text())fetchは404でも例外にしない。res.okを必ず確認- 送信時は
Content-Type: application/jsonとJSON.stringifyを忘れずに
GitHubで学ぶREST API実践
GitHub の REST API を題材に fetch API で扱う基礎をまとめました。認証 (PAT) の扱い、代表的なエンドポイント、トラブルシューティングまで一気に押さえます。
この記事で学べること
- 読み取りAPI (非認証) と認証APIの違い
- Personal Access Token (PAT) の発行と安全な使い方
GitHub APIの基本 (非認証と認証)
非認証でできること (読み取り)
公開情報 (ユーザーや公開リポジトリなど) はトークンなしで取得できます。ただしレート制限が厳しめです (未認証はおおむね1時間に60リクエスト程度)。
const res = await fetch("https://api.github.com/users/octocat");
const data = await res.json();
console.log(data.login, data.public_repos);
認証 (PAT)
- GitHub PAT発行ページ にアクセス。
Generate new tokenをクリック。- トークンの名前を指定。
- トークンを生成し、表示された値をメモします。(※ 生成したトークンは安全に保管 (環境変数など)。フロントエンドに埋め込まないこと。)
- 参考: GitHubトークンの作成ガイド
fetchでGitHub APIを叩く (サーバー側推奨)
トークンは環境変数で管理し、サーバー側から呼び出すのが原則です。
// 自分のユーザー情報を取得 (認証が必要)
const token = process.env.GITHUB_TOKEN as string;
const res = await fetch("https://api.github.com/user", {
headers: {
Authorization: `Bearer ${token}`,
Accept: "application/vnd.github+json",
},
});
const me = await res.json();
代表的なエンドポイント:
- ユーザー情報: GET
/users/{username}(公開) / GET/user(認証) - リポジトリ一覧: GET
/users/{username}/repos - Issue作成: POST
/repos/{owner}/{repo}/issues
// Issue作成 (サーバー側で実行)
await fetch("https://api.github.com/repos/OWNER/REPO/issues", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.GITHUB_TOKEN}`,
Accept: "application/vnd.github+json",
"Content-Type": "application/json",
},
body: JSON.stringify({ title: "バグ報告", body: "再現手順..." }),
});
トラブルシューティング
- 401/403: 認証情報不足。
Authorizationヘッダー、トークンスコープ、レート制限を確認 - 422 Unprocessable Entity: 入力不足・不正。必須パラメータやJSONの形を見直す
- レート制限: 未認証は特に制限が厳しい。認証+適切なヘッダーを付与
やってみよう!
- 非認証で
/users/octocatを取得し、public_reposを表示 - PATを作成し、認証付きで
/userを叩いて自分の情報を取得 - (発展) 別の公開APIを叩いてレスポンスを観察
参考リンク
- GitHub REST API v3: https://docs.github.com/ja/rest
fetch APIの基本
JavaScriptでAPIリクエストを送るためのfetch APIについて学んでいきましょう。前回体験したAPIリクエストを、今度はコードで実装してみます。
この記事で学べること
- fetch APIの基本構文と使い方
- PromiseとAsync/Awaitの関係
- GETリクエストの実装方法
- POSTリクエストの実装方法
- エラーハンドリングの基本パターン
- AbortControllerによるキャンセル処理
fetch APIとは
fetchは、ブラウザに標準で備わっているAPIリクエスト用の関数です。XMLHttpRequest(XHR)の後継として登場し、現在のWeb開発ではこちらが主流です。Node.js 18以降でもネイティブサポートされているので、サーバーサイドでも同じ書き方で使えます(便利ですね)。
最小構成
fetch("https://jsonplaceholder.typicode.com/posts/1");
たったこれだけでHTTPリクエストが送れます。ただし、このままでは結果を受け取れません。fetchはPromiseを返すので、適切に処理する必要があります。
Promiseとasync/await
fetchを使いこなすには、JavaScriptの非同期処理を理解しておく必要があります。
Promiseとは
Promiseは「将来の結果を約束するオブジェクト」です。APIリクエストのように時間がかかる処理の結果を扱うために使います。
// fetchはPromiseを返す
const promise = fetch("https://jsonplaceholder.typicode.com/posts/1");
console.log(promise); // Promise { <pending> } (DevToolsで確認可能)
.then()で結果を受け取る
fetch("https://jsonplaceholder.typicode.com/posts/1")
.then((response) => {
console.log("レスポンスを受け取りました");
return response.json(); // これもPromiseを返す
})
.then((data) => {
console.log(data.title);
});
.then()をチェーンでつなげて、順番に処理を書けます。ただ、ネストが深くなると読みにくくなりがちです。
async/awaitで読みやすく
async/awaitを使うと、非同期コードを同期的な見た目で書けます。
async function getPost() {
const response = await fetch("https://jsonplaceholder.typicode.com/posts/1");
const data = await response.json();
console.log(data.title);
}
await getPost();
awaitは「Promiseの結果が返ってくるまで待つ」という意味です。awaitを使うには、関数にasyncキーワードを付ける必要があります。
Note: この記事では主に
async/await形式で解説します。現代のJavaScript開発ではこちらが主流です。
GETリクエスト
データを取得する基本パターンを見ていきましょう。
基本形
async function fetchUser(id) {
const response = await fetch(
`https://jsonplaceholder.typicode.com/users/${id}`,
);
const user = await response.json();
return user;
}
// 使用例
const user = await fetchUser(1);
console.log(user.name); // "Leanne Graham"
ヘッダーを付ける
APIによっては、リクエストヘッダーの指定が必要です。
async function fetchWithHeaders(url) {
const response = await fetch(url, {
method: "GET", // GETの場合は省略可能
headers: {
Accept: "application/json",
"X-Custom-Header": "value",
},
});
return response.json();
}
await fetchWithHeaders("https://jsonplaceholder.typicode.com/users/1");
クエリパラメータの扱い
URLにパラメータを付けるにはURLSearchParamsが便利です。
async function searchUsers(query, limit = 10) {
const params = new URLSearchParams({
q: query,
_limit: limit.toString(),
});
const url = `https://jsonplaceholder.typicode.com/users?${params}`;
const response = await fetch(url);
return response.json();
}
// 使用例
const results = await searchUsers("Leanne");
console.log(results);
URLSearchParamsはエンコードも自動でやってくれます(日本語なども安全に扱えます)。
POSTリクエスト
データを送信する場合はPOSTメソッドを使います。
基本形
async function createPost(post) {
const response = await fetch("https://jsonplaceholder.typicode.com/posts", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(post),
});
const created = await response.json();
return created;
}
// 使用例
const newPost = await createPost({
title: "Hello World",
body: "This is my first post",
userId: 1,
});
console.log(newPost.id); // 101(サーバーが割り当てたID)
重要なポイント
method: "POST"を指定するContent-Type: application/jsonヘッダーを付けるJSON.stringify()でオブジェクトを文字列に変換する
JSON.stringify()を忘れると、サーバーには[object Object]という文字列が送られてしまいます(よくあるミスです)。
PUT/PATCH/DELETEも同様
// PUT: リソース全体を置き換え
async function updatePost(id, post) {
const response = await fetch(
`https://jsonplaceholder.typicode.com/posts/${id}`,
{
method: "PUT",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(post),
},
);
return response.json();
}
// DELETE: リソースを削除
async function deletePost(id) {
const response = await fetch(
`https://jsonplaceholder.typicode.com/posts/${id}`,
{
method: "DELETE",
},
);
return response.ok; // 成功ならtrue
}
// 例
await updatePost(1, { title: "Updated", body: "Updated body", userId: 1 });
await deletePost(1);
エラーハンドリング
fetchのエラー処理には注意点があります。
fetchは404でも例外を投げない
const response = await fetch("https://jsonplaceholder.typicode.com/posts/9999");
console.log(response.ok); // false
console.log(response.status); // 404
// でも、例外は発生していない!
fetchが例外を投げるのは、ネットワークエラー(サーバーに到達できない場合)だけです。HTTP 404や500などのエラーレスポンスは、正常なレスポンスとして返ってきます。
response.okを確認する
async function fetchPost(id) {
const response = await fetch(
`https://jsonplaceholder.typicode.com/posts/${id}`,
);
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
return response.json();
}
await fetchPost(9999); // HTTP 404の場合、例外が投げられる
response.okは、ステータスコードが200-299の範囲ならtrueになります。
開発者がレスポンスを確認し適切に対処できるようになっています。
AbortControllerによるキャンセル
リクエストを途中でキャンセルしたいケースがあります(画面遷移時など)。
基本的な使い方
const controller = new AbortController();
// 10msでキャンセル
setTimeout(() => controller.abort(), 10);
try {
const response = await fetch("https://jsonplaceholder.typicode.com/posts/1", {
signal: controller.signal,
});
const data = await response.json();
console.log(data);
} catch (error) {
if (error.name === "AbortError") {
console.log("リクエストがキャンセルされました");
} else {
throw error;
}
}
Note: Reactでは、コンポーネントのアンマウント時にリクエストをキャンセルするのがベストプラクティスです。詳しくは「useEffectによる非同期処理」で解説します。
TypeScriptでの型付け
TypeScriptを使う場合、レスポンスの型を定義しておくと安全です。
type User = {
id: number;
name: string;
email: string;
};
async function fetchUser(id: number): Promise<User> {
const response = await fetch(
`https://jsonplaceholder.typicode.com/users/${id}`,
);
if (!response.ok) {
throw new Error(`HTTP ${response.status}`);
}
const user: User = await response.json();
return user;
}
response.json()の戻り値はanyなので、型を明示的に付けることで、以降のコードで型チェックが効きます(タイプミスに気づけて助かります)。
やってみよう!
- ブラウザの開発者ツール(Console)で以下を実行してみましょう
// GETリクエスト
const res = await fetch("https://jsonplaceholder.typicode.com/users");
const users = await res.json();
console.log("ユーザー数:", users.length);
- POSTリクエストを試してみましょう
// POSTリクエスト
const res = await fetch("https://jsonplaceholder.typicode.com/posts", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ title: "テスト", body: "本文", userId: 1 }),
});
const created = await res.json();
console.log("作成されたID:", created.id);
- エラーハンドリングを確認
const res = await fetch("https://httpbin.org/status/404");
console.log("ok:", res.ok); // false
console.log("status:", res.status); // 404
- タイムアウトを体験
const controller = new AbortController();
setTimeout(() => controller.abort(), 100); // 100msでキャンセル
try {
await fetch("https://jsonplaceholder.typicode.com/posts", {
signal: controller.signal,
});
} catch (e) {
console.log("エラー種別:", e.name); // "AbortError"
}
ポイント(まとめ)
- fetch: ブラウザ標準のHTTPリクエスト関数。Promiseを返す
- async/await: 非同期処理を同期的な見た目で書ける構文
- response.json(): レスポンスボディをJSONとしてパース
- response.ok: ステータスコードが200-299ならtrue
- JSON.stringify(): POSTで送るデータをJSON文字列に変換
- AbortController: リクエストのキャンセルに使う
- fetchは404で例外を投げない: 必ず
response.okをチェックする
参考リンク
- MDN: fetch API https://developer.mozilla.org/ja/docs/Web/API/Fetch_API
- MDN: async/await https://developer.mozilla.org/ja/docs/Learn_web_development/Extensions/Async_JS/Promises
- MDN: AbortController https://developer.mozilla.org/ja/docs/Web/API/AbortController
- JSONPlaceholder https://jsonplaceholder.typicode.com/
useEffectによる非同期処理
Reactでデータのリアルタイムの送信など外部への副作用を記述をしたい。そんなときに欠かせないのがuseEffectです。発火のタイミング、クリーンアップ、依存配列などの基本を、実例で身につけましょう(簡単にできます)。
この記事で学べること
- useEffectの基本と依存配列の意味
- データ取得のベストプラクティス(AbortControllerでのキャンセル)
- ローディング/エラー表示のパターン
- ありがちな落とし穴(無限ループなど)
useEffectの基本
useEffectは「レンダーのあと」に実行される副作用(データ取得や購読など)を記述するためのフックです。
import { useEffect, useState } from "react";
function UserCard({ userId }) {
const [user, setUser] = useState(null);
useEffect(() => {
setUser({ id: userId, name: `ユーザー${userId}` });
}, [userId]);
return <h2>{user?.name || "loading..."}</h2>;
}
この例では:
useEffectの第1引数:実行したい副作用 (ここではsetUserで仮の名前をセット)useEffectの第2引数:依存配列 ([userId]なので、userIdが変わるたび実行)
Note
復習依存配列(
[])が空だと、マウント時に1回だけ実行されます。
データ取得(非同期)を正しく書く
useEffect内でasync関数を直接渡すのではなく、中で宣言して呼び出します(細かいですが大事です)。
import { useEffect, useState } from "react";
function UserCard({ userId }) {
const [user, setUser] = useState(null);
const [error, setError] = useState("");
const [loading, setLoading] = useState(false);
useEffect(() => {
const controller = new AbortController();
async function loadUser() {
try {
setLoading(true);
setError("");
const res = await fetch(
`https://jsonplaceholder.typicode.com/users/${userId}`,
{ signal: controller.signal },
);
if (!res.ok) {
throw new Error(`HTTP ${res.status}`);
}
const data = await res.json();
setUser(data);
} catch (e) {
if (e instanceof Error && e.name === "AbortError") {
return;
}
setError(e instanceof Error ? e.message : "エラーが発生しました");
} finally {
setLoading(false);
}
}
loadUser();
return () => controller.abort();
}, [userId]);
if (!user || loading) return <p>読み込み中...</p>;
if (error) return <p style={{ color: "crimson" }}>エラー: {error}</p>;
return (
<div>
<h2>{user.name}</h2>
<small>ID: {user.id}</small>
</div>
);
}
重要なポイント:
- AbortController: コンポーネントがアンマウントされたときにfetchをキャンセル
- 3つの状態管理: loading(読み込み中)、error(エラー)、user(成功時のデータ)
- 依存配列
[userId]: userIdが変わるたびに新しいデータを取得 - クリーンアップ関数:
return () => controller.abort()で前のリクエストをキャンセル
なぜAbortControllerが必要か:ユーザーが素早く別のユーザーに切り替えたとき、古いリクエストが完了してしまうと、新しいデータが古いデータで上書きされる問題が起きます。
Note: ループやダブルフェッチを避けるため、依存配列に
userやloadingを安易に入れないようにしましょう。必要最小限にするのがコツです。
無限ループを避けるコツ
- 依存配列には「外から与えられる値」や「関数の安定化済み参照(useCallbackなど)」のみを入れる
- データを
setStateした結果に依存して再度fetchしないようにする - オブジェクト/配列リテラルは毎回新しい参照になるので注意(
useMemoで安定化)
型安全に書く
TypeScriptでは、APIから受け取るデータの型を定義しておくと、タイプミスや不正なアクセスを防げます。
type Todo = {
id: number;
title: string;
completed: boolean;
};
使用例:
const [todo, setTodo] = useState<Todo | null>(null);
// 後でこう使える
if (todo) {
console.log(todo.title); // OK
console.log(todo.titl); // エラー!タイプミスに気づける
}
なぜ型を定義するのか:APIのレスポンス形式が変わったときや、プロパティ名を間違えたときに、コンパイル時に気づけるからです。
やってみよう!

- 上の
UserCardをコピーして、userIdを切り替えるボタンを用意 - 切り替え時に前のリクエストがキャンセルされることを確認(Networkタブで
(canceled)が出るはず) https://jsonplaceholder.typicode.com/users/9999にリクエストしてエラー表示をテスト
ポイント(まとめ)
useEffectは「レンダー後の副作用」を書く場所- 依存配列は最小化して無限ループを回避
- ローディング/エラー状態を適切に管理してUXを向上
- 非同期のリクエストの中断には
AbortControllerを使う
参考リンク
- React Docs: useEffect https://react.dev/reference/react/useEffect
- MDN: AbortController https://developer.mozilla.org/ja/docs/Web/API/AbortController
useSWR入門
データ取得をもっと楽に、もっと速く。そんな願いを叶えるのが「SWR」です。
ReactのuseEffect + fetchよりも簡単なコードで、またキャッシュ管理・バックグラウンド更新・エラーハンドリング・再試行などを自動で行ってくれます。
この記事で学べること
- SWRの基本概念(Stale-While-Revalidate)
- データ取得
- 状態管理(isLoading/error/data)
- グローバル設定(SWRConfig)
- 再検証のタイミング制御(focus/reconnect/interval)
- 依存キー・条件付きフェッチ
- ミューテーション(書き込みとキャッシュ更新)
基本概念: Stale-While-Revalidate とは
SWRは「手元のキャッシュ(stale)をすぐ表示しつつ、裏で最新データを取りに行き(revalidate)、更新できたらUIを差し替える」という戦略です。 ユーザーは待たされず、でもデータは最新、という理想的なユーザー体験が得られます。いいとこ取りというわけです。
useSWRを使ってみる
インストール(プロジェクトで一度だけ)
pnpm i swr
基本の使い方:
import useSWR from "swr";
const API_BASE = "https://jsonplaceholder.typicode.com";
async function fetcher(url) {
const res = await fetch(url);
if (!res.ok) throw new Error(`HTTP Error: ${res.status}`);
return res.json();
}
function UserDetail({ userId }) {
const { data, error, isLoading } = useSWR(
`${API_BASE}/users/${userId}`,
fetcher,
);
if (isLoading) return <p>読み込み中...</p>;
if (error) return <p>エラーが発生しました</p>;
return (
<div>
<h4>{data.name}</h4>
<p>{data.email}</p>
<small>ID: {data.id}</small>
</div>
);
}
Note:
fetcherは「URLを受け取ってデータを返す関数」。SWRはこのfetcherにURL(キー)を渡して実行します。エラー時は例外を投げることで、SWRのerror状態が有効になります。
状態管理
SWRは非同期のデータ取得に必要な状態を管理する機能を内蔵しています。返り値のオブジェクトから以下の3つを取り出して使います。
data: 取得済みデータ(キャッシュを含む)isLoading: 読み込み中error: フェッチに失敗したときのエラー
Note: すでにキャッシュがあれば
isLoadingでもdataがある、という状態も起こり得ます(これがSWRのポイント)。
SWRConfig でグローバル設定
import { SWRConfig } from "swr";
async function fetcher(url) {
const res = await fetch(url);
if (!res.ok) throw new Error(`HTTP Error: ${res.status}`);
return res.json();
}
function Providers({ children }) {
return <SWRConfig value={{ fetcher }}>{children}</SWRConfig>;
}
// 使い方
function App() {
return (
<Providers>
<UserDetail userId={1} />
</Providers>
);
}
Note: ここで指定した
fetcherがデフォルトになります。各コンポーネントでfetcherを省略可能に(楽ですね)。
再検証タイミングをコントロール
revalidateOnFocus: タブに戻ったら再取得(ユーザーに最新を見せる)revalidateOnReconnect: ネットワーク復帰で再取得refreshInterval: 定期ポーリング(ms)。0で無効
function UserDetail({ userId, enableRefresh = false }) {
const { data, error, isLoading } = useSWR(`${API_BASE}/users/${userId}`, {
refreshInterval: enableRefresh ? 5000 : 0, // 5秒ごとに再フェッチ
});
// ...
}
Note:
refreshIntervalを使うと、一定間隔でデータが自動更新されます。リアルタイム性が必要な場面で便利です。
依存キーと条件付きフェッチ
キー(第1引数)にnullを渡すとフェッチしません。必要な条件がそろうまで待てます。
function Profile() {
const [userId, setUserId] = useState("");
const [submittedUserId, setSubmittedUserId] = useState("");
// submittedUserIdが空の場合はフェッチしない
const { data, error, isLoading } = useSWR(
submittedUserId ? `${API_BASE}/users/${submittedUserId}` : null,
);
return (
<form
onSubmit={(e) => {
e.preventDefault();
setSubmittedUserId(userId.trim());
}}
>
<input
type="text"
value={userId}
onChange={(e) => setUserId(e.target.value)}
placeholder="ユーザーID"
/>
<button type="submit">検索</button>
</form>
);
}
Note: フォーム入力が完了して「検索」ボタンを押すまでリクエストは発生しません。
ミューテーションでUIを即時更新
mutateはキャッシュを書き換え、UIを即時反映させる関数です。サーバー反映を待たずに「先に見た目を更新」できます(便利)。
function Profile() {
const [submittedUserId, setSubmittedUserId] = useState("");
const { data, error, mutate } = useSWR(
submittedUserId ? `${API_BASE}/users/${submittedUserId}` : null,
);
// 存在しないユーザーをローカルで「作成」する(mutateでキャッシュに直接書き込む)
const createDummyUser = () => {
mutate(
{
id: Number(submittedUserId),
name: `ダミーユーザー ${submittedUserId}`,
email: `dummy${submittedUserId}@example.com`,
phone: "000-0000-0000",
},
{ revalidate: false }, // サーバーに再リクエストしない
);
};
// エラー時に再試行
const retry = () => mutate();
// ...
}
Note:
mutate()を引数なしで呼ぶと再フェッチ、データを渡すとキャッシュを直接書き換えます。{ revalidate: false }でサーバーへの再リクエストを抑制できます。
SWRでのエラーハンドリング戦略
エラー発生時の回復パターンを見てみましょう。
function Profile() {
const [submittedUserId, setSubmittedUserId] = useState("");
const [shouldRetryOnError, setShouldRetryOnError] = useState(false);
const { data, error, isLoading, mutate } = useSWR(
submittedUserId ? `${API_BASE}/users/${submittedUserId}` : null,
{ shouldRetryOnError }, // エラー時の自動リトライを制御
);
return (
<>
{error && !isLoading && (
<div>
<p>ユーザー {submittedUserId} が見つかりません</p>
<button onClick={() => mutate()}>再試行</button>
<button onClick={createDummyUser}>ユーザーを作成</button>
</div>
)}
{data && !error && (
<div>
<p>{data.name}</p>
<p>{data.email}</p>
</div>
)}
</>
);
}
Note:
shouldRetryOnErrorオプションでエラー時の自動リトライを制御できます。手動で再試行させたい場合はfalseに設定し、mutate()で明示的に再フェッチします。
やってみよう!
サンプルコードには3つのセクションがあります。
1. キャッシュ共有 + 定期更新
- 同じURLを参照する複数のコンポーネントがキャッシュを共有することを確認
- ユーザーIDを切り替えて、2回目以降は即座に表示される(キャッシュヒット)ことを体験
- DevTools Networkで1回のみリクエストされることを確認
- 「自動更新」チェックボックスで5秒間隔の
refreshIntervalを体験
2. キーの先行切り替え
- IDを変更すると、IDは即座に切り替わるがデータは後から到着する様子を観察
- SWRのキー変更でリクエストが発生する仕組みを理解
3. 条件付きフェッチ + エラーハンドリング
- IDを入力して「検索」を押すまでリクエストが発生しないことを確認
- 存在しないID(11以上)を入力してエラーハンドリングを体験
- 「再試行」ボタンで
mutate()による再フェッチを体験 - 「ユーザーを作成」ボタンで
mutate()によるキャッシュ書き込みを体験
Tip: Chrome DevTools > Network を「低速 4G」にすると、SWRの挙動がより分かりやすくなります。
ポイント(まとめ)
- SWRは「キャッシュ優先+裏で再取得」の戦略
useSWR(key, fetcher)が基本形- 状態(loading/error/data)を内蔵していてUIが簡単
SWRConfigで全体方針を一括設定- フォーカス/再接続/ポーリングで最新化タイミングを制御
mutateでキャッシュを書き換えてUIを即反映nullキーで条件付きフェッチ、配列キーで柔軟に渡す
参考リンク
- SWR 公式 https://swr.vercel.app/ja
- JSONPlaceholder https://jsonplaceholder.typicode.com/
TanStack Query入門
データ取得をもっと簡単に、もっと強力に。TanStack Query(旧React Query)は、サーバー状態管理の決定版ライブラリです。 キャッシュ、バックグラウンド更新、楽観的更新まで、複雑な非同期処理を実装するための便利な機能が満載です。
SWRとの違い
TanStack QueryとSWRはどちらも人気のあるサーバー状態管理ライブラリですが、いくつかの違いがあります。
| 特徴 | TanStack Query | SWR |
|---|---|---|
| バンドルサイズ | やや大きい | 小さい |
| 学習コスト | やや高い | 低い |
| 楽観的更新 | 組み込みサポート | 手動実装 |
| Mutation専用Hook | useMutation | なし(手動で実装) |
| 公式DevTools | あり | なし |
まずは使ってみる
インストール(プロジェクトで一度だけ)
pnpm i @tanstack/react-query
基本の使い方:
import {
QueryClient,
QueryClientProvider,
useQuery,
} from "@tanstack/react-query";
// QueryClientを作成(アプリで1つ)
const queryClient = new QueryClient();
export default function App() {
return (
// アプリ全体をProviderで囲む
<QueryClientProvider client={queryClient}>
<Profile />
</QueryClientProvider>
);
}
function Profile() {
const { data, error, isPending } = useQuery({
// キャッシュを識別するキー: 同じキーを持つクエリはキャッシュを共有します
queryKey: ["user", 1],
// データを取得する非同期関数
async queryFn() {
const res = await fetch("https://jsonplaceholder.typicode.com/users/1");
return res.json();
},
});
if (isPending) return <p>読み込み中...</p>;
if (error) return <p>エラーが発生しました</p>;
return (
<div>
<h2>{data.name}</h2>
<small>ID: {data.id}</small>
</div>
);
}
ローディング・エラー・データ
useQueryが返す状態は以下のとおりです。
isPending: まだデータがない状態(初回読み込み中)isError: エラーが発生した状態isSuccess: データ取得に成功した状態data: 取得したデータerror: エラー情報isFetching: バックグラウンドで再取得中
Note
SWRとの対応表
SWR TanStack Query isLoadingisPendingisValidatingisFetchingerrorisError+errordatadata(なし) isSuccess
function Todos() {
const { isPending, isError, data, error } = useQuery({
queryKey: ["todos"],
queryFn: fetchTodoList,
});
if (isPending) {
return <span>Loading...</span>;
}
if (isError) {
return <span>Error: {error.message}</span>;
}
// ここに到達したらisSuccess === true
return (
<ul>
{data.map((todo) => (
<li key={todo.id}>{todo.title}</li>
))}
</ul>
);
}
Note:
isPendingでも既にキャッシュがあればdataが存在する場合があります(バックグラウンド更新中)。isFetchingで更新中かどうかを確認できます。
QueryClientでグローバル設定
QueryClientにデフォルトオプションを設定できます。
import { QueryClient, QueryClientProvider } from "@tanstack/react-query";
const queryClient = new QueryClient({
defaultOptions: {
queries: {
staleTime: 1000 * 60, // 1分間はキャッシュを新鮮とみなす
gcTime: 1000 * 60 * 5, // 5分間キャッシュを保持
retry: 3, // 失敗時に3回リトライ
refetchOnWindowFocus: true, // ウィンドウフォーカス時に再取得
},
},
});
export function AppProviders({ children }: { children: React.ReactNode }) {
return (
<QueryClientProvider client={queryClient}>{children}</QueryClientProvider>
);
}
主要なオプション:
staleTime: この時間が経過するまでデータを「新鮮」とみなす(デフォルト: 0)gcTime: 未使用のキャッシュを保持する時間(デフォルト: 5分)retry: エラー時のリトライ回数(デフォルト: 3)refetchOnWindowFocus: タブに戻ったら再取得(デフォルト: true)
再検証タイミングをコントロール
TanStack Queryは様々なタイミングでデータを再取得します。
const { data } = useQuery({
queryKey: ["notifications"],
queryFn: fetchNotifications,
staleTime: 1000 * 30, // 30秒間は再取得しない
refetchOnWindowFocus: true, // フォーカス時に再取得
refetchOnReconnect: true, // ネットワーク復帰時に再取得
refetchInterval: 1000 * 60, // 1分ごとにポーリング
});
staleTime: データが「古い」と判断されるまでの時間refetchOnWindowFocus: タブに戻ったときrefetchOnReconnect: ネットワーク復帰時refetchInterval: 定期的なポーリング(ミリ秒)
依存キーと条件付きフェッチ
enabledオプションで条件付きフェッチを実現できます。
function UserDetail({ id }: { id?: number }) {
const { data, isPending } = useQuery({
queryKey: ["user", id],
queryFn: () => fetch(`/api/users/${id}`).then((r) => r.json()),
enabled: !!id, // idがあるときだけフェッチ
});
if (!id) return <p>ユーザーを選択してください</p>;
if (isPending) return <p>読み込み中...</p>;
return <div>{data.name}</div>;
}
queryKeyに変数を含めると、その値が変わったときに自動で再取得されます(依存キー)。
function UserPosts({ userId }: { userId: number }) {
const { data } = useQuery({
queryKey: ["posts", userId], // userIdが変わると再取得
queryFn: () => fetchUserPosts(userId),
});
// ...
}
useMutationでデータを更新
データの作成・更新・削除にはuseMutationを使います。
import { useMutation, useQueryClient } from "@tanstack/react-query";
function AddTodo() {
const queryClient = useQueryClient();
const mutation = useMutation({
mutationFn: (newTodo: string) =>
fetch("/api/todos", {
method: "POST",
body: JSON.stringify({ text: newTodo }),
headers: { "Content-Type": "application/json" },
}).then((r) => r.json()),
onSuccess: () => {
// 成功したらtodosのキャッシュを無効化して再取得
queryClient.invalidateQueries({ queryKey: ["todos"] });
},
});
return (
<button
onClick={() => mutation.mutate("新しいタスク")}
disabled={mutation.isPending}
>
{mutation.isPending ? "追加中..." : "追加"}
</button>
);
}
楽観的更新(Optimistic Update)
サーバーの応答を待たずにUIを先に更新し、失敗したらロールバックするパターンです。
const likeMutation = useMutation({
mutationFn: (postId: number) =>
fetch(`/api/posts/${postId}/like`, { method: "POST" }),
onMutate: async (postId) => {
// 進行中のクエリをキャンセル
await queryClient.cancelQueries({ queryKey: ["post", postId] });
// 現在のデータを保存
const previousPost = queryClient.getQueryData(["post", postId]);
// 楽観的に更新
queryClient.setQueryData(["post", postId], (old: Post) => ({
...old,
likes: old.likes + 1,
}));
return { previousPost };
},
onError: (err, postId, context) => {
// エラー時はロールバック
queryClient.setQueryData(["post", postId], context?.previousPost);
},
onSettled: (data, error, postId) => {
// 成功・失敗に関わらず再取得
queryClient.invalidateQueries({ queryKey: ["post", postId] });
},
});
やってみよう!
- useSWR入門 のコードを TanStack Query に書き換えてみる
queryKeyを["user", 2]に変えて、別のユーザーを取得してみる- 同じ
queryKeyを持つコンポーネントを2つ配置して、キャッシュ共有を確認 staleTime: 30000を設定して、30秒間は再取得しないことを確認refetchInterval: 5000で5秒ごとにポーリングする様子を確認useMutationで楽観的更新を実装してみる- TanStack DevTools を使ってみる
参考リンク
- TanStack Query 公式 https://tanstack.com/query/latest
- TanStack Query ドキュメント(日本語) https://tanstack.com/query/latest/docs/framework/react/overview
- JSONPlaceholder https://jsonplaceholder.typicode.com/
プロキシ確認ガイド
社内ネットワークやセキュリティが厳しい環境では、プロキシ設定が必須になることがあります。まずは自分の環境で通信ができているか確認し、問題がある場合のみ設定を行えば大丈夫です。
このガイドでは、各種開発ツール (npm、Git、AWS CLI等) でプロキシ環境下での通信確認方法と設定方法を学んでいきましょう。
HTTP通信の確認方法
Webブラウザー
この文が見えていればOKです。
NPM
Step1. Node.jsのインストール
Step2. ターミナルでコマンドを実行
ターミナルで次のコマンドを実行して、レジストリとHTTP通信できることを確認します。
npm ping
数秒以内に “npm notice PONG” というメッセージが表示されていればOKです。

“ERROR: connect ECONNREFUSED” など “ERROR” から始まるメッセージが表示される場合はNGです❌
Git
Step1. Gitのインストール
- Git for Windows
- (Macは最初からインストールされているため不要)
Step2. ターミナルでコマンドを実行
GitがHTTP通信できることを確認します。
GitHubのリポジトリのクローンを行うコマンド:
$ git clone <https://github.com/octo-org/octo-template.git>
Cloning into 'octo-template'...
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (3/3), done.
期待通りリポジトリがクローンされていればOKです。
“fatal: unable to access” や “Failed to connect to …” というメッセージが表示される場合はNGです❌
リモートリポジトリの一覧を確認するコマンド: git ls-remote
$ cd octo-template
$ git ls-remote
From <https://github.com/octo-org/octo-template.git>
c85af0e5e5798047462143a13c1b455ee1275a64 HEAD
c85af0e5e5798047462143a13c1b455ee1275a64 refs/heads/main
b9b26d9eaaea5750bf9a937a6683294a3786b449 refs/pull/3/head
8e3150bce9b6af556e6ebd7307db3bfd0d7852db refs/pull/3/merge
期待通りリモートリポジトリが表示されていればOKです。
“fatal: unable to access” や “Failed to connect to …” というメッセージが表示される場合はNGです❌
AWS CLI
Step1. AWS CLIのインストール
Step2. 初期設定
Step3. ターミナルでコマンドを実行
AWS CLIがHTTP通信できることを確認します。
例えば: S3バケットの一覧を確認するコマンド
aws s3 ls
S3バケットの一覧が期待通り表示されていればOKです。

“Failed to connect to proxy URL:” や “Unable to …” から始まるメッセージが表示される場合はNGです❌
AWS SDK
確認するコマンドはありません。 AWS SDKのプロキシの設定後、変更したコードが期待通り動作すればOKです。
VSCode (Visual Studio Code)
確認するコマンドはありません。 拡張機能のインストールなど期待通り動作すればOKです。
HTTP通信が可能な環境では、以降の設定は不要です。
Webブラウザーのプロキシの設定
- Chrome/Edge/Safari: システムのネットワーク設定から行います。それぞれのOSの設定を確認してください。
- Windows 11: Windows でプロキシ サーバーを使用する - Microsoft サポート [スタート] ボタンを選択し、[設定] > [ネットワークとインターネット] > [プロキシ] >[手動プロキシセットアップ] で、[プロキシ サーバーを使用] の横にある [セットアップ] を選択 > [プロキシ サーバーの編集] ダイアログ ボックス > [プロキシ サーバーを使用]有効化・[プロキシ IP アドレス] および [ポート] ボックスに、プロキシ サーバー名または IP アドレスとポートをそれぞれのボックスに入力・[ローカル (イントラネット) アドレスにプロキシ サーバーを使用しない] チェック ボックスをオン > [保存] を選択
- Mac: Macでプロキシサーバ設定を入力する - Apple サポート (日本)
- Firefox: https://support.mozilla.org/ja/kb/connection-settings-firefox
NPMのプロキシの設定
環境変数 HTTP_PROXY と HTTPS_PROXY に適切なプロキシのURLを設定します。
下記ではプロキシのURLの例として http://user:pass@proxy.example.com:8080 を示しています。実際の自分の環境に合わせたURLに変更して実行してください。
Windows - PowerShellの場合
$env:HTTP_PROXY="<http://user:pass@proxy.example.com:8080>"$env:HTTPS_PROXY="<http://user:pass@proxy.example.com:8080>"
Windows - コマンドプロンプトの場合
set HTTP_PROXY=http://user:pass@proxy.example.com:8080
set HTTPS_PROXY=http://user:pass@proxy.example.com:8080
上記以外 - BashやZshなどの場合
export HTTP_PROXY=http://user:pass@proxy.example.com:8080
export HTTPS_PROXY=http://user:pass@proxy.example.com:8080
設定を行ったら、通常通り npm コマンドを実行して、エラーが出ないことを確認してみましょう。
Gitのプロキシの設定
NPMのプロキシの設定と同様に、環境変数 HTTP_PROXY と HTTPS_PROXY を設定します。
AWS CLIのプロキシの設定
NPMのプロキシの設定と同様に、環境変数 HTTP_PROXY と HTTPS_PROXY を設定します。
AWS SDKのプロキシの設定
Step1. NPMのプロキシの設定と同様に、環境変数 HTTP_PROXY と HTTPS_PROXY を設定します。
Step2. @smithy/node-http-handler と proxy-agent をインストールします。
npm i @smithy/node-http-handler proxy-agent
Step3. ProxyAgentを使います。
例:
import { S3Client } from "@aws-sdk/client-s3";
import { NodeHttpHandler } from "@smithy/node-http-handler";
import { ProxyAgent } from "proxy-agent";
const agent = new ProxyAgent();
const s3Client = new S3Client({
requestHandler: new NodeHttpHandler({
httpAgent: agent,
httpsAgent: agent,
}),
});
export default s3Client;
VSCodeのプロキシの設定
プロキシ環境下で使用する場合、拡張機能のインストールに失敗することがあります。 そういったケースでは、設定 > Http: Proxy (http.proxy) にプロキシのURLを指定すると機能します。
Honoハンズオン
HonoでREST APIを作るハンズオンです。JSONのレスポンスを返したり、受け取ったりできるようになることを目指します。
Honoとエッジランタイム
Web開発のフレームワークの世界で、最近注目を集めているHono(炎)について学んでいきましょう。 Honoにはエッジランタイムにぴったりな特徴があります。
この記事で学べること
- なぜユーザーに近い場所 (エッジ) でコードを動かすことが重要なのか理解する
- Honoがどのようにその課題を解決するのか理解する
通信の物理的限界: 光の速さでも遅い?
あなたが東京にいて、アメリカ・オレゴン州にあるサーバーにアクセスするとします。
直線距離は約8,000km。光の速度は約300,000km/s。単純計算で片道約27ミリ秒、往復で約 54ミリ秒 かかります。
「たった54ミリ秒?」と思うかもしれませんが、これは理論上の限界値です。実際には、ケーブルが直線ではなかったり、サーバーでの処理時間があったり、ルーターを経由したりするので、100〜200ミリ秒以上かかることは珍しくありません。
なぜこれが問題なのか
Webアプリケーションでは、1回のページ表示で何十回もサーバーとの通信が発生します。
- HTMLの取得
- CSSの取得
- JavaScriptの取得
- APIからデータの取得(複数回)
- 画像の取得(複数枚)
仮に1回の通信に150ミリ秒かかるとして、20回通信すれば3秒。ユーザーは「遅い」と感じ始めます。
Note: 実際に GCPing で遅延を測定してみましょう。あわせて、海底ケーブルがどのように地球上に張り巡らされているか Submarine Cable Map と見比べてみましょう。
解決策: ユーザーの近くでコードを動かす
エッジコンピューティングとは
「エッジ(端)」とは、ネットワークの端、つまりユーザーに近い場所のことです。
【従来のアーキテクチャ】
ユーザー(東京) ──→ 太平洋を横断 ──→ サーバー(米国)
↓
ユーザー(東京) ←── 太平洋を横断 ←── レスポンス
往復で100〜200ms以上
【エッジコンピューティング】
ユーザー(東京) ──→ エッジサーバー(東京) ──→ レスポンス
往復で10〜30ms程度
世界中にサーバーを分散配置し、ユーザーに最も近いサーバーが処理を担当する。これがエッジコンピューティングの基本的な考え方です。
エッジランタイムとは
エッジコンピューティングを実現するための実行環境を「エッジランタイム」と呼びます。
代表的なエッジランタイム:
- Cloudflare Workers - 世界300都市以上にサーバーを持つ
- Deno Deploy - Deno社が提供するエッジランタイム
- Vercel Edge Functions - Next.jsで有名なVercelのエッジランタイム
エッジランタイムのメリット
| メリット | 説明 |
|---|---|
| 低遅延 | ユーザーに近い場所で処理するため、体感速度が大幅に向上 |
| 従量課金 | 使った分だけ支払う。小規模なら月額無料枠で収まることも |
| 自動スケーリング | アクセスが増えても自動で対応。サーバー管理が不要 |
Note
光の速さを超える通信のためのプロトコル2024年 4月1日 に「Faster Than Light Speed Protocol [RFC 9564]」仕様が公開されました。 このRFCのプロトコルは文字通り「光の速さを超える通信」を可能とするための技術ですが、実装は「まだ」存在しません 😃
エッジランタイムのトレードオフ
エッジランタイムは魅力的な技術ですが銀の弾丸ではありません。トレードオフを理解して適材適所で使うことが重要です。
デバッグの難しさ
世界中に分散されたサーバーで動くため、問題の特定が難しくなることがあります。
ローカル環境 → 動作する ✅
東京のエッジサーバー → 動作する ✅
ロンドンのエッジサーバー → なぜか動かない ❌
特定の地域でのみ発生するバグは、その地域のネットワーク環境やサーバー設定が原因の可能性があり、デバッグが複雑になります。
そのため、ローカル環境でもエッジランタイムでも同じコードがどこでも動く、Web標準APIを活用したフレームワークが重要です。
データの一貫性の課題
世界中のサーバーにデータを分散させる場合、結果整合性という概念を理解する必要があります。
【例: SNSの「いいね」機能】
1. 東京に住んでいるAさんが投稿に「いいね」 → 東京のサーバーに記録
2. ロンドンに住んでいるBさんがその投稿を見る
3. データ同期に時間がかかるため、Bさんには「いいね」が反映されていない
4. 数秒後、データが同期され、Bさんにも「いいね」が表示される
このような「少しの遅れ」を許容して、結果的にデータが一致すれば良い、という設計が、「結果整合性」の考え方です。
実行環境の制約
エッジランタイムは従来のサーバーと比べて、制約があることが多いです。
| 制約 | 説明 |
|---|---|
| 実行時間の制限 | 1リクエストあたり数秒〜数十秒の制限がある |
| メモリの制限 | 使用できるメモリが限られている |
| ファイルシステム | 永続的なファイル保存ができない(一時的なメモリストレージのみ) |
| 利用可能なライブラリ | Node.js標準ライブラリの一部が使えない場合がある |
いつエッジランタイムを選ぶべきか
エッジランタイムが向いているケース:
- 低遅延が重要なケース (チャット、ゲーム、リアルタイム通知など)
- 世界中のユーザーを対象とするアプリケーション (SNS、動画配信など)
- 読み取り中心のAPI (ニュースサイト、ブログ、商品カタログなど)
従来サーバーが向いているケース:
- 長時間の処理が必要なケース (動画エンコード、大量のバッチ処理など)
- 大量のデータを扱うアプリケーション (ビッグデータ分析、機械学習モデルのトレーニングなど)
- 厳密なデータ一貫性が必要なAPI (金融取引、在庫管理など)
エッジランタイムのメリットとトレードオフを理解した上で、適切な技術選択をすることが大切です。そして「エッジランタイム」で最大限のパフォーマンスを発揮できるように設計されたフレームワークが「Hono」なのです。
Honoとは何か
Hono(炎)は、TypeScriptで書かれた軽量・高速なWebフレームワークです。
import { Hono } from "hono";
const app = new Hono();
app.get("/", (c) => c.text("Hello Hono!"));
export default app;
たったこれだけでWebサーバーが完成します。
Honoの特徴
- 爆速 🚀 -
RegExpRouter速い。逐次処理を用いない。まじ速い。 - 軽量 🪶 -
hono/tinyプリセットはわずか 14kB 未満。依存関係ゼロでWeb標準のみ。 - マルチランタイム 🌍 - Cloudflare Workers、Fastly Compute、Deno、Bun、AWS Lambda、Node.js。どこのプラットフォームでも同じコードが動く。
- バッテリー同梱 🔋 - 内蔵のミドルウェア、カスタムミドルウェア、サードパーティのミドルウェア、ヘルパー。いわゆる バッテリー同梱。
- 楽しい開発体験 😃 - 超クリーンAPI。TypeScriptが第一級対応。すぐ“型“付く。
Features
- Ultrafast 🚀 - The router
RegExpRouteris really fast. Not using linear loops. Fast.- Lightweight 🪶 - The
hono/tinypreset is under 14kB. Hono has zero dependencies and uses only the Web Standards.- Multi-runtime 🌍 - Works on Cloudflare Workers, Fastly Compute, Deno, Bun, AWS Lambda, or Node.js. The same code runs on all platforms.
- Batteries Included 🔋 - Hono has built-in middleware, custom middleware, third-party middleware, and helpers. Batteries included.
- Delightful DX 😃 - Super clean APIs. First-class TypeScript support. Now, we’ve got “Types”.
なぜ「マルチランタイム」が重要なのか
従来、エッジランタイムごとに異なる書き方が必要でした。
// Cloudflare Workers用
export default { fetch(req, env) { ... } }
// Deno用
Deno.serve((req) => { ... });
// Node.js用
import http from "node:http";
http.createServer((req, res) => { ... });
Honoを使えば、どの環境でも同じコードが動きます。
// どの環境でもこのコードでOK
import { Hono } from "hono";
const app = new Hono();
app.get("/", (c) => c.text("Hello!"));
export default app;
これにより、開発環境はNode.js、本番環境はCloudflare Workers、という構成も簡単に実現できます。
Honoを使った実践例
例1: シンプルなAPIサーバー
import { Hono } from "hono";
const app = new Hono();
// ユーザー一覧を返すAPI
app.get("/api/users", (c) => {
return c.json([
{ id: 1, name: "田中太郎" },
{ id: 2, name: "山田花子" },
]);
});
// 特定のユーザーを返すAPI
app.get("/api/users/:id", (c) => {
const id = c.req.param("id"); // URLパラメータを取得
return c.json({ id, name: "田中太郎" });
});
export default app;
例2: ミドルウェアの活用
ミドルウェアとは、リクエストを処理する「途中の処理」のことです。
import { Hono } from "hono";
import { logger } from "hono/logger"; // ログ出力
import { cors } from "hono/cors"; // CORS対応
import { basicAuth } from "hono/basic-auth"; // Basic認証
const app = new Hono();
// 全リクエストにログを出力
app.use("*", logger());
// /api/* へのリクエストにCORSを許可
app.use("/api/*", cors());
// /admin/* へのリクエストにBasic認証を要求
app.use(
"/admin/*",
basicAuth({
username: "admin",
password: "secret",
}),
);
app.get("/api/public", (c) => c.text("誰でもアクセス可能"));
app.get("/admin/dashboard", (c) => c.text("管理者のみアクセス可能"));
export default app;
ポイント
| 概念 | 説明 |
|---|---|
| エッジコンピューティング | ユーザーに近い場所でアプリを実行し、遅延を減らす考え方 |
| エッジランタイム | エッジでアプリを動かすための実行環境(Cloudflare Workers等) |
| Hono | 軽量・高速・マルチランタイム対応のWebフレームワーク |
参考文献
Hello Worldとローカル実行
Honoの概要を理解したところで、実際に手を動かしてみましょう。Hono CLIを使えば、数コマンドでプロジェクトを作成できます。
プロジェクトの作成
ターミナルを開いて、以下のコマンドを実行します。
pnpm create hono@latest
対話形式でいくつかの質問が表示されます。
Target directory … my-hono-app
Which template do you want to use? … nodejs
Do you want to install project dependencies? … yes
Which package manager do you want to use? … pnpm
- Target directory: プロジェクト名を入力(例:
my-hono-app) - template:
nodejsを選択 - dependencies:
yesを選択 - package manager:
pnpmを選択
これだけで、Honoプロジェクトの雛形が完成します。
プロジェクトの中身を確認
作成されたディレクトリに移動して、中身を見てみましょう。
cd my-hono-app
以下のようなファイル構成になっています。
my-hono-app/
├── src/
│ └── index.ts # アプリケーションのメインファイル
├── package.json
└── tsconfig.json
src/index.ts の中身を確認してみましょう。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
const app = new Hono();
app.get("/", (c) => {
return c.text("Hello Hono!");
});
const port = 3000;
console.log(`Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
たったこれだけでWebサーバーが完成しています。1つずつ見ていきましょう。
コードの解説
const app = new Hono();
Honoアプリケーションのインスタンスを作成しています。
app.get("/", (c) => {
return c.text("Hello Hono!");
});
GET / へのリクエストを処理するルートを定義しています。c はContext(コンテキスト)オブジェクトで、リクエストやレスポンスを操作するためのメソッドが含まれています。
serve({
fetch: app.fetch,
port,
});
Node.js環境でHTTPサーバーを起動しています。
開発サーバーを起動しよう
以下のコマンドで開発サーバーを起動します。
pnpm dev
ターミナルに以下のようなメッセージが表示されます。
Server is running on http://localhost:3000
ブラウザで http://localhost:3000 にアクセスしてみましょう。「Hello Hono!」と表示されれば成功です。
やってみよう!
コードを少し変更して、変化を確認してみましょう。
1. メッセージを変えてみる
src/index.ts の c.text('Hello Hono!') を好きなメッセージに変更してみましょう。
app.get("/", (c) => {
return c.text("こんにちは、Hono!");
});
ファイルを保存すると、自動的にサーバーが再起動されます(ホットリロード)。ブラウザをリロードして変化を確認してみてください。
2. 新しいルートを追加してみる
/hello というパスにアクセスしたときに別のメッセージを返すルートを追加してみましょう。
app.get("/", (c) => {
return c.text("こんにちは、Hono!");
});
// 新しいルートを追加
app.get("/hello", (c) => {
return c.text("Hello from /hello!");
});
ブラウザで http://localhost:3000/hello にアクセスして確認してみましょう。
3. JSONレスポンスを試してみる
c.text() の代わりに c.json() を使うと、JSONを返せます。
app.get("/api", (c) => {
return c.json({ message: "Hello API!" });
});
ブラウザで http://localhost:3000/api にアクセスすると、JSONが表示されます。
ポイント
- Hono CLI:
pnpm create hono@latestで簡単にプロジェクトを作成 - ホットリロード: ファイル保存で自動的にサーバーが再起動
c.text(): テキストレスポンスを返すc.json(): JSONレスポンスを返す- ルート定義:
app.get('/path', ...)でパスとハンドラを紐づける
参考文献
REST APIを作ろう
Hello Worldができたら、次は本格的なREST APIを作ってみましょう。シンプルなToDoリストAPIを題材に、HTTPメソッド、ステータスコード、JSONの送受信を学んでいきます。
REST APIとは
REST API は、HTTPメソッド(GET, POST, PUT, DELETE など)を使ってデータを操作するAPIの設計スタイルです。
| HTTPメソッド | 用途 | 例 |
|---|---|---|
| GET | データの取得 | ユーザー一覧を取得 |
| POST | データの作成 | 新しいユーザーを登録 |
| PUT | データの更新 | ユーザー情報を変更 |
| DELETE | データの削除 | ユーザーを削除 |
準備: プロジェクトのセットアップ
前章で作成した my-hono-app を引き続き使います。src/index.ts を以下のように書き換えましょう。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
const app = new Hono();
// ToDoリストのデータ(メモリ上に保持)
interface Todo {
id: number;
title: string;
completed: boolean;
}
let todos: Todo[] = [
{ id: 1, title: "牛乳を買う", completed: false },
{ id: 2, title: "Honoを学ぶ", completed: true },
];
let nextId = 3;
// ルートを定義していく
const port = 3000;
console.log(`Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
これでToDoデータを管理する準備ができました。データベースは使わず、メモリ上の配列でデータを保持します。
ステップ1: GET - 一覧を取得する
まず、ToDoの一覧を取得するAPIを作りましょう。
// GET /todos - ToDoの一覧を取得
app.get("/todos", (c) => {
return c.json(todos);
});
サーバーを起動して確認してみましょう。
pnpm dev
ブラウザで http://localhost:3000/todos にアクセスすると、ToDoの一覧がJSONで表示されます。
[
{ "id": 1, "title": "牛乳を買う", "completed": false },
{ "id": 2, "title": "Honoを学ぶ", "completed": true }
]
確認してみよう
ターミナルからAPIを呼び出すこともできます。別のターミナルを開いて以下を実行してみましょう。
curl http://localhost:3000/todos
ステップ2: GET - パスパラメータで1件取得
次に、特定のToDoを取得するAPIを作ります。/todos/1 のようにIDを指定してアクセスします。
// GET /todos/:id - 特定のToDoを取得
app.get("/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const todo = todos.find((t) => t.id === id);
if (!todo) {
return c.json({ error: "Todo not found" }, 404);
}
return c.json(todo);
});
ポイント解説
パスパラメータの取得
const id = c.req.param("id");
/todos/:id の :id 部分をパスパラメータと呼びます。c.req.param('id') で値を取得できます。
HTTPステータスコード
return c.json({ error: "Todo not found" }, 404);
c.json() の第2引数でステータスコードを指定できます。404は「見つかりません」を意味します。
確認してみよう
# 存在するToDo
curl http://localhost:3000/todos/1
# 存在しないToDo(404が返る)
curl http://localhost:3000/todos/999
ステップ3: POST - 新しいToDoを作成
クライアントからJSONを受け取って、新しいToDoを作成するAPIを追加します。
// POST /todos - 新しいToDoを作成
app.post("/todos", async (c) => {
const body = await c.req.json();
const newTodo: Todo = {
id: nextId++,
title: body.title,
completed: false,
};
todos.push(newTodo);
return c.json(newTodo, 201);
});
ポイント解説
リクエストボディの取得
const body = await c.req.json();
クライアントから送られてきたJSONを c.req.json() で取得します。await が必要なので、ハンドラを async にしています。
201 Created
return c.json(newTodo, 201);
リソースが新しく作成されたときは、200 OKではなく 201 Created を返すのが慣習です。
確認してみよう
curl -X POST http://localhost:3000/todos \
-H "Content-Type: application/json" \
-d '{"title": "TypeScriptを勉強する"}'
一覧を取得して、追加されたことを確認しましょう。
curl http://localhost:3000/todos
ステップ4: PUT - ToDoを更新
既存のToDoを更新するAPIを追加します。
// PUT /todos/:id - ToDoを更新
app.put("/todos/:id", async (c) => {
const id = Number(c.req.param("id"));
const body = await c.req.json();
const todo = todos.find((t) => t.id === id);
if (!todo) {
return c.json({ error: "Todo not found" }, 404);
}
// 渡された値で更新(undefinedでなければ)
if (body.title !== undefined) todo.title = body.title;
if (body.completed !== undefined) todo.completed = body.completed;
return c.json(todo);
});
確認してみよう
# ToDoを完了状態にする
curl -X PUT http://localhost:3000/todos/1 \
-H "Content-Type: application/json" \
-d '{"completed": true}'
# 確認
curl http://localhost:3000/todos/1
ステップ5: DELETE - ToDoを削除
最後に、ToDoを削除するAPIを追加します。
// DELETE /todos/:id - ToDoを削除
app.delete("/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const index = todos.findIndex((t) => t.id === id);
if (index === -1) {
return c.json({ error: "Todo not found" }, 404);
}
todos.splice(index, 1);
return c.text("Deleted", 200);
});
ポイント解説
テキストレスポンスとステータスコード
return c.text("Deleted", 200);
c.text() でもステータスコードを指定できます。削除成功時は 200 OK や 204 No Content を返すのが一般的です。
確認してみよう
# 削除
curl -X DELETE http://localhost:3000/todos/1
# 一覧を確認(ID:1が消えている)
curl http://localhost:3000/todos
完成コード
ここまでの内容をまとめた完成版のコードです。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
const app = new Hono();
interface Todo {
id: number;
title: string;
completed: boolean;
}
let todos: Todo[] = [
{ id: 1, title: "牛乳を買う", completed: false },
{ id: 2, title: "Honoを学ぶ", completed: true },
];
let nextId = 3;
// GET /todos - 一覧取得
app.get("/todos", (c) => {
return c.json(todos);
});
// GET /todos/:id - 1件取得
app.get("/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const todo = todos.find((t) => t.id === id);
if (!todo) {
return c.json({ error: "Todo not found" }, 404);
}
return c.json(todo);
});
// POST /todos - 新規作成
app.post("/todos", async (c) => {
const body = await c.req.json();
const newTodo: Todo = {
id: nextId++,
title: body.title,
completed: false,
};
todos.push(newTodo);
return c.json(newTodo, 201);
});
// PUT /todos/:id - 更新
app.put("/todos/:id", async (c) => {
const id = Number(c.req.param("id"));
const body = await c.req.json();
const todo = todos.find((t) => t.id === id);
if (!todo) {
return c.json({ error: "Todo not found" }, 404);
}
if (body.title !== undefined) todo.title = body.title;
if (body.completed !== undefined) todo.completed = body.completed;
return c.json(todo);
});
// DELETE /todos/:id - 削除
app.delete("/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const index = todos.findIndex((t) => t.id === id);
if (index === -1) {
return c.json({ error: "Todo not found" }, 404);
}
todos.splice(index, 1);
return c.text("Deleted", 200);
});
const port = 3000;
console.log(`Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
やってみよう!
完成したAPIを使って、以下を試してみましょう。
- 新しいToDoを3つ追加する
- 追加したToDoを完了状態にする
- 完了したToDoを削除する
- 存在しないIDにアクセスして404エラーを確認する
発展課題
余裕があれば、以下の機能を追加してみましょう。
- 完了済みのToDoだけを取得する
GET /todos?completed=true - タイトルが空の場合にエラーを返す(バリデーション)
ポイント
c.json(data): JSONレスポンスを返すc.json(data, status): ステータスコード付きでJSONを返すc.text(message, status): テキストレスポンスを返すc.req.param("name"): パスパラメータを取得c.req.json(): リクエストボディのJSONを取得(awaitが必要)
よく使うHTTPステータスコード
| コード | 意味 | 使いどころ |
|---|---|---|
| 200 | OK | 正常に処理完了 |
| 201 | Created | 新しいリソースを作成した |
| 400 | Bad Request | リクエストが不正 |
| 404 | Not Found | リソースが見つからない |
| 500 | Internal Server Error | サーバー内部エラー |
参考文献
Hono + React 連携
このセクションでは、Honoで作ったAPIサーバーとReactアプリを実際に連携させます。2つの独立したプロジェクトを作成し、CORSの仕組みを体験しながら、実務でよく使われる構成を学びましょう。
概要
このセクションでは、HonoとReactを実際に連携させて「APIサーバー+SPAフロントエンド」の構成を体験します。2つの独立したプロジェクトを作成し、CORSという仕組みにも触れていきます。
今回作るもの
Hono(バックエンド)とReact(フロントエンド)を別々のプロジェクトとして作成し、連携させます。
| アプリ | ポート | 役割 |
|---|---|---|
| Hono(API) | 3000 | /api/hello でJSONを返す |
| React(画面) | 5173 | APIを呼び出して画面に表示 |
ブラウザ
│
│ http://localhost:5173
▼
┌────────────────────┐
│ React (Vite) │
│ ポート: 5173 │
└────────────────────┘
│
│ fetch("http://localhost:3000/api/hello")
▼
┌────────────────────┐
│ Hono (Node.js) │
│ ポート: 3000 │
└────────────────────┘
ReactアプリからHono APIにリクエストを送り、レスポンスを画面に表示します。
CORSとは
今回の演習では、ReactからHonoにリクエストを送ろうとするとCORSエラーに遭遇します。これはブラウザのセキュリティ機能によるものです。
オリジンとは
オリジンは「スキーム + ホスト + ポート」の組み合わせです。
| URL | オリジン (スキーム, ホスト, ポート) |
|---|---|
| http://localhost:5173 | (http, localhost, 5173) |
| http://localhost:3000 | (http, localhost, 3000) |
| https://example.com | (https, example.com, 443) |
ポート番号が違えば別のオリジンとして扱われます。
同一オリジンポリシー
ブラウザには同一オリジンポリシーというセキュリティ機能があります。これは「異なるオリジンへのリクエストを制限する」仕組みです。
この制限がないと、悪意あるWebサイトがユーザーの認証情報を使って勝手にAPIを呼び出せてしまいます。
悪意あるサイト (evil.com)
│
│ fetch("https://your-bank.com/api/transfer")
▼
銀行のAPI ← ユーザーのCookieが自動送信される!
同一オリジンポリシーは、このような攻撃からユーザーを守るための機能です。
CORS(Cross-Origin Resource Sharing)
では、自分のReactアプリから自分のHono APIを呼び出したい場合はどうするのでしょうか?
そこで使うのがCORSです。CORSは「このオリジンからのリクエストは許可する」とサーバーがブラウザに伝える仕組みです。
React (localhost:5173) Hono (localhost:3000)
│ │
│ GET /api/hello │
│─────────────────────────────────────────►│
│ │
│ Response + Access-Control-Allow-Origin │
│◄─────────────────────────────────────────│
│ │
ブラウザ: 「サーバーがOKと言ってるので許可する」
サーバーが Access-Control-Allow-Origin ヘッダーをレスポンスに含めることで、ブラウザはリクエストを許可します。
次の演習では、実際にCORSエラーに遭遇し、Honoの cors() ミドルウェアで解決する流れを体験します。
ポイント
- オリジン: プロトコル + ホスト + ポートの組み合わせ
- 同一オリジンポリシー: ブラウザが異なるオリジンへのリクエストを制限するセキュリティ機能
- CORS: サーバーが「このオリジンからのリクエストは許可する」と明示する仕組み
- Access-Control-Allow-Origin: 許可するオリジンを指定するレスポンスヘッダー
HonoとReactアプリを連携させよう
実際にHono (バックエンド) とReact (フロントエンド) を連携させてみましょう。2つの独立したプロジェクトを作成し、APIを通じてデータをやり取りします。
この演習の流れ
- Step 1: Honoでバックエンドを作成する
- Step 2: Reactでフロントエンドを作成する
- Step 3: CORSエラーを解決する
すべて完了すると、「React画面からHono APIを呼び出してデータを表示する」アプリが動きます。
作業ディレクトリの準備
まず、今回の演習用のディレクトリを作成します。
mkdir hono-react-demo
cd hono-react-demo
この中に api (バックエンド) と web (フロントエンド) の2つのプロジェクトを作ります。
hono-react-demo/
├── api/ # Hono (バックエンド)
└── web/ # React (フロントエンド)
Step 1: Honoでバックエンドを作成する
まず、APIサーバーを作ります。
1-1. プロジェクト作成
pnpm create hono@latest api
対話形式で質問されます。以下のように選択してください。
Which template do you want to use? … nodejs
Do you want to install project dependencies? … yes
Which package manager do you want to use? … pnpm
1-2. APIエンドポイントを作成
作成されたディレクトリに移動して、コードを編集します。
cd api
src/index.ts を以下のように書き換えます。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
const app = new Hono();
// /api/hello エンドポイント
app.get("/api/hello", (c) => {
return c.json({
message: "Hello from Hono!",
timestamp: new Date().toISOString(),
});
});
const port = 3000;
console.log(`API Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
1-3. 動作確認
開発サーバーを起動します。
pnpm dev
ブラウザで http://localhost:3000/api/hello にアクセスしてみましょう。
{
"message": "Hello from Hono!",
"timestamp": "2025-01-20T12:00:00.000Z"
}
このようなJSONが表示されれば成功です。このターミナルは開いたままにしておいてください。
Step 2: Reactでフロントエンドを作成する
次に、Reactアプリを作ります。新しいターミナルを開いてください。
2-1. プロジェクト作成
hono-react-demo ディレクトリに戻ります。
cd /path/to/hono-react-demo
Reactプロジェクトを作成します。
pnpm create vite@latest web --template react-ts
2-2. 依存関係のインストール
cd web
pnpm install
2-3. APIを呼び出すコードを書く
src/App.tsx を以下のように書き換えます。
import { useEffect, useState } from "react";
// APIレスポンスの型定義
type HelloResponse = {
message: string;
timestamp: string;
};
function App() {
const [data, setData] = useState<HelloResponse | null>(null);
const [error, setError] = useState<string | null>(null);
useEffect(() => {
// Hono APIを呼び出す
fetch("http://localhost:3000/api/hello")
.then((res) => res.json())
.then((json) => setData(json))
.catch((err) => setError(err.message));
}, []);
return (
<div style={{ padding: "2rem", fontFamily: "sans-serif" }}>
<h1>Hono + React Demo</h1>
{error && (
<div style={{ color: "red", marginBottom: "1rem" }}>
<strong>Error:</strong> {error}
</div>
)}
{data ? (
<div>
<p>
<strong>Message:</strong> {data.message}
</p>
<p>
<strong>Timestamp:</strong> {data.timestamp}
</p>
</div>
) : (
<p>Loading...</p>
)}
</div>
);
}
export default App;
2-4. 開発サーバーを起動
pnpm dev
ブラウザで http://localhost:5173 にアクセスします。
2-5. CORSエラーに遭遇!
画面を見ると…エラーが表示されています!
ブラウザの開発者ツール (F12) を開いて、Consoleタブを確認してみましょう。
Access to fetch at 'http://localhost:3000/api/hello' from origin
'http://localhost:5173' has been blocked by CORS policy:
No 'Access-Control-Allow-Origin' header is present on the requested resource.
これがCORSエラーです。ReactとHonoはポート番号が違うため、別のオリジンとして扱われています。ブラウザのセキュリティ機能により、リクエストがブロックされているのです (詳しくは概要を参照) 。
Step 3: CORSエラーを解決する
Honoに cors() ミドルウェアを追加して、Reactからのリクエストを許可しましょう。
3-1. Honoのコードを修正
Honoのターミナルで一度 Ctrl+C でサーバーを停止してください。
api/src/index.ts を以下のように修正します。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
import { cors } from "hono/cors"; // 追加
const app = new Hono();
// CORSミドルウェアを適用
app.use(
"/api/*",
cors({
origin: "http://localhost:5173", // Reactのオリジンを許可
}),
);
// /api/hello エンドポイント
app.get("/api/hello", (c) => {
return c.json({
message: "Hello from Hono!",
timestamp: new Date().toISOString(),
});
});
const port = 3000;
console.log(`API Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
3-2. 再起動して確認
pnpm dev
ブラウザで http://localhost:5173 をリロードしてみましょう。
Hono + React Demo
Message: Hello from Hono!
Timestamp: 2025-01-20T12:00:00.000Z
データが表示されました!
3-3. 何が変わったの?
開発者ツールの「Network」タブで /api/hello へのリクエストを確認すると、レスポンスヘッダーに以下が追加されています。
Access-Control-Allow-Origin: http://localhost:5173
このヘッダーにより、ブラウザは「このリクエストはサーバーが許可している」と判断し、データを受け取れるようになりました。
cors()ミドルウェアのオプション
cors() ミドルウェアにはいくつかの設定オプションがあります。
複数のオリジンを許可
app.use(
"/api/*",
cors({
origin: ["http://localhost:5173", "http://localhost:3001"],
}),
);
すべてのオリジンを許可 (開発用)
app.use(
"/api/*",
cors({
origin: "*", // 全オリジン許可 (本番では非推奨)
}),
);
注意:
origin: "*"は開発時には便利ですが、本番環境では具体的なオリジンを指定しましょう。
認証情報 (Cookie等) を含める場合
app.use(
"/api/*",
cors({
origin: "http://localhost:5173",
credentials: true, // Cookieなどを許可
}),
);
完成コード
Hono (api/src/index.ts)
import { serve } from "@hono/node-server";
import { Hono } from "hono";
import { cors } from "hono/cors";
const app = new Hono();
app.use(
"/api/*",
cors({
origin: "http://localhost:5173",
}),
);
app.get("/api/hello", (c) => {
return c.json({
message: "Hello from Hono!",
timestamp: new Date().toISOString(),
});
});
const port = 3000;
console.log(`API Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
React (web/src/App.tsx)
import { useEffect, useState } from "react";
type HelloResponse = {
message: string;
timestamp: string;
};
function App() {
const [data, setData] = useState<HelloResponse | null>(null);
const [error, setError] = useState<string | null>(null);
useEffect(() => {
fetch("http://localhost:3000/api/hello")
.then((res) => res.json())
.then((json) => setData(json))
.catch((err) => setError(err.message));
}, []);
return (
<div style={{ padding: "2rem", fontFamily: "sans-serif" }}>
<h1>Hono + React Demo</h1>
{error && (
<div style={{ color: "red", marginBottom: "1rem" }}>
<strong>Error:</strong> {error}
</div>
)}
{data ? (
<div>
<p>
<strong>Message:</strong> {data.message}
</p>
<p>
<strong>Timestamp:</strong> {data.timestamp}
</p>
</div>
) : (
<p>Loading...</p>
)}
</div>
);
}
export default App;
やってみよう!
演習が完了したら、以下を試してみましょう。
1. 別のエンドポイントを追加する
Honoに /api/time エンドポイントを追加して、現在時刻だけを返すようにしてみましょう。
app.get("/api/time", (c) => {
return c.json({
time: new Date().toLocaleTimeString("ja-JP"),
});
});
2. Reactで呼び出す
React側でボタンをクリックしたら /api/time を呼び出すように改修してみましょう。
3. CORSを外してエラーを確認
cors() ミドルウェアをコメントアウトして、再びCORSエラーが発生することを確認してみましょう。
プロジェクトの再現手順 (まとめ)
復習時にすぐ再現できるよう、全手順をまとめておきます。
# 1. 作業ディレクトリ作成
mkdir hono-react-demo && cd hono-react-demo
# 2. Honoプロジェクト作成
pnpm create hono@latest api
# → nodejs, yes, pnpm を選択
# 3. Reactプロジェクト作成
pnpm create vite@latest web --template react-ts
cd web && pnpm install && cd ..
# 4. Honoのコードを編集 (cors()を追加)
# api/src/index.ts を編集
# 5. Reactのコードを編集 (fetch追加)
# web/src/App.tsx を編集
# 6. 両方のサーバーを起動 (別々のターミナルで)
# ターミナル1: cd api && pnpm dev
# ターミナル2: cd web && pnpm dev
# 7. http://localhost:5173 で確認
ポイント
Honoのcors()ミドルウェア
cors(): CORSを有効にするミドルウェアorigin: 許可するオリジンを指定 (文字列または配列)credentials: Cookie等の認証情報を含める場合はtrue"*": 全オリジン許可 (開発用、本番非推奨)
開発時の構成
- バックエンド (Hono): ポート3000で起動
- フロントエンド (React): ポート5173で起動 (Viteのデフォルト)
- 異なるポート = 異なるオリジン → CORSの設定が必要
参考文献
今日こそ理解するCORS
SQLiteハンズオン
これまでのハンズオンでは、ToDoデータをメモリ上の配列に保存していました。サーバーを再起動するとデータは消えてしまいますよね。実際のアプリケーションでは、データをファイルやデータベースに永続化する必要があります。
このセクションでは、Node.js v22.5.0で追加された node:sqlite モジュールを使って、SQLiteデータベースにデータを保存する方法を学びます。SQLの基本を理解したうえで、ToDoアプリのデータを永続化できるようになることを目指しましょう。
目次
概要
Webアプリケーションでデータを保存するとき、どんな仕組みが使われているのでしょうか?
以前学んだ「モダンWebアーキテクチャ」の知識を踏まえて、実際にデータを扱う方法を見ていきましょう。
3層アーキテクチャ
データがどう流れるのか見ていきましょう。典型的には大きく3つの層に分かれています。
graph TD
%% ノード定義:HTMLタグを使用して左揃えと幅を確保
Browser["<div style='text-align: left; min-width: 600px; padding: 5px;'><b>ブラウザ (React、Vueなど)</b><br/>- UIの描画・ユーザー体験の最適化<br/>- ユーザー操作の受け付け<br/>- バックエンドAPIへのリクエスト送信</div>"]
Server["<div style='text-align: left; min-width: 600px; padding: 5px;'><b>APIサーバー (Hono、Expressなど)</b><br/>- リクエストの処理・ビジネスロジックの実行<br/>- 認証・認可・セキュリティ管理<br/>- データベースへの読み書き<br/>- レスポンスの生成</div>"]
DB["<div style='text-align: left; min-width: 600px; padding: 5px;'><b>データベース (SQLite、PostgreSQL、MySQLなど)</b><br/>- データの永続化 (ファイルやディスクへの保存)<br/>- データの検索・集計・分析<br/>- データの整合性保証 (トランザクション管理)</div>"]
%% 構造定義
subgraph Frontend_Layer [フロントエンド層]
direction TB
Browser
end
subgraph Backend_Layer [バックエンド層]
direction TB
Server
end
subgraph Data_Layer [データ層]
direction TB
DB
end
%% 接続
Frontend_Layer -->|"HTTP (REST API)"| Backend_Layer
Backend_Layer -->|SQL| Data_Layer
%% スタイル定義
style Frontend_Layer fill:#e1f5fe,stroke:#01579b
style Backend_Layer fill:#fff3e0,stroke:#e65100
style Data_Layer fill:#f3e5f5,stroke:#4a148c
%% ノード自体の背景色
style Browser fill:#ffffff,stroke:#333,stroke-width:1px
style Server fill:#ffffff,stroke:#333,stroke-width:1px
style DB fill:#ffffff,stroke:#333,stroke-width:1px
フロントエンドとバックエンド
「モダンWebアーキテクチャ」で見た通り、現代のWebアプリケーション開発では、フロントエンドエンジニアとバックエンドエンジニアで役割が分かれることが多いです。データベースはバックエンドの重要な担当領域ですが、フロントエンドエンジニアも理解しておくと協業がスムーズになります。
フロントエンドエンジニアの責務
ユーザーが直接触れる部分を担当します。
| 技術領域 | 主な課題 |
|---|---|
| UI/UX | 画面のデザイン実装、ユーザー操作のハンドリング |
| 状態管理 | フォームの入力値、表示データの管理 |
| API連携 | fetch/axiosでのリクエスト送信、レスポンス処理 |
| バリデーション | 入力値の形式チェック (最終チェックはバックエンド) |
// フロントエンドでのAPI連携の例 (React)
import useSWR from "swr";
function TodoList() {
// SWRでバックエンドAPIからデータを取得
const { data: todos, error, mutate } = useSWR("/api/todos");
if (error) return <div>エラーが発生しました</div>;
if (!todos) return <div>読み込み中...</div>;
return (
<ul>
{todos.map((todo) => (
<li key={todo.id}>{todo.title}</li>
))}
</ul>
);
}
バックエンドエンジニアの責務
ドメインロジックとデータ処理を担当します (このハンズオンで学ぶ領域です)。
| 技術領域 | 主な課題 |
|---|---|
| API設計・実装 | エンドポイントの設計、リクエスト/レスポンスの処理 |
| ドメインロジック | アプリケーション固有のルールや制約の実装 |
| データベース | テーブル設計、SQL作成、データの読み書き |
| バリデーション | 入力値の検証、エラーハンドリング |
| セキュリティ | 認証・認可、SQLインジェクション対策 |
// バックエンドでのAPI実装の例 (Hono)
import { Hono } from "hono";
import { DatabaseSync } from "node:sqlite";
const app = new Hono();
const db = new DatabaseSync("data.db");
const sql = db.createTagStore();
// ToDoリスト取得API
app.get("/api/todos", (c) => {
// データベースから全件取得
const todos = sql.all`SELECT * FROM todos`;
return c.json(todos);
});
// ToDo作成API
app.post("/api/todos", async (c) => {
const { title } = await c.req.json();
// データベースに保存
const result = sql.run`INSERT INTO todos (title, completed) VALUES (${title}, ${false})`;
return c.json({ id: result.lastInsertRowid, title, completed: false }, 201);
});
境界線は曖昧になりつつある
以前触れたように、最近はこの境界線が曖昧になってきています。
- フルスタックフレームワーク (Next.jsやAstroなど) の登場で、フロントエンドエンジニアもサーバーサイドのコードを書く機会が増えた
- サーバーレスアーキテクチャにより、インフラ管理の負担が軽減された
- 小規模なチームでは、両方を担当することも多い
このハンズオンで学ぶSQLiteとSQLの知識は、どちらの立場でも役立ちます (フロントエンド寄りでも、データの仕組みを理解しているとAPI設計の会話がスムーズになります)。
データベースの種類とアーキテクチャ選択
アーキテクチャパターンによって、データベースの選択も変わってきます。
リレーショナルデータベース (RDB)
データをテーブル (表) の形式で管理します。テーブル同士を関連付けて、複雑なデータ構造を表現できます (伝統的で信頼性の高い方式です)。
| 名前 | 特徴 | 適したアーキテクチャ |
|---|---|---|
| SQLite | ファイルベース、サーバー不要、組み込み向け | モノリシック、小規模サーバーレス |
| PostgreSQL | 高機能、大規模向け、クラウドサービスで人気 | マイクロサービス、大規模モノリシック |
これらは全てSQL (Structured Query Language)という共通言語でデータを操作します (一度学べば、どのRDBでも応用できますね)。
-- SQLの例 (どのRDBでもほぼ同じ)
SELECT * FROM todos WHERE completed = false;
INSERT INTO todos (title, completed) VALUES ('買い物', false);
UPDATE todos SET completed = true WHERE id = 1;
NoSQLデータベース
テーブル形式以外の方法でデータを管理します。柔軟性が高く、大規模分散システムに適しています。
| 名前 | データ形式 | 特徴 |
|---|---|---|
| Redis | キー・バリュー | 超高速、キャッシュ向け |
| DynamoDB | キー・バリュー | AWSのマネージドサービス |
このハンズオンでSQLiteを使う理由
アーキテクチャ選択は組織やプロジェクトの状況に合わせるべきです。このハンズオンでは、学習に最適なSQLiteを選びました。
- サーバー不要: ファイル1つで動作するので、セットアップが簡単 (インフラ管理の学習負荷を減らせます)
- Node.js組み込み: Node.js v22.5.0から標準で使える (追加のインストール不要)
- SQLの学習に最適: 本格的なRDBと同じSQLが使える (PostgreSQLやMySQLへの移行も容易)
- 実用的: 小〜中規模アプリなら本番でも十分使える (モノリシックアーキテクチャに最適)
// Node.js標準のSQLite (追加パッケージ不要)
import { DatabaseSync } from "node:sqlite";
const db = new DatabaseSync("data.db");
db.exec(`
CREATE TABLE IF NOT EXISTS todos (
id INTEGER PRIMARY KEY,
title TEXT
);
`);
データの流れを追ってみよう
ToDoアプリで「新しいタスクを追加する」操作を例に、3層アーキテクチャでのデータの流れを見てみましょう。
- ユーザーがフォームに入力して送信ボタンをクリック
- フロントエンド (fetch API) でPOSTリクエストを送信
fetch("/api/todos", { method: "POST", body: JSON.stringify({ title: "買い物" }), }); - バックエンド (Hono) がリクエストを受け取り、データをバリデーション
app.post("/api/todos", async (c) => { const { title } = await c.req.json(); // バリデーション: titleが空でないかチェック if (!title) return c.json({ error: "Title is required" }, 400); // データベースに保存処理へ進む // ... }); - SQLを実行しデータベースに保存
sql.run(`INSERT INTO todos (title) VALUES (${"買い物"})`); - データベースへの保存を確定し、新しいIDを返す
→{ lastID: 1, changes: 1 } - バックエンドがレスポンスを生成して返す
return c.json({ id: 1, title: "買い物", completed: false }, 201); - フロントエンドがレスポンスを受け取り、ReactなどでUIを更新
setTodos([...todos, newTodo]);
このハンズオンでは、3〜6の部分 (バックエンド層とデータ層)を実装していきます。
アーキテクチャと実装の関係
それぞれのアーキテクチャパターンが、実際の実装にどう影響するか見てみましょう。
モノリシック + SQLite (このハンズオンの構成)
[Todoアプリ]
├─ /app (フロントエンド)
└─ /api (バックエンドAPI)
└─ data.db (SQLiteファイル)
✅ 適している状況:
- 小規模チーム (1-5人)
- 学習・プロトタイプ開発
- 中規模アプリ
大規模・分散システム向けの構成
アプリケーションが成長すると、より強力なデータベースや分散アーキテクチャが必要になります。
例: マイクロサービス + PostgreSQL/MySQL
[ユーザーサービス] [ToDoサービス] [通知サービス]
↓ ↓ ↓
[PostgreSQL] [PostgreSQL] [PostgreSQL]
例: エッジランタイム + 分散データベース
エッジランタイム(以前学んだCloudflare WorkersやVercel Edge Functionsなど)では、従来とは異なるデータベース選択が必要です。
[Cloudflare Workers] → [Durable Objects (SQLite API)]
→ [Hyperdrive (PostgreSQL接続)]
[Vercel Edge Functions] → [Vercel Postgres]
→ [Upstash Redis]
✅ 適している状況:
- 大規模チーム(複数の独立したチーム)
- 高いスケーラビリティと可用性が必要
- 世界中のユーザーを対象とするアプリケーション
代表的な技術
Honoの章で学んだように、エッジランタイムには実行時間やメモリの制約があります。そのため、データベースも特別な選択肢が用意されています。
- Hyperdrive: 既存のPostgreSQLやMySQLをエッジから高速アクセスできる接続プール技術
- Durable Objects (SQLite API): 世界中のエッジサーバーに分散されたSQLite互換のストレージ。各地域でデータを保持しながら低遅延アクセスを実現
// Hyperdriveを使う例
import postgres from "postgres";
const sql = postgres(env.HYPERDRIVE.connectionString);
export const todo = {
async all() {
return await sql`SELECT * FROM todos`;
},
};
// Durable Objectsを使う例
export class TodoStorage extends DurableObject {
sql: SqlStorage;
constructor(ctx: DurableObjectState, env: Env) {
super(ctx, env);
this.sql = ctx.storage.sql;
}
async all() {
return Array.from(this.sql.exec("SELECT * FROM todos;"));
}
}
Note エッジランタイムでのデータベースは急速に進化しています。以前学んだ「結果整合性」の概念を理解した上で、適切な技術を選択することが重要です。
組織構造とアーキテクチャを一致させることが重要です。このハンズオンでは、学習に最適なモノリシック + SQLiteの構成で進めます。分散システムでのデータベース活用は、基礎を学んだ後の応用編として挑戦してみてください。
ポイント
- 3層アーキテクチャ: フロントエンド層・バックエンド層・データ層の3つで構成
- SQL: RDBを操作する共通言語。SQLite、PostgreSQL、MySQLなど様々なDBで共通
- SQLite: ファイル1つで動作するRDB。Node.js標準で使え、学習・小規模アプリに最適
次のセクションでは、実際にSQLiteを使ってデータベースを操作していきます。
Node.jsでSQLiteを使う

Node.js v22.5.0から、SQLiteを扱うための新しいAPIが追加されました。外部ライブラリをインストールせずに、Node.jsだけでSQLiteデータベースを操作できます。
2つの新機能
Node.jsには、SQLite関連の機能が2つ追加されています。
1. node:sqlite モジュール
Node.js v22.5.0で追加された、SQLiteデータベースを操作するためのモジュールです。
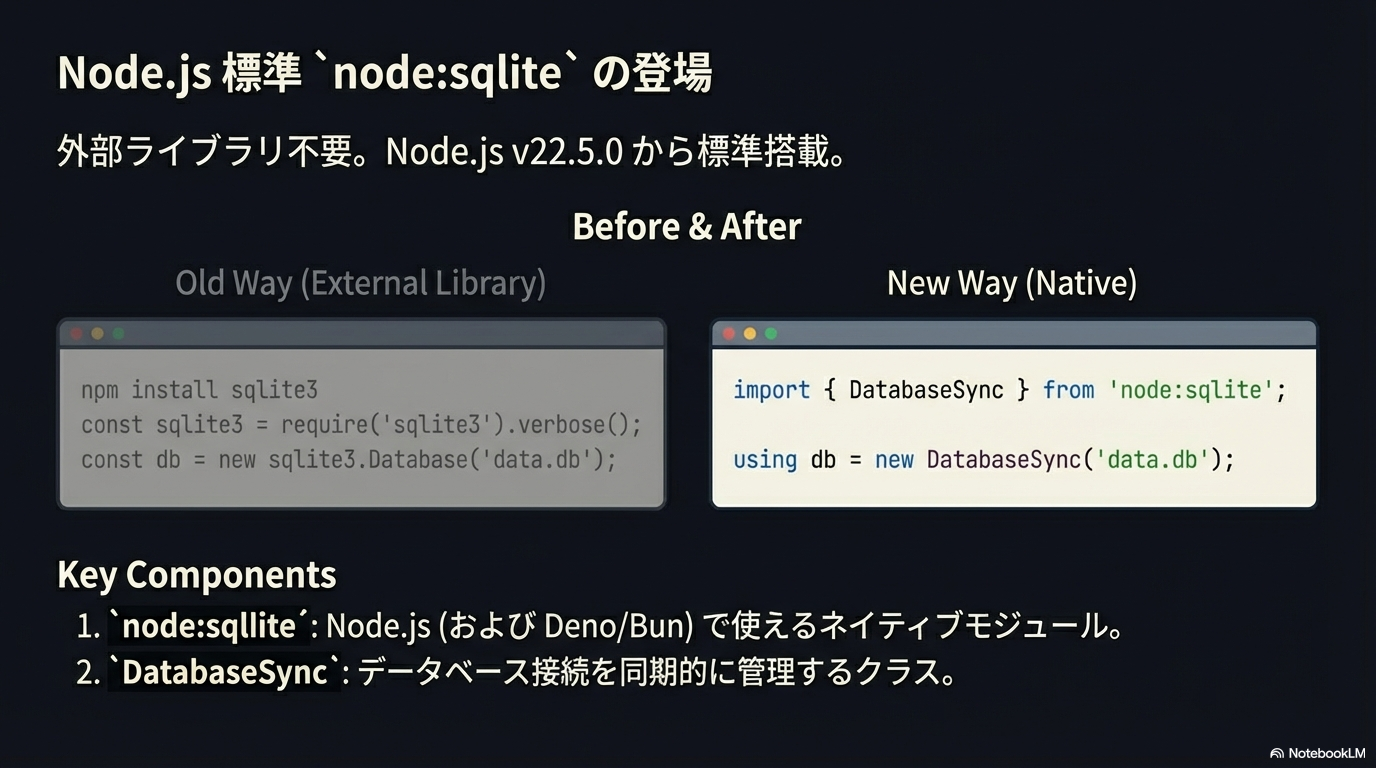
import { DatabaseSync } from "node:sqlite";
using db = new DatabaseSync("data.db");
db.exec(`
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT
);
`);
Note
usingとは?このコードには
usingというキーワードがあります。これは Node.js v24 以降で利用可能な Explicit Resource Management という新しい構文で、変数がスコープを抜けるときに自動的にリソースを解放してくれます。ここではSQLクエリ実行後、終了前に自動的にdb.close()が呼ばれます。 ただし、このハンズオンではより広い環境で使えるようにusingを使わないコードで説明します。
2. --experimental-webstorage フラグ
実験的な機能として、localStorage API をNode.jsで使えるようにするフラグです。ブラウザの localStorage と同じAPIで、データを永続化できます (Node.js v24.9.0以降で利用可能)。
node --experimental-webstorage --localstorage-file=localstorage.db main.js
// ブラウザと同じAPIが使える!
localStorage.setItem("username", "田中太郎");
console.log(localStorage.getItem("username")); // "田中太郎"
このハンズオンでは、より柔軟で実践的な node:sqlite モジュール を使ってSQLiteを学びます。
node:sqlite モジュールを試してみよう
早速、node:sqlite を使ってみましょう。
準備
新しいディレクトリを作成して、プロジェクトを初期化します。
mkdir node-sqlite
cd node-sqlite
pnpm init --init-type=module
最初のコード
main.js を作成して、以下のコードを書いてみましょう。
#!/usr/bin/env node
import { DatabaseSync } from "node:sqlite";
// データベースに接続 (ファイルがなければ自動で作成される)
const db = new DatabaseSync("data.db");
console.log("データベースに接続しました!");
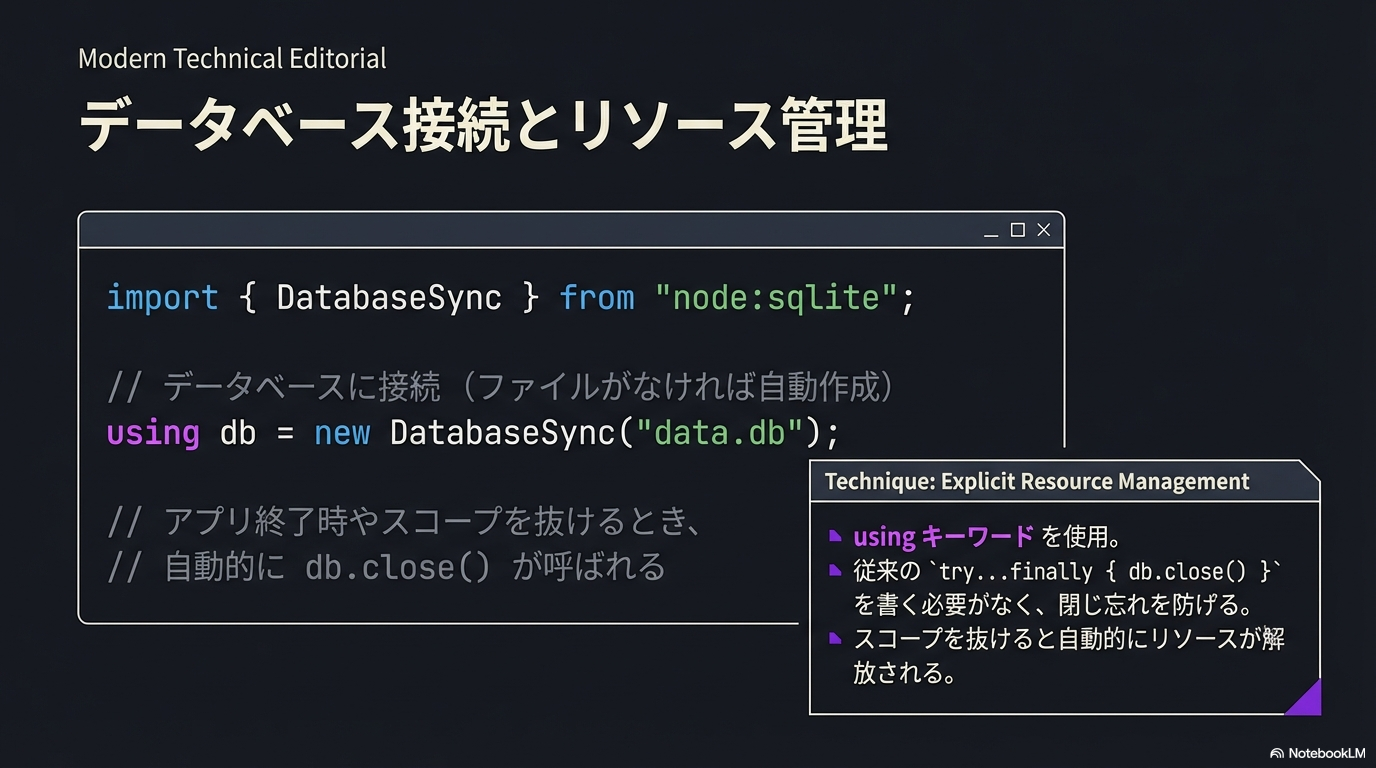
実行してみましょう。
node main.js
# あるいは、実行権限を付与して実行
chmod +x main.js
# 実行
./main.js
データベースに接続しました!
カレントディレクトリに data.db というファイルが作成されているはずです。これがSQLiteのデータベースファイルです。
ls -la
-rw-r--r-- 1 user staff 8192 1月 20 10:00 data.db
DatabaseSyncクラスの基本
node:sqlite の中心となるのが DatabaseSync クラスです。基本的な使い方を見ていきましょう。
データベースへの接続
import { DatabaseSync } from "node:sqlite";
// ファイルベースのデータベース
const db = new DatabaseSync("data.db");
// メモリ上のデータベース (一時的なデータベース)
const memoryDb = new DatabaseSync(":memory:");
db.exec() - 基本的なSQLを実行する
テーブルの作成など、結果を返さないSQLを実行するときに使います。

users テーブルのイメージ:
| id (PK) | name | |
|---|---|---|
| - | - | - |
db.exec(`
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT
);
`);
Note
Prisma Studioで実際にデータベースを確認する方法実際に手元のSQLiteのファイル
data.dbにテーブルが作成されているか確認してみましょう。 Prisma Studio を使うとデータベースをGUIで確認・操作できるので非常に便利ですよ。
- ターミナルで
npx prisma studio --url=file:data.dbを実行- 表示されるURL http://localhost:51212 にブラウザでアクセス
usersテーブルが作成されていることを確認
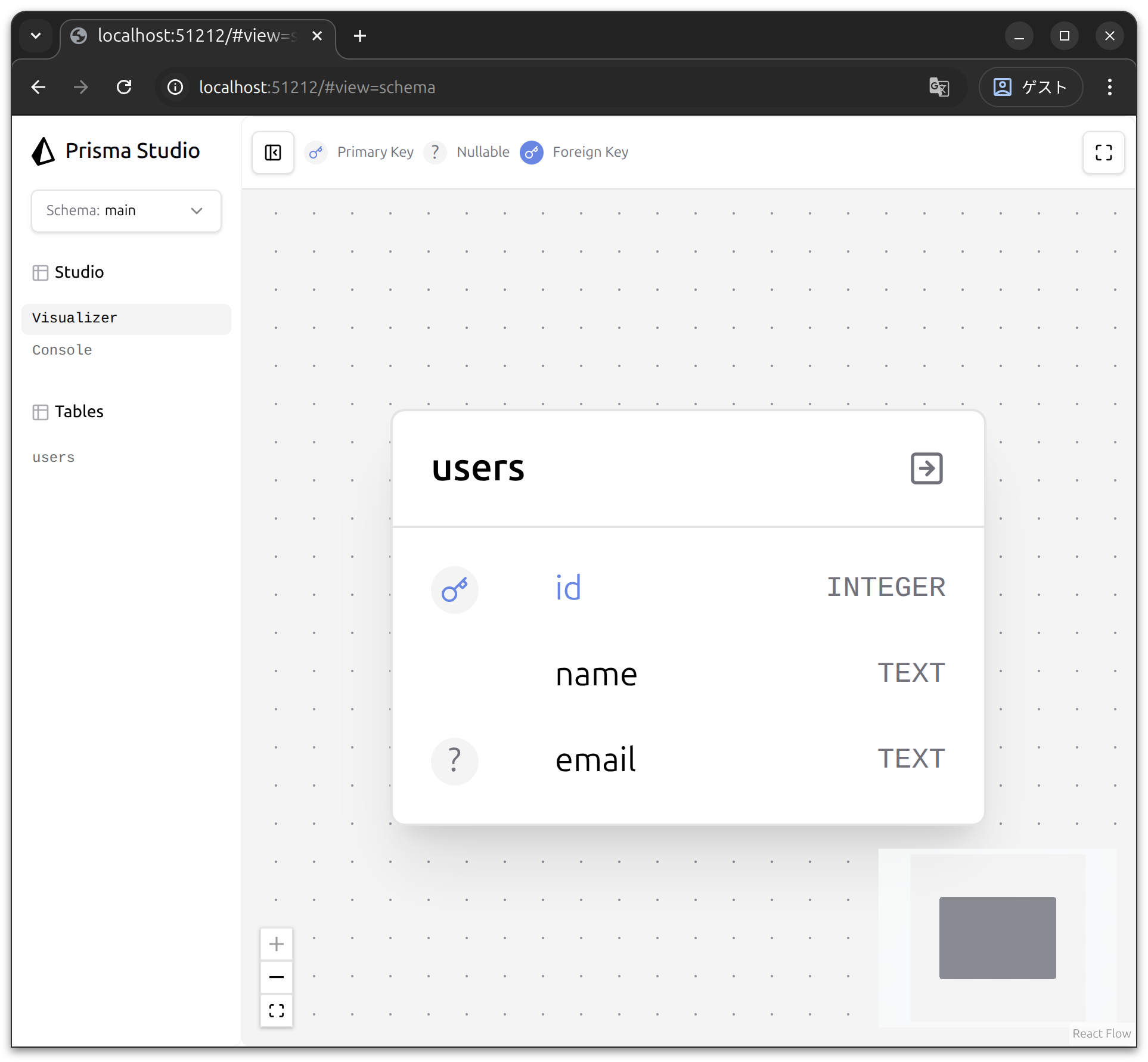
db.createTagStore() - タグ付きテンプレートでSQLを実行する
db.createTagStore() を使うと、タグ付きテンプレートでSQLを実行できます。より読みやすく、安全なコードになります。
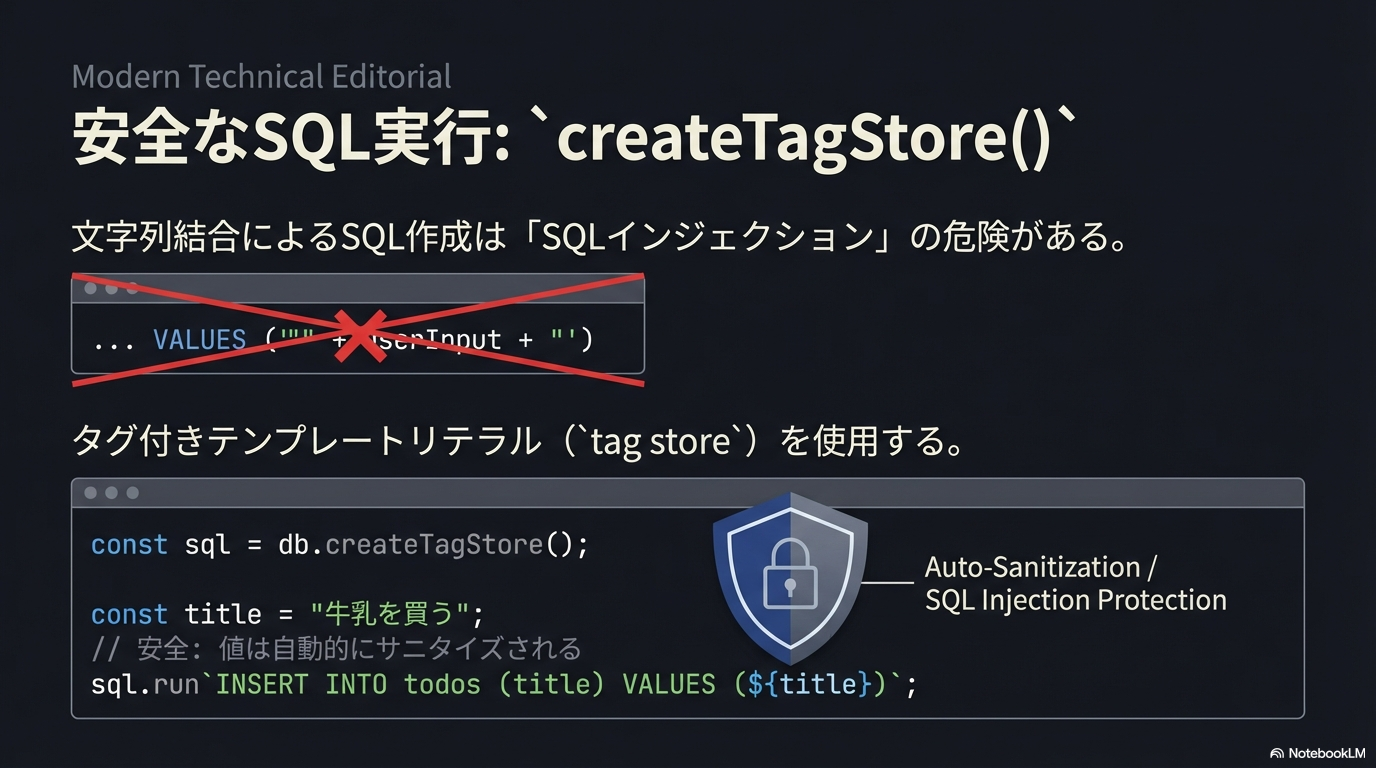
// タグストアを作成
const sql = db.createTagStore();
// データを挿入
sql.run`INSERT INTO users (name, email) VALUES (${"田中太郎"}, ${"tanaka@example.com"})`;
// 1件取得
const user = sql.get`SELECT * FROM users WHERE id = ${1}`;
console.log(user); // { id: 1, name: '田中太郎', email: 'tanaka@example.com' }
// 全件取得
const users = sql.all`SELECT * FROM users`;
console.log(users); // [{ id: 1, ... }, { id: 2, ... }]
${} の中に値を埋め込むと、自動的に SQLインジェクション対策がされます。安全で読みやすい書き方ですね
実践: ユーザーの登録と取得
学んだことを使って、ユーザーを登録・取得するプログラムを書いてみましょう。
main.js を以下のように書き換えます。
import { DatabaseSync } from "node:sqlite";
const db = new DatabaseSync("data.db");
const sql = db.createTagStore();
// テーブルを作成 (すでにテーブルが存在する場合は何もしない)
db.exec(`
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT,
created_at TEXT DEFAULT CURRENT_TIMESTAMP
);
`);
console.log("テーブルを作成しました");
// ユーザーを追加
const result1 = sql.run`INSERT INTO users (name, email) VALUES (${"田中太郎"}, ${"tanaka@example.com"})`;
console.log("追加しました:", result1);
const result2 = sql.run`INSERT INTO users (name, email) VALUES (${"山田花子"}, ${"yamada@example.com"})`;
console.log("追加しました:", result2);
// 全ユーザーを取得
const users = sql.all`SELECT * FROM users`;
console.log("\n登録されているユーザー:");
for (const user of users) {
console.log(` ${user.id}: ${user.name} (${user.email})`);
}
実行してみましょう。
node main.js
テーブルを作成しました
追加しました: { changes: 1, lastInsertRowid: 1 }
追加しました: { changes: 1, lastInsertRowid: 2 }
登録されているユーザー:
1: 田中太郎 (tanaka@example.com)
2: 山田花子 (yamada@example.com)
users テーブルのイメージ:
| id (PK) | name | |
|---|---|---|
| 1 | 田中太郎 | tanaka@example.com |
| 2 | 山田花子 | yamada@example.com |
もう一度実行すると、さらにユーザーが追加されます (IDは3, 4になります)。これがデータの永続化です。
sql.run の戻り値
sql.run は、実行結果の情報を返します。
const result = sql.run`INSERT INTO users (name, email) VALUES (${"佐藤次郎"}, ${"sato@example.com"})`;
console.log(result);
// {
// changes: 1, // 影響を受けた行数
// lastInsertRowid: 3 // 最後に挿入された行のID
// }
- changes: INSERT、UPDATE、DELETEで影響を受けた行数
- lastInsertRowid: INSERTで自動生成されたID
エラーハンドリング
SQLにエラーがあると例外がスローされます。
try {
db.exec("CREATE TABLE invalid syntax;");
} catch (error) {
console.error("SQLエラー:", error.message);
}
やってみよう
main.jsを実行して、ユーザーが追加されることを確認しましょう- 何度か実行して、データが蓄積されることを確認しましょう
data.dbを削除してから実行すると、どうなるか試してみましょう
ポイント

node:sqlite: Node.js (Deno/Bunでも使える) SQLite モジュールDatabaseSync: データベース接続を管理するクラスdb.exec(sql): 結果を返さないSQLを実行 (CREATE TABLEなど)db.createTagStore(): タグ付きテンプレートでSQLを実行できるストアを作成sql.run: INSERT/UPDATE/DELETEを実行。自動的にSQLインジェクション対策されるsql.get: 1件取得sql.all: 全件取得
参考文献
ToDoアプリで学ぶSQL入門
このチュートリアルでは、SQL (Structured Query Language) の基本を学びながら、Node.js標準の node:sqlite を使って、データをデータベースに保存する「永続化」アプリへと作り変えていきます。
SQLの4大操作: CRUD
SQLite を使う準備ができたので、SQLの基本を学んでいきましょう。SQL (Structured Query Language)は、データベースを操作するための言語です。 データベース操作は、基本的に4つの操作に分類できます。これを CRUD (クラッド)と呼びます。
CRUD操作とSQLの対応
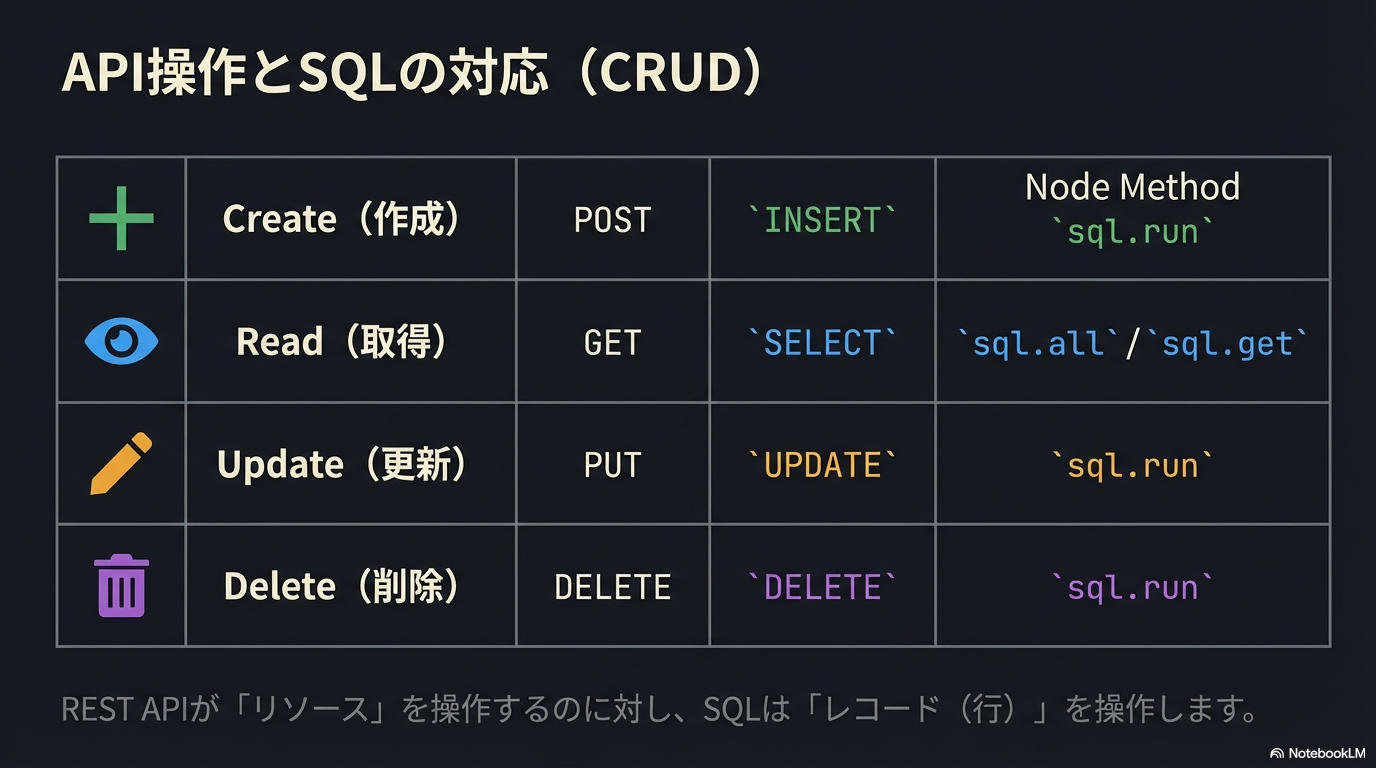
具体例:
// 新しい ToDo を作成
sql.run`INSERT INTO todos (title) VALUES (${"牛乳を買う"})`;
// 全ての ToDo を取得
sql.all`SELECT * FROM todos`;
// ID 1 の ToDo を取得
sql.get`SELECT * FROM todos WHERE id = ${1}`;
// ID 1 の ToDo を完了に更新
sql.run`UPDATE todos SET completed = ${1} WHERE id = ${1}`;
// ID 1 の ToDo を削除
sql.run`DELETE FROM todos WHERE id = ${1}`;
見覚えのあるおなじみパターンですよね。「REST API」と全く同じ概念です。REST APIが「リソース」を操作するのに対し、SQLは「データ (レコード)」を操作します。
準備: テンプレートのセットアップ
まずは、ベースとなるToDoアプリのテンプレートを用意します。ターミナルで以下のコマンドを実行してください。
git clone https://github.com/kou029w/todo-template.git
cd todo-template
pnpm i
pnpm dev
ブラウザで http://localhost:5173 にアクセスするとアプリが動きますが、サーバーを停止(Ctrl+C)して再起動するとデータは消えてしまいます。これを直していきましょう。
今回編集するのは、バックエンド側の api/src/index.ts です。
データベースとテーブルの作成
まずはデータを保存する箱、「テーブル」を作る必要があります。Excelのシートを作るようなイメージですね。
CREATE TABLE の構文
CREATE TABLE IF NOT EXISTS テーブル名 (
カラム名 データ型 制約,
...
);
IF NOT EXISTS を付けることで、既にテーブルが存在する場合は作成をスキップします。これにより、サーバー再起動時にエラーになるのを防げます。
具体例 (SQL):
CREATE TABLE IF NOT EXISTS todos (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
completed INTEGER NOT NULL DEFAULT 0
);
ここで使う INTEGER は整数、TEXT は文字列、PRIMARY KEY は主キー(ID)を意味します。
NOT NULL は必須、DEFAULT はデフォルト値を指定します。
Note: SQLiteでは、
boolean型が存在しません。代わりにINTEGER型の0(false)と1(true)を使用します。
やってみよう: データベースとテーブル作成
todos テーブルのイメージ:
| id (PK) | title | completed |
|---|---|---|
| INTEGER | TEXT | INTEGER |
api/src/index.ts の冒頭を以下のように書き換えて、データベース (data.db ファイル) に接続し、テーブルを作りましょう。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
import { cors } from "hono/cors";
// node:sqlite をインポート
import { DatabaseSync } from "node:sqlite";
const app = new Hono();
app.use("/*", cors());
// データベースに接続
const db = new DatabaseSync("data.db");
const sql = db.createTagStore();
// テーブルを作成(なければ作る)
db.exec(`
CREATE TABLE IF NOT EXISTS todos (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
completed INTEGER NOT NULL DEFAULT 0
);
`);
console.log("データベースを初期化しました");
// ※ 古い let todos = []; などの変数は削除
データの取得
次に、保存されたデータを取得して表示できるようにします。

SELECT 文
データを取得するには SELECT を使います。「todos テーブルから全てのカラム (*) を取得し、id の降順 (DESC) で並べる」という命令は以下のようになります。
SQL:
SELECT * FROM todos ORDER BY id DESC;
やってみよう: 一覧取得の実装
GET /api/todos エンドポイントを修正します。
// GET /api/todos - ToDoの一覧を取得
app.get("/api/todos", (c) => {
const todos = sql.all`SELECT * FROM todos ORDER BY id DESC`;
// SQLiteでは true/false が 1/0 で保存されるため、変換が必要です
const result = todos.map((todo) => ({
id: todo.id,
title: todo.title,
completed: todo.completed === 1,
}));
return c.json(result);
});
型の変換
SQLiteでは、boolean 型が存在しません。代わりに INTEGER 型の 0(false)と 1(true)を使用します。

データの保存時と取得時に型変換が必要です。
データの追加
新しいToDoを追加しましょう。
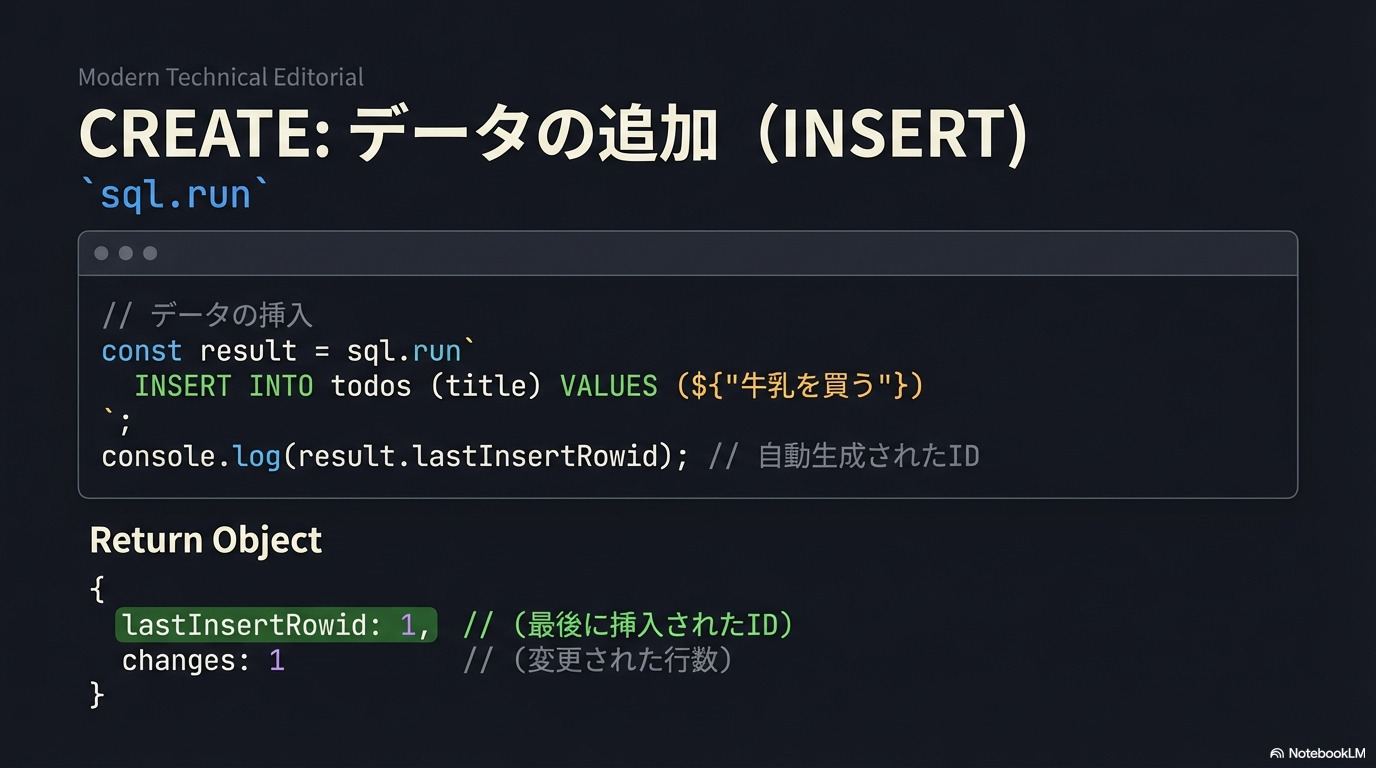
INSERT 文
todos テーブルのイメージ:
| id (PK) | title | completed |
|---|---|---|
| 1 | ‘牛乳を買う’ | 0 |
データを追加するのは INSERT です。
SQL:
INSERT INTO todos (title) VALUES ('牛乳を買う');
Note: SQL文にユーザーからの入力を直接埋め込むのは絶対にNGです。「SQLインジェクション」の危険があります。必ず
${変数}のようにプレースホルダを使って、安全に値を渡しましょう。
// ❌ ダメな例 (SQLインジェクションの危険あり)
const title = "牛乳を買う";
db.exec(`INSERT INTO todos (title) VALUES ('${title}');`);
// ✅ 良い例
const sql = db.createTagStore();
sql.run`INSERT INTO todos (title) VALUES (${title})`;
やってみよう: 新規作成の実装
POST /api/todos エンドポイントを修正します。
// POST /api/todos - 新しいToDoを作成
app.post("/api/todos", async (c) => {
const body = await c.req.json();
if (!body.title || body.title.trim() === "") {
return c.json({ error: "Title is required" }, 400);
}
// データを追加
const result = sql.run`INSERT INTO todos (title) VALUES (${body.title})`;
// 作成した結果のレコードのIDを使って再取得
const newTodo = sql.get`SELECT * FROM todos WHERE id = ${result.lastInsertRowid}`;
return c.json(
{
id: newTodo.id,
title: newTodo.title,
completed: newTodo.completed === 1,
},
201,
);
});
result.lastInsertRowid を使うと、今登録されたデータのIDが分かります。便利ですね。
データの更新・削除
最後に、更新と削除です。
UPDATE 文
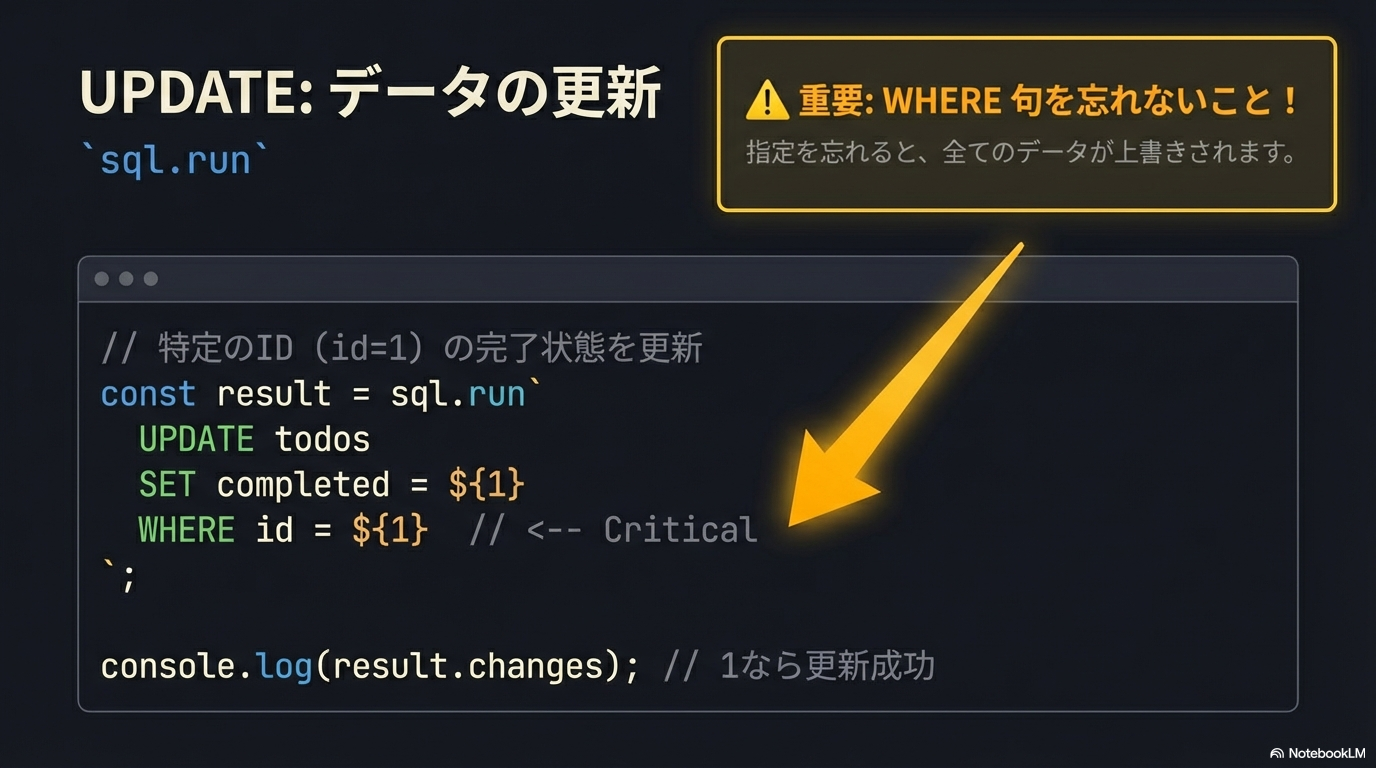
SQL:
-- 更新
UPDATE todos SET completed = 1 WHERE id = 1;
DELETE 文
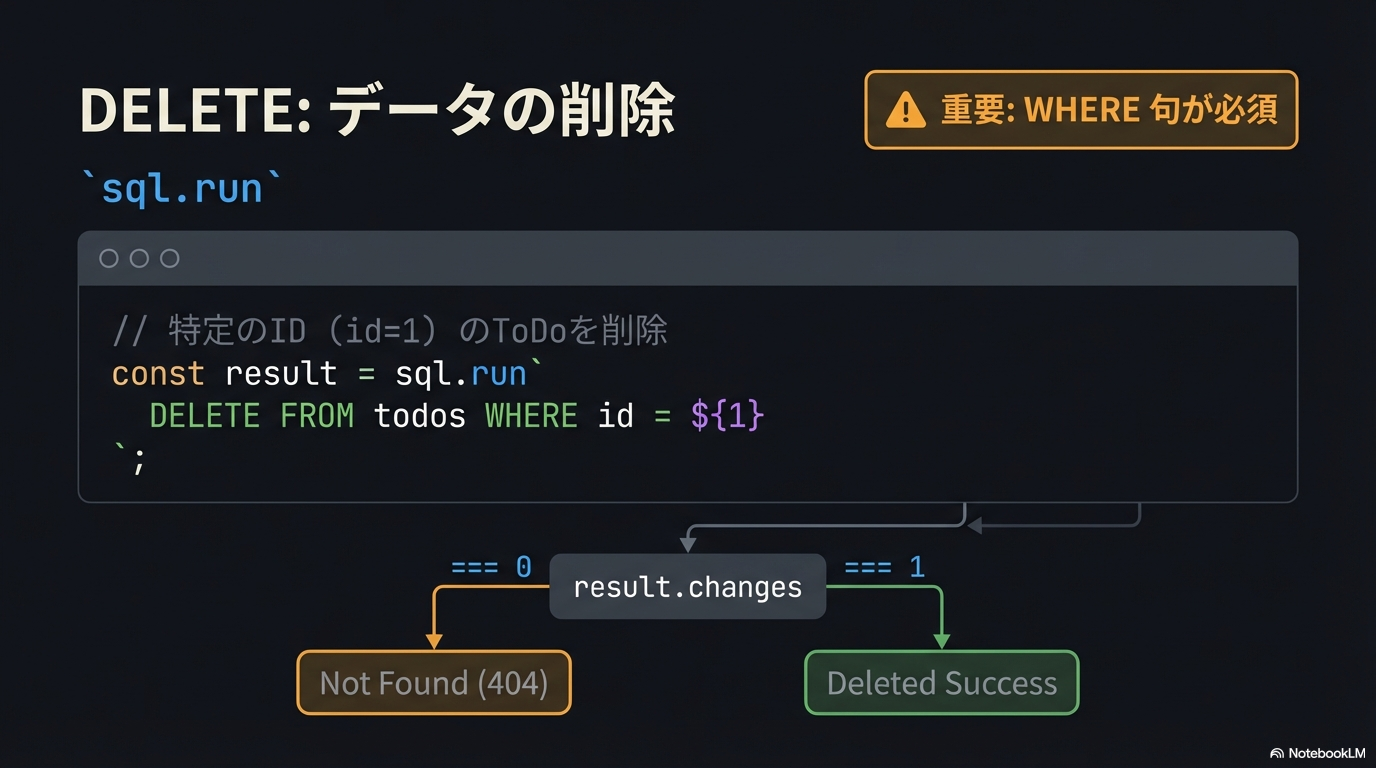
SQL:
-- 削除
DELETE FROM todos WHERE id = 1;
Note:
WHERE(条件)を書き忘れると、全てのデータが更新・削除されてしまいます。操作対象のIDを必ず指定しましょう。
やってみよう: 更新と削除の実装
PUT と DELETE のエンドポイントを修正します。
// PUT /api/todos/:id - ToDoを更新
app.put("/api/todos/:id", async (c) => {
const id = Number(c.req.param("id"));
const body = await c.req.json();
// 部分更新
if (body.title !== undefined) {
const result = sql.run`
UPDATE todos
SET title = ${body.title}
WHERE id = ${id}
`;
// 影響を受けた行数が0なら存在しない
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
}
if (body.completed !== undefined) {
// boolean を 0/1 に変換して保存
const result = sql.run`
UPDATE todos
SET completed = ${body.completed ? 1 : 0}
WHERE id = ${id}
`;
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
}
const updatedTodo = sql.get`SELECT * FROM todos WHERE id = ${id}`;
// 返却時に 0/1 を boolean に戻すのを忘れずに
return c.json({
id: updatedTodo.id,
title: updatedTodo.title,
completed: updatedTodo.completed === 1,
});
});
// DELETE /api/todos/:id - ToDoを削除
app.delete("/api/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const result = sql.run`DELETE FROM todos WHERE id = ${id}`;
// 影響を受けた行数が0なら存在しなかった
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
return c.json({ message: "Deleted" });
});
動作確認
サーバーを再起動して、動作を確認しましょう。
pnpm dev
- ブラウザで http://localhost:5173 にアクセス
- いくつかToDoを追加
Ctrl+Cでサーバーを停止pnpm devで再起動- ToDoが残っていることを確認!
api/ ディレクトリに data.db ファイルが作成されているはずです。これがSQLiteのデータベースファイルです。
やってみよう!
- ToDoを追加して、サーバーを再起動してもデータが残ることを確認
- ToDoの完了/未完了を切り替えて、再起動後も状態が保持されることを確認
data.dbを削除してからサーバーを起動すると、空のToDoリストになることを確認
ポイント
- 永続化: データをファイル(データベース)に保存することで、サーバー再起動後もデータが残る
- CREATE TABLE: テーブルを作成 (
db.exec()を使用) - INSERT: データ (レコード) を追加 (
sql.runを使用) - SELECT: データを取得 (
sql.getで1件、sql.allで複数件、WHEREで条件指定、ORDER BYで並び替え) - UPDATE: データを更新 (
sql.runを使用、WHERE を忘れず) - DELETE: データを削除 (
sql.runを使用、WHERE を忘れず) - 型変換: SQLiteの
INTEGER(0/1)とJavaScriptのbooleanの変換が必要 sql.run: INSERT/UPDATE/DELETEを実行するために使用result.lastInsertRowid: INSERTで自動生成されたIDを取得result.changes: UPDATE/DELETEで影響を受けた行数を取得
完成コード
すべての修正を反映した api/src/index.ts の完成版です。
import { serve } from "@hono/node-server";
import { Hono } from "hono";
import { cors } from "hono/cors";
import { DatabaseSync } from "node:sqlite";
const app = new Hono();
app.use("/*", cors());
const db = new DatabaseSync("data.db");
const sql = db.createTagStore();
db.exec(`
CREATE TABLE IF NOT EXISTS todos (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
completed INTEGER NOT NULL DEFAULT 0
);
`);
console.log("データベースを初期化しました");
// GET /api/todos - ToDoの一覧を取得
app.get("/api/todos", (c) => {
const todos = sql.all`SELECT * FROM todos ORDER BY id DESC`;
const result = todos.map((todo) => ({
id: todo.id,
title: todo.title,
completed: todo.completed === 1,
}));
return c.json(result);
});
// GET /api/todos/:id - 特定のToDoを取得
app.get("/api/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const todo = sql.get`SELECT * FROM todos WHERE id = ${id}`;
if (!todo) {
return c.json({ error: "Todo not found" }, 404);
}
return c.json({
id: todo.id,
title: todo.title,
completed: todo.completed === 1,
});
});
// POST /api/todos - 新しいToDoを作成
app.post("/api/todos", async (c) => {
const body = await c.req.json();
if (!body.title || body.title.trim() === "") {
return c.json({ error: "Title is required" }, 400);
}
const result = sql.run`INSERT INTO todos (title) VALUES (${body.title})`;
const newTodo = sql.get`SELECT * FROM todos WHERE id = ${result.lastInsertRowid}`;
return c.json(
{
id: newTodo.id,
title: newTodo.title,
completed: newTodo.completed === 1,
},
201,
);
});
// PUT /api/todos/:id - ToDoを更新
app.put("/api/todos/:id", async (c) => {
const id = Number(c.req.param("id"));
const body = await c.req.json();
if (body.title !== undefined) {
const result = sql.run`
UPDATE todos
SET title = ${body.title}
WHERE id = ${id}
`;
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
}
if (body.completed !== undefined) {
const result = sql.run`
UPDATE todos
SET completed = ${body.completed ? 1 : 0}
WHERE id = ${id}
`;
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
}
const updatedTodo = sql.get`SELECT * FROM todos WHERE id = ${id}`;
return c.json({
id: updatedTodo.id,
title: updatedTodo.title,
completed: updatedTodo.completed === 1,
});
});
// DELETE /api/todos/:id - ToDoを削除
app.delete("/api/todos/:id", (c) => {
const id = Number(c.req.param("id"));
const result = sql.run`DELETE FROM todos WHERE id = ${id}`;
if (result.changes === 0) {
return c.json({ error: "Todo not found" }, 404);
}
return c.json({ message: "Deleted" });
});
const port = 3000;
console.log(`Server is running on http://localhost:${port}`);
serve({
fetch: app.fetch,
port,
});
早く進んだ人向け
Honoの公式ドキュメントには、ベストプラクティスがまとめられています。余裕があれば読んでみてください。
特に以下のトピックが参考になります。
- ルーティングの整理方法
- ミドルウェアの活用
- エラーハンドリング
参考文献
Drizzle ORMの紹介
ここまでSQLを直接書いてデータベースを操作してきました。シンプルなアプリケーションならこれで十分ですが、規模が大きくなると課題が出てきます。
SQL直接操作の課題
問題1: データベースごとにコードが変わる
SQLiteで書いたコードは、PostgreSQLやMySQLにそのまま使えるわけではありません。
// SQLite
sql.get`SELECT * FROM todos WHERE id = ${1}`;
// 別のライブラリ、別の書き方 (例: postgres)
sql`SELECT * FROM todos WHERE id = ${1}`;
// pg
pg.query("SELECT * FROM todos WHERE id = $1", [1]);
データベースを変更するたびに、コードを大幅に書き直す必要があります。
問題2: 型安全性がない
TypeScriptを使っていても、SQLの結果は any 型になりがちです。
const todo = sql.get`SELECT * FROM todos WHERE id = ${1}`; // any型
console.log(todo.titl); // typo!(でもエラーにならない)
問題3: 変換のためのコードが増える
複雑なクエリになるとオブジェクトに変換するコードが増えます。
const rows = sql.all`
SELECT id, title, completed, created_at
FROM todos
WHERE completed = ${false}
ORDER BY created_at DESC
`;
const todos: Todo[] = rows.map((row) => ({
id: row.id,
title: row.title,
completed: Boolean(row.completed),
createdAt: new Date(row.created_at),
}));
ORMという解決策
ORM(Object-Relational Mapping)は、これらの問題を解決するライブラリです。
- データベースの違いを吸収
- 型安全なクエリの作成
- オブジェクト指向的なデータ操作
Drizzle ORMとは
Drizzle ORM は、TypeScriptファーストで設計された軽量なORMです。
特徴
- 型安全: スキーマからTypeScriptの型が自動生成される
- 軽量: バンドルサイズが小さく、パフォーマンスが良い
- SQLライク: SQLに近い書き方ができる(学習コストが低い)
- 複数DB対応: SQLite、PostgreSQL、MySQLに対応
Drizzleでの書き方を見てみよう
先ほどのToDoアプリをDrizzle ORMで書くと、どうなるか見てみましょう。
スキーマ定義
// schema.ts
import { sqliteTable, integer, text } from "drizzle-orm/sqlite-core";
export const todos = sqliteTable("todos", {
id: integer("id").primaryKey({ autoIncrement: true }),
title: text("title").notNull(),
completed: integer("completed", { mode: "boolean" }).default(false),
});
CRUD操作
import { drizzle } from "drizzle-orm/better-sqlite3";
import { eq } from "drizzle-orm";
import Database from "better-sqlite3";
import { todos } from "./schema";
const sqlite = new Database("data.db");
const db = drizzle(sqlite);
// 一覧取得(SELECT)
const allTodos = db.select().from(todos).all();
// 1件取得
const todo = db.select().from(todos).where(eq(todos.id, 1)).get();
// 作成(INSERT)
const newTodo = db
.insert(todos)
.values({ title: "牛乳を買う" })
.returning()
.get();
// 更新(UPDATE)
db.update(todos).set({ completed: true }).where(eq(todos.id, 1)).run();
// 削除(DELETE)
db.delete(todos).where(eq(todos.id, 1)).run();
比較
| 操作 | 生のSQL | Drizzle ORM |
|---|---|---|
| 一覧取得 | SELECT * FROM todos | db.select().from(todos) |
| 条件付き取得 | WHERE id = ? | .where(eq(todos.id, 1)) |
| 作成 | INSERT INTO todos (title) VALUES (?) | db.insert(todos).values({ title: "..." }) |
| 更新 | UPDATE todos SET completed = ? | db.update(todos).set({ completed: true }) |
| 削除 | DELETE FROM todos WHERE id = ? | db.delete(todos).where(eq(todos.id, 1)) |
SQLに近い書き方なので、これまで学んだ知識がそのまま活かせます。
Drizzleを使うメリット
1. 型安全
// スキーマから型が自動生成される
type Todo = typeof todos.$inferSelect;
// { id: number; title: string; completed: boolean; }
const todo = db.select().from(todos).where(eq(todos.id, 1)).get();
// todo の型は Todo | undefined
console.log(todo?.titl); // コンパイルエラー!typoを検出
2. 自動補完が効く
VSCodeなどのエディタで、カラム名やメソッドの自動補完が効きます。開発効率が上がります。
3. データベースの切り替えが容易
// SQLiteの場合
import { drizzle } from "drizzle-orm/better-sqlite3";
// PostgreSQLに変更する場合
import { drizzle } from "drizzle-orm/node-postgres";
// スキーマ定義も少し変わるが、クエリのコードはほぼそのまま使える
いつORMを使うべきか
生のSQLが向いているケース
- 学習目的(SQLを理解したい)
- 小規模なプロジェクト
- パフォーマンスが極めて重要な処理
ORMが向いているケース
- チーム開発
- 中〜大規模なプロジェクト
- 型安全性を重視する場合
- データベースを変更する可能性がある
やってみよう!
- 前章のToDoアプリをDrizzleで実装してみましょう
Drizzleの導入方法 (参考)
実際にDrizzleを導入する場合の手順を簡単に紹介します。
# Drizzle ORMのインストール
pnpm add drizzle-orm better-sqlite3
pnpm add -D drizzle-kit @types/better-sqlite3
詳しいセットアップ方法は公式ドキュメントを参照してください。
ポイント
- ORM: オブジェクトとリレーショナルデータベースをマッピングするライブラリ
- Drizzle ORM: TypeScriptファーストで型安全、SQLに近い書き方ができるORM
- 型安全: スキーマから型が自動生成され、タイポや型エラーをコンパイル時に検出
- SQLの知識は無駄にならない: ORMを使う場合でも、SQLの理解は重要
- 選択: プロジェクトの規模や要件に応じて、生のSQLとORMを使い分ける
参考文献
開発実践
アイディアを形に
素人のように考え、玄人として実行する
金出武雄
「正しい設計」「ベストプラクティス」「効率的な方法」——そんな言葉に縛られていませんか? 生産性とかタイパとか、正直うんざり。ここでは子供のようにあなただけのローカルでパーソナルな「小さなWeb」を作って遊ぶ楽しさを取り戻しましょう。
ステップ1: デザインスプリント「自分だけのWebを考える」

アイディア発散・自由に発想する (30分〜45分程度)
思いついたアイデアを書き出してみましょう。この段階では正しさや実現可能性は気にしません。子供の頃のように自由に考えてください。
例: https://excalidraw.com/#json=zHnSzp3PV18E2Wp9LrIbB,sfpPlgnCwzWfFsbY761Pgg
以下の3つの視点が助けになるかもしれません。
視点1: 自分の困りごとから
日常で「これ、自動化できたらな」「もっと楽にならないかな」と思うことはありませんか?
例:
- 毎月の経費精算が面倒 → 経費管理アプリ
- 読んだ本を忘れる → 読書記録アプリ
- どこに何をしまったか忘れる → 収納場所メモアプリ
- 友達との旅行の割り勘計算 → 精算管理アプリ
視点2: 既存ツールの不満から
普段使っているツールやサービスに「もっとこうだったらいいのに」と思うことはありませんか?
例:
- Excelでの管理が限界 → 専用の管理画面
- メモアプリが複雑すぎる → シンプルなメモ帳
- 入力項目が多すぎる → 最小限のフォーム
- アプリを行き来するのが面倒 → 統合ツール
視点3: 遊び心から!
実用性よりも「作ったら面白そう」「誰かを笑顔にできそう」という動機を大切に。
例:
- 今日の気分で色が変わる日記
- ランダムで今日の運勢を占うアプリ
- 家族だけの写真共有アルバム
- ペットの体重記録グラフ
とにかく自由に、たくさん書き出してみましょう。
アイディアの共有
自分のアイデアを他の人に話してみましょう。順番に発表します。
話すこと:
- どんなアプリを作りたいか(1〜2分)
- なぜそれを作りたいと思ったか
聞く側の役割:
- 「それ面白いね!」「便利そう!」と感じたら絵文字でリアクション
- 「こういう機能もあったら嬉しいかも」と提案
- 批判や否定はしない(この段階では自由な発想が大事)
他の人の話を聞いて、「あ、それいいな」と思ったら、自分のアイデアを変えたり混ぜたりしてもOKです。
ステップ2: 機能を整理する
テーマが決まったら、具体的な機能を整理していきます。
事前準備 (任意)
- Webブラウザ (Chrome、Firefox、Edgeなど最新版、Excalidraw アクセス用)
- テキストエディタ (VS Code、メモ帳など)
- Gitがインストールされていること (任意・Zipダウンロードでも可)
以下を済ませておくとスムーズです。
# テンプレートを事前にクローン
git clone -b template https://github.com/kou029w/todo-template my-app
cd my-app
またはGitHubからZipでダウンロードして展開してもOKです。
Zipでダウンロードする場合:
- https://github.com/kou029w/todo-template/tree/template にアクセス
- 「Code」→「Download ZIP」
- ダウンロードしたZIPファイルを展開
- フォルダを開く
VS Codeで開く場合:
- vscode://vscode.git/clone?url=https%3A%2F%2Fgithub.com%2Fkou029w%2Ftodo-template&ref=template にアクセス
- クローン先のフォルダを選択
アイデアを絞る
いくつかアイデアが出たら、今回作るものを1つに絞りましょう。
以下の質問に答えられるか確認してみてください。
- 何ができる?: 一言で説明できる?(概要)
- なぜ作る?: 自分がワクワクする理由は?(動機)
- どこまで作る?: 最低限動くために必要な機能は何?(実現可能性)
迷ったら、一番ワクワクするものを選んでください。技術的に難しそうでも、気にしなくて大丈夫。作りながら学べます。
機能を書き出す
思いつく機能を全部書き出しましょう。この段階では取捨選択せず、自由に発想します。
優先順位をつける
書き出した機能に優先度をつけます。ここではMoSCoW分析での優先度付けの例を紹介します。
| 分類 | 意味 | 例(やることリスト) |
|---|---|---|
| Must | これがないと成り立たない | 追加、一覧、完了切替 |
| Should | できれば実装したい | 編集、削除、期限設定 |
| Could | 時間があれば | 検索、カテゴリ分け |
| Won’t | 今回は見送り | 複数ユーザー、通知 |
優先度の分析ができたら最初はMustだけに集中しましょう。動くものができてから機能を追加する方が、確実に前に進めます。
テンプレートのルートディレクトリに README.md を編集して、以下の内容を記入していきましょう。
# (プロジェクト名)
## 概要
(一言で何ができるアプリか)
## 機能
### Must (必須)
- [ ] 機能A
- [ ] 機能B
- [ ] 機能C
### Should (重要)
- [ ] 機能D
- [ ] 機能E
### Could (時間があれば)
- [ ] 機能F
- [ ] 機能G
### Won't (今回は見送る)
- 機能H
- 機能I
## 画面構成
- 画面名:概要
- 画面名:概要
- 画面名:概要
## データ構造
(主要なデータの型定義)
## APIエンドポイント
(REST APIの設計)
## 技術選定
- フレームワーク:Hono + React
- スタイリング:(選択)
- データベース:(選択)
## 備考
(その他、気になる点や挑戦したいこと)
自分の言葉で具体的に書くことが大切です。
具体例:
# やることリストアプリの機能アイデア
## Must (必須)
- タスクの追加
- タスクの一覧表示
- タスクの完了/未完了切り替え
## Should (重要)
- タスクの編集
- タスクの削除
- 期限の設定
## Could (時間があれば)
- 優先度の設定
- カテゴリ分け
- 検索・フィルター
- 並び替え
## Won't (今回は見送る)
- 複数ユーザー対応
- タスクの共有
- 通知機能
- 繰り返しタスク
- 統計・レポート
画面を洗い出す
機能が決まったら、必要な画面を整理します。
画面スケッチの例: https://excalidraw.com/#json=iuZN2WftiqLGgWk1J6p_K,w574mZehayx4VC1hku9CGQ
テキストで整理する例:
## やることリストアプリの画面構成
1. タスク一覧
- タスクの一覧表示
- 完了/未完了の切り替え
- タイトル入力欄
- 期限入力(任意)
- 新規追加ボタン
2. タスク編集
- 既存データの編集欄
- 削除ボタン
シンプルに始めましょう。画面数は少ないほど簡単。
データ構造を考える
どんなデータを扱うか整理します。これが設計の基礎になります。
// タスクのデータ構造
interface Task {
id: string; // 一意のID
title: string; // タスク名
completed: boolean; // 完了状態
dueDate?: string; // 期限
createdAt?: string; // 作成日時
updatedAt?: string; // 更新日時
}
| フィールド名 | データ型 | 必須/任意 | 説明 |
|---|---|---|---|
| id | 文字列 | 必須 | タスクを識別するための一意のID |
| title | 文字列 | 必須 | タスクの名前 |
| completed | 真偽値 (true/false) | 必須 | 完了しているかどうか (true: 完了) |
| dueDate | 文字列 | 任意 | タスクの期限 (設定しなくてもOK) |
| createdAt | 文字列 | 任意 | タスクが作成された日時 |
| updatedAt | 文字列 | 任意 | タスクが最後に更新された日時 |
Note
データ型についてJavaScriptにはいくつかのデータ型があります。主なものは以下の通りです。
- 文字列 (string):
"こんにちは"のようなテキストデータ- 数値 (number):
42や3.14のような数字- 真偽値 (boolean):
true(真)またはfalse(偽)の2つの値- オブジェクト (object): 複数のデータをまとめたもの
- 配列 (array): 複数の値を順序付きで格納するもの
詳しくはデータ型とリテラルをご覧ください。
どんなフィールドが必要か、どんな構造か、どれが必須か、明確にしておくことがポイントです。
APIエンドポイントを設計する
REST APIの設計も機能の一部です。Honoで実装することを想定して設計しましょう。
GET /api/tasks # タスク一覧取得
POST /api/tasks # タスク作成
GET /api/tasks/:id # タスク詳細取得
PUT /api/tasks/:id # タスク更新
DELETE /api/tasks/:id # タスク削除
PATCH /api/tasks/:id/toggle # 完了状態の切り替え
| メソッド | エンドポイント | 機能 |
|---|---|---|
| GET | /api/tasks | すべてのタスクを取得 |
| POST | /api/tasks | 新しいタスクを作成 |
| GET | /api/tasks/:id | 特定のタスクの詳細を取得 |
| PUT | /api/tasks/:id | 特定のタスクを更新 |
| DELETE | /api/tasks/:id | 特定のタスクを削除 |
| PATCH | /api/tasks/:id/toggle | 特定のタスクの完了状態を切り替え |
:idの部分は実際のタスクのID(例: 123)に置き換えられます。
アプリアイデア例
参考として、いくつかのアプリアイデアを紹介します。
シンプルなToDoリスト
概要: シンプルなToDoリスト
Must (必須):
- タスクの追加・削除
- 完了/未完了の切り替え
- 一覧表示
メモアプリ
概要: Markdownで書けるシンプルなメモ帳
Must (必須):
- メモの作成・編集・削除
- メモ一覧表示
- 検索機能
経費管理アプリ
概要: 経費の入力と月次集計
Must (必須):
- 経費の登録(日付、金額、カテゴリ、メモ)
- 月別一覧表示
- カテゴリ別集計
Should (重要):
- CSV出力
- カテゴリの追加・編集
- レシート画像の添付
在庫管理アプリ
概要: 備品や商品の在庫を管理
Must (必須):
- 商品の登録・編集・削除
- 在庫数の増減
- 在庫一覧表示
Should (重要):
- 在庫アラート(残り少ない商品を強調)
- 入出庫履歴
- バーコード読み取り
予約管理システム
概要: 会議室や設備の予約を管理
Must (必須):
- 予約の作成・編集・削除
- カレンダー形式での表示
- 重複チェック
Should (重要):
- 繰り返し予約
- メール通知
- 承認フロー
上級:申請ワークフロー
概要: 申請 → 承認 → 完了 のフローを管理
Must (必須):
- 申請フォーム
- 承認者への通知
- ステータス管理(申請中、承認済み、却下)
Should (重要):
- 複数段階の承認
- コメント機能
- 申請履歴
開発アプローチを選ぶ
「UIライブラリを活用 (shadcn/ui、Chakra UIなど)」「自分で1から実装」どちらのアプローチも正解です。大切なのは完成させること。途中で行き詰まったら、アプローチを切り替えても構いません。 例えば「UIはライブラリを使うが、APIロジックは自分で書く」など、部分ごとに使い分けるのも良い方法です。
ポイント
- 間違えよう: 完璧を目指さず、とりあえず書いてみる、修正は後回し
- プランB歓迎: 作り始めてから変わることも多い。最初の計画に縛られすぎない
- 自分の言葉で説明してみよう: 他の人に説明してみると理解が深まる
成果発表
Node.js Test Runnerではじめる自動テスト
Node.jsに組み込まれたテストランナーを使ってテストを行う入門ガイドです。 Node.jsでどうやってテストするんだろう?という疑問に答えます。 テストを行っていくための最初の一歩になればと思います。
それでは、さっそく学んでいきましょう!
事前準備
あらかじめNode.jsの実行環境を構築してからはじめます。
StackBlitzではじめる
次のリンクにアクセスすると、StackBlitzで新しいNode.jsの実行環境を構築できます。
StackBlitzではじめる場合は、以降の準備は不要です。
ローカル環境ではじめる
ローカル環境にNode.jsの実行環境を構築する場合、まずはじめにNode.jsをインストールします。 インストール方法は「ローカル開発環境セットアップ」をご覧ください。
はじめてのテスト
テストランナーは、node --test コマンドを使用することで実行できます。
node --test
しかし、まだテストが1件も存在しません。
$ node --test
ℹ tests 0
ℹ suites 0
ℹ pass 0
ℹ fail 0
ℹ cancelled 0
ℹ skipped 0
ℹ todo 0
ℹ duration_ms 1.92388
実際にテストを作成し、実行していきましょう。
ECMAScriptモジュール
ECMAScriptモジュール (ESM) とは、JavaScriptをモジュールとして再利用できるようにするための仕組みです。
Node.jsでESMを取り扱えるようにするためには package.json ファイルに "type": "module" プロパティを加えます。
{
"type": "module"
}
このように書き加えると、プロジェクトの .js ファイルはESMとして取り扱われます。
テストファイルの作成
次のファイルを作成します。
// hello.test.js
import assert from "node:assert/strict";
import test from "node:test";
test("1と2の合計は3です", () => {
assert.equal(1 + 2, 3);
});
この作成した hello.test.js は、node --test コマンドを実行するときにテストとして実行されるようになります。
$ node --test
✔ 1と2の合計は3です (0.54321ms)
ℹ tests 1
ℹ suites 0
ℹ pass 1
ℹ fail 0
ℹ cancelled 0
ℹ skipped 0
ℹ todo 0
ℹ duration_ms 65.4321
問題なく実行できましたか?
✔ 1と2の合計は3です
画面に表示されたこの部分は「テスト “1と2の合計は3です” が実行され、そのテストは合格しました ✅」ということを意味しています。
このようにしてNode.jsで簡単にテストを行うことができます。
はじめてのテストのコードの説明
テストのコードについてより詳しく説明します。
はじめてのテストのコード:
// hello.test.js
import assert from "node:assert/strict";
import test from "node:test";
test("1と2の合計は3です", () => {
assert.equal(1 + 2, 3);
});
このコードは、「1と2の合計は3です」というテストを意味します。
式 1 + 2 が、 3 と等しいことを検証するテストです。
このコードでは下記の機能が使われています。
test() 関数
テストを宣言するための関数です。
- 第一引数には、このテストの説明を人間が読める形式で記述します
- 第二引数には、テストの本体を記述します
assert.equal() 関数
引数に与えた値を検証します。
assert.equal(<検査される値>, <期待する値>)
「検査される値」と「期待する値」の同一性を検証します。
最初の行は import 文によって node:assert/strict と node:test を指定しています。
import assert from "node:assert/strict";
import test from "node:test";
これらがNode.jsのテストランナーの実行に必要となります。
このコードは基本的な機能を確認するための極めて単純なテストですが、テスト環境自体の検証を行うことでもあります。 テスト環境の検証は、テストを行う上で最初に確認しておく重要なポイントです。
基本的な機能
Node.jsのテストランナーの機能について説明します。
テストファイルの検出
デフォルトで下記のパターンに一致するすべてのファイルをテストファイルとして検出します1。
**/*.test.?(c|m)js**/*-test.?(c|m)js**/*_test.?(c|m)js**/test-*.?(c|m)js**/test.?(c|m)js**/test/**/*.?(c|m)js**/*.test.{cts,mts,ts}**/*-test.{cts,mts,ts}**/*_test.{cts,mts,ts}**/test-*.{cts,mts,ts}**/test.{cts,mts,ts}**/test/**/*.{cts,mts,ts}
テストの自動監視
--watch オプションを指定することで、テストファイルの変更を自動で監視します。
node --test --watch
終了するにはキーボードの Ctrl + C を押します。
プロジェクトでのテストコマンドの設定
この設定を行うと、npm test コマンドでテストを実行できるようになります。
package.json の scripts プロパティの中を下記のように変更します。
{
"scripts": {
"test": "node --test"
}
}
NPMコマンドでのテストの実行:
npm test
node --test コマンドの実行と同様のテスト結果が得られます。
テストの実践 ――「うるう年」問題
ここでは「うるう年」を判定するモジュールを作成します。
「うるう年」の判定は、通常広く使われている date-fns などのNPMパッケージを使用することが多いですが、ここではテストを学ぶためにあえて自分で実装します。
設計して、テストを書き、コードを書くという一連のステップでより実践的なテストとの付き合い方を学びましょう。
ECMAScriptモジュール
ECMAScriptモジュール (ESM) とは、JavaScriptをモジュールとして再利用できるようにするための仕組みです。
Node.jsでESMを取り扱えるようにするためには package.json ファイルに "type": "module" プロパティを加えます。
{
"type": "module"
}
このように書き加えると、プロジェクトの .js ファイルはESMとして取り扱われます。
目標の決定
まず「何を作るか」明らかにしましょう。 何を作るか曖昧なまま、ただ無為にソフトウェア開発を進めるとムダを生む恐れがあります。 ムダを生まないためにできるだけ「何を作るか」を明確にしておきましょう。
「うるう年」を判定するということは、「西暦年号がうるう年ならば true を返し、そうでなければ false を返す関数」ということと決めます。
「うるう年」とは何であるかは、ここでは日本の法令を参考にして決めます。 日本の法令上の取り扱いは、明治時代に制定された「閏年ニ関スル件」によって決められています。
神武天皇即位紀元年数ノ四ヲ以テ整除シ得ヘキ年ヲ閏年トス但シ紀元年数ヨリ六百六十ヲ減シテ百ヲ以テ整除シ得ヘキモノノ中更ニ四ヲ以テ商ヲ整除シ得サル年ハ平年トス
「神武天皇即位紀元」は、通常の西暦年号でいう紀元前660年を元年とした暦を意味します。したがって「紀元年数ヨリ六百六十ヲ減シテ」とあるのは通常の西暦年号を意味します。 端的に言うと「グレゴリオ暦法に基づいています」ということを意味します。 このままだと大変読みにくいですね。 書き換えると下記のようになります。
西暦年号が4で割り切れる年はうるう年。ただし、西暦年号が100で割り切れる年のうち、100で割った商が4で割り切れない年はうるう年ではない。
これを「うるう年」とします。整理するとこうなります。
- 西暦年号が4で割り切れる年はうるう年
- たとえば、西暦2024年、2028年、2032年は4で割り切れるので、うるう年です。
- 西暦年号が4で割り切れない年はうるう年でない
- たとえば、西暦2021年、2022年、2023年は4で割り切れないので、うるう年ではありません。
- ただし、西暦年号が100で割り切れる年はうるう年でない
- たとえば、西暦2100年、2200年、2300年は100で割り切れるので、うるう年ではありません。
- ただし、西暦年号が400で割り切れる年はうるう年
- たとえば、西暦2000年、2400年、2800年は400で割り切れるので、うるう年です。
これで「何を作るか」ということが明らかになりました。 それでは、順番にテストとコードを書いていきましょう。
「西暦年号が4で割り切れる年はうるう年」
ファイル isLeapYear.test.js を作成します。
「何を作るか」ということを忘れないようにコメントに転載します。
// isLeapYear.test.js
/** TODO:
西暦年号が4で割り切れる年はうるう年
たとえば、西暦2024年、2028年、2032年は4で割り切れるので、うるう年です。
西暦年号が4で割り切れない年はうるう年でない
たとえば、西暦2021年、2022年、2023年は4で割り切れないので、うるう年ではありません。
ただし、西暦年号が100で割り切れる年はうるう年でない
たとえば、西暦2100年、2200年、2300年は100で割り切れるので、うるう年ではありません。
ただし、西暦年号が400で割り切れる年はうるう年
たとえば、西暦2000年、2400年、2800年は400で割り切れるので、うるう年です。
*/
うるう年であることを判定するので isLeapYear という名前に決めました。
この名前のモジュールと関数を作成することに決めます。
テストを書いていきましょう。
// isLeapYear.test.js
import assert from "node:assert/strict";
import test from "node:test";
test("西暦年号が4で割り切れる年はうるう年", () => {
assert.ok(isLeapYear(2024));
});
これをテストし、失敗することを確認します。 この失敗は、テスト環境自体の検証を行うことでもあります。
assert.ok() 関数
引数に与えた値を検証します。
assert.ok(<検査される値>)
「検査される値」が真であることを検証します。
NPMコマンドでのテストの実行:
npm test
テストの自動監視:
node --test --watch
テスト結果:
✖ 西暦年号が4で割り切れる年はうるう年
失敗しますね。 この失敗によって、次の2点を実証できました。
- 目標の「西暦年号が4で割り切れる年はうるう年」というテストが実行されること
- 未実装のコードが意図せず合格しない ❌ ということ
テスト環境の検証は、テストを行う上での重要なポイントです。
それでは、関数を実装していきましょう。 最初からすべての実装を書こうとせず、小さい変更のみで済ませるのがポイントです。
// isLeapYear.js
function isLeapYear(year) {
return year % 4 === 0;
}
export default isLeapYear;
ファイルを作成したら、テスト側で import 文によって実装した関数を読み込みます。
// isLeapYear.test.js
import assert from "node:assert/strict";
import test from "node:test";
import isLeapYear from "./isLeapYear.js";
test("西暦年号が4で割り切れる年はうるう年", () => {
assert.ok(isLeapYear(2024));
});
テストを実行します。
テスト結果:
✔ 西暦年号が4で割り切れる年はうるう年
これでテストは合格 ✅ しました。 念の為、西暦2024年のケースだけでなくほかのケースもテストしてみましょう。
「西暦年号が4で割り切れる年はうるう年」という目標を達成したと判断したら、コメントからは消しておきます。
// isLeapYear.test.js
import assert from "node:assert/strict";
import test from "node:test";
import isLeapYear from "./isLeapYear.js";
test("西暦年号が4で割り切れる年はうるう年", () => {
assert.ok(isLeapYear(2024));
assert.ok(isLeapYear(2028));
assert.ok(isLeapYear(2032));
});
/** TODO:
西暦年号が4で割り切れない年はうるう年でない
たとえば、西暦2021年、2022年、2023年は4で割り切れないので、うるう年ではありません。
ただし、西暦年号が100で割り切れる年はうるう年でない
たとえば、西暦2100年、2200年、2300年は100で割り切れるので、うるう年ではありません。
ただし、西暦年号が400で割り切れる年はうるう年
たとえば、西暦2000年、2400年、2800年は400で割り切れるので、うるう年です。
*/
次の目標「西暦年号が4で割り切れない年はうるう年でない」に進めていきます。
テストを書き、実行します。
必要に応じて実装を修正します。
これらのテストも問題なく合格するようになれば、「西暦年号が4で割り切れない年はうるう年でない」という目標も達成したと判断して、コメントから消しておきます。
// isLeapYear.test.js
import assert from "node:assert/strict";
import test from "node:test";
import isLeapYear from "./isLeapYear.js";
test("西暦年号が4で割り切れる年はうるう年", () => {
assert.ok(isLeapYear(2024));
assert.ok(isLeapYear(2028));
assert.ok(isLeapYear(2032));
});
test("西暦年号が4で割り切れない年はうるう年でない", () => {
assert.equal(isLeapYear(2021), false);
assert.equal(isLeapYear(2022), false);
assert.equal(isLeapYear(2023), false);
});
/** TODO:
ただし、西暦年号が100で割り切れる年はうるう年でない
たとえば、西暦2100年、2200年、2300年は100で割り切れるので、うるう年ではありません。
ただし、西暦年号が400で割り切れる年はうるう年
たとえば、西暦2000年、2400年、2800年は400で割り切れるので、うるう年です。
*/
続きの課題
残りの目標に関しても同様に進めていきましょう。
- ただし、西暦年号が100で割り切れる年はうるう年でない
- たとえば、西暦2100年、2200年、2300年は100で割り切れるので、うるう年ではありません。
- ただし、西暦年号が400で割り切れる年はうるう年
- たとえば、西暦2000年、2400年、2800年は400で割り切れるので、うるう年です。
テストの作法
テストを書くときの代表的な作法を紹介します。
Arrange・Act・Assert (AAA) パターン
テストを書くときの作法の1つです。 準備 (Arrange)・実行 (Act)・検証 (Assert) というプロセスで分けて書きます。 準備・実行・検証をそれぞれ分けて書いておくことで比較的読みやすいテストを書くことができます。
例:
import assert from "node:assert/strict";
import test from "node:test";
test("正しくJSONをパースできる", () => {
// 準備
const json = `{ "name": "Claude Monet", "birth": "1840" }`;
// 実行
const parsed = JSON.parse(json);
// 検証
assert.deepEqual(parsed, { name: "Claude Monet", birth: "1840" });
});
参考文献・動画
Node.js
テスト駆動開発
和田卓人 (2020)「TDD Boot Camp 2020 Online #1 基調講演/ライブコーディング」
安井力 (2021)「『テスト自動化とテスト駆動開発』講演動画」
Web
WebとWebブラウザーについてまとめます。といっても、仕組みがわかると面白いかも、くらいの気持ちで気楽にいきましょう。
Webとは
“This is for everyone”
Webは情報共有とコミュニケーションのためのプラットフォームです。 Web上ではソーシャルメディア、ビデオストリーミング、オンラインショッピングなど様々な活動が行われます。(便利ですよね。)
World Wide Web
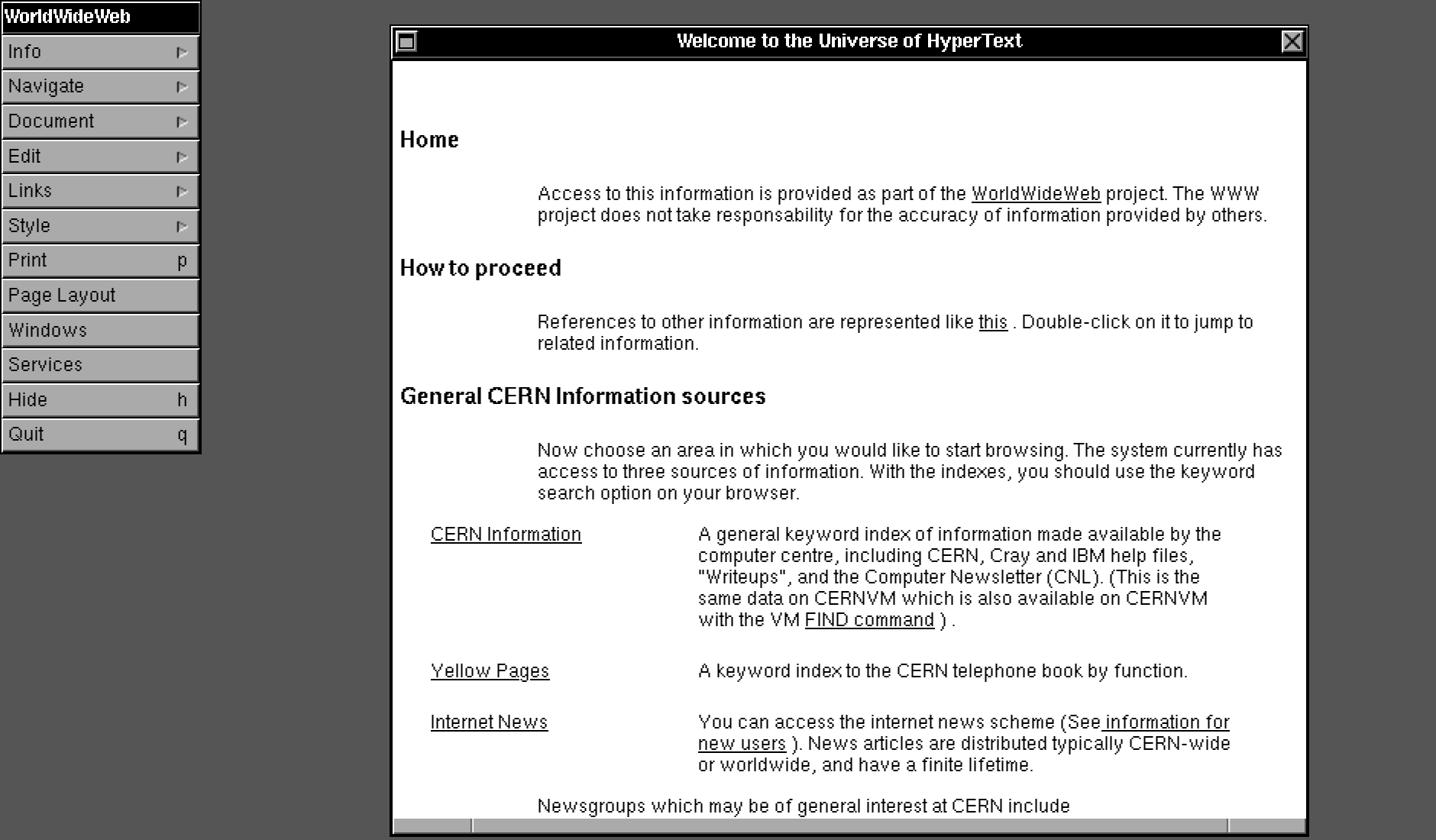 ― 画像: https://worldwideweb.cern.ch/browser/ より
― 画像: https://worldwideweb.cern.ch/browser/ より
これは世界初のWebブラウザーWorldWideWebの画像です。
普段使っているブラウザーからでも世界最初のWebサイトにアクセスすることができます。
https://info.cern.ch/hypertext/WWW/TheProject.html
World Wide Web (Web) は、1989年に分散型ハイパーテキストシステム (distributed hypertext system)としてティム・バーナーズ・リーによって提案されたアイデアが元になっています。世界中に張り巡らされた蜘蛛の巣を連想して名付けられました。
Note
中央集権型 (centralized) と 非中央集権型 (decentralized) と 分散型 (distributed)
― 画像: ポール・バラン (1964) On Distributed Communications Networks よりWebは分散型のシステムです。中央集権型のシステムではありません。Web上で何か活動するとき、中央の機関からの許諾は一切必要ありません。いつでも、どこでも、誰でも自由に使うことができます。
Webブラウザー
Webブラウザーは、Webページの取得・描画を行うソフトウェアです。
代表的なWebブラウザーとしては、Google Chrome、Safari、Mozilla Firefox、Microsoft Edgeなどが挙げられます。
Webの標準化
主に3つの標準化団体が関わっています。
- IETF (Internet Engineering Task Force)
- W3C (The World Wide Web Consortium)
- WHATWG (Web Hypertext Application Technology Working Group)
IETFはインターネットに関する全般的な技術、約束事、コミュニティで共有すべき事柄の管理を担っています。それらは RFC (Request for Comments) と呼ばれる形式で記録されています。
W3CとWHATWGはWebに関する仕様の管理を担っています。具体的にはW3CはCSSなど、WHATWGはHTML関連の仕様などを発行しています。 WHATWGの発行している仕様はIETFやW3Cの仕様とは異なり内容が確定することはありません。HTML Living Standardはその時点が常に最新版の標準仕様となっており、継続的に更新され続けています。
いずれの仕様もWeb上で公開されており、無償で閲覧可能、誰でも参加可能、自由に実装可能です。
ポイント
- Web … 分散型ハイパーテキストシステム
- Webブラウザー … Webページの取得・描画を行うソフトウェア
- Webの標準化 … 無償で閲覧可能、誰でも参加可能、自由に実装可能
Webの仕組み
Webの誕生から現在に至るまでWeb上で出来ることやその役割は大きく変わりました。 しかし、それを支える基本的な仕組みと構成要素は実はあまり変わっていません。
Webはこれらの要素に支えられています。
Note
変わり続けるルール多くのルールを覚えることは決して重要ではありません。 なぜなら現実の問題は複雑でそれに合わせてルールも変わり続けていくものだからです。 大切なのは解決したい問題への理解を深めていくことなのです。 何を解決するためのルールなのか一緒に考えていきましょう。(この後も退屈な説明が続きますがどうかお付き合いください。)
例えばこれらの仕様はいずれも常に最新版の標準仕様となっており継続的に更新され続けています。
Webページ
― 画像: JavaScript とは - Web開発を学ぶ | MDN より

Webページはこれらの要素に支えられています。
- HTML … Webページの構造を記述するための言語
- CSS … Webページの見た目を記述するための言語
- JavaScript … プログラミング言語
ポイント
- Web … URL/HTTP/コンテンツ
- Webページ … HTML/CSS/JavaScript
参考文献
- 太田 良典、中村 直樹「HTML解体新書」
- HTMLの基本概念の説明を参考にしています
- 渋川よしき「Real World HTTP 第2版」
- HTTPの技術的な説明の参考にしています
- 渋川よしき「Real World HTTP ミニ版」は無料で読めるのでお手軽です
- Dev.Opera — HTTP — an Application-Level Protocol
- HTTPの概要を説明するために参考にしています
- 米内貴志「Webブラウザセキュリティ」
- Webブラウザーのセキリティ機構の説明を参考にしています
URL - Uniform Resource Locator
URLはインターネット上のリソースの位置を特定するための文字列です。 住所と似ています。
URLの仕様からいくつか具体例を挙げます。
例:
https://example.com/
https://localhost:8000/search?q=text#hello
urn:isbn:9780307476463
file:///ada/Analytical%20Engine/README.md
これらはいずれもURLです。
URLを使ってリンクさせることができます。
ユニフォーム (uniform) と名前にあるのは、統一的なルールがあります、ということです。 Web上で「〇〇にアクセスしたい」と思ったときみんなで使える同じ表現があったほうが便利というわけですね。
ではURLにはどういうルールがあるのか詳しく見ていきましょう。
スキーム (Scheme)
URLの種別や性質を意味します。
https://example.com/
この例でいうと、先頭から : までの文字列 https が「スキーム」です。住所の例で言うと、郵便を表す記号「〒」の役割と似ています。URLはスキームごとにその書式が異なります。
Note
インターネット上で利用可能なURLスキームの一覧Uniform Resource Identifier (URI) Schemes
インターネット上で利用可能なURLスキームの一覧はIANA (Internet Assigned Numbers Authority)によって管理されています。
https スキームは Hypertext Transfer Protocol Secure (RFC 9110) を意味します。その後に文字列 :// が続きます。
https スキームのURLの場合は、その後に「ホスト (Host)」「ポート (Port)」「パス (Path)」「クエリー (Query)」「フラグメント (Fragment)」と続きます。
Note
httpとhttps前者は “Hypertext Transfer Protocol”、後者は “Hypertext Transfer Protocol Secure” を意味するスキームです。 “Secure” と付いているのは、必ず TLS (Transport Layer Security) の上でやり取りを行います、という意味です。 最近
http://...から始まるURLはあまり見かけないかと思います。 これはHTTPのセキュリティとプライバシーの問題が広く知られ、代わりにHTTP over TLSが使われるようになったためです。 TLSを使うことによってクライアント・サーバー間の通信が暗号化され、もし仮に傍受されても第三者による改ざんや解析は以前より難しくなりました。
ホスト (Host)
郵便番号と住所みたいなものです。「ポスト」じゃないですよ。
https://example.com/
この例でいうと、example.com の部分が「ホスト」です。
ホストはドメイン名またはIPアドレスです。
ドメイン名を見かけることが多いかと思います。
Note
ドメイン名インターネットに接続しているすべてのコンピューターにはIPアドレスが割り当てられています。 ドメイン名はそうしたIPアドレスに人間が読めるように別の名前を付けたものです。 ドメイン名は Domain Name System (DNS) によって支えられています。 Internet Corporation for Assigned Names and Numbers (ICANN) を中心とした複数のドメイン管理事業者によって管理されており、世界中で使うことができるようになっています。
例: Google Public DNS に
example.comを問い合わせる例"Answer": [ { "name": "example.com.", "type": 28 /* AAAA */, "TTL": 13460, "data": "2606:2800:220:1:248:1893:25c8:1946" } ]ドメイン名
example.comはIPアドレス[2606:2800:220:1:248:1893:25c8:1946]の別名ですよ、という意味です。
ポート (Port)
「ポート」が書いてあるURLは普段あまり見かけないかもしれませんね。 でもインターネット上で通信するとき必ず登場します。存在するからには一応紹介しておきます。
ホストの後にはポートを書くことができます。
ホストと : 文字の後にポート番号を書きます。
省略すると https スキームの場合は 443 が割り当てられています。
例えばこれらのURLは同じ意味です。
https://example.com/
https://example.com:443/
この場合どちらも 443 ポートを意味します。
オリジン (Origin)
スキーム・ホスト・ポートをまとめて扱うことがあります。 具体的にはセキュリティ上の理由から送信元の同一性を判定するケースです。 このとき使われるのが「オリジン」です。
https://localhost:8000/search?q=text#hello
例えばこの例では (https, localhost, 8000) の3つの組がオリジンです。
オリジンは https://localhost:8000 のように表現します。
JavaScriptでは location.origin でオリジンを取得できます。
Note
Webブラウザーのセキリティ機構Webブラウザーには同一オリジンポリシーと呼ばれる保護機構があり、オリジン間のアクセスは原則禁止されています。 異なるオリジン間でのアクセスを許可するには、オリジン間リソース共有 (Cross-Origin Resource Sharing, CORS) の仕組みを使います。 CORSはリソースを提供する人が同一オリジンポリシーを緩和しオリジン間のアクセスを許可するための仕組みです。
パス (Path)
/ 文字で区切られた文字列が続きます。これが「パス」です。ホストの中のリソースの場所を意味します。
/ は日本語でいう「の」みたいなものです。
階層構造を表現します。
https://example.com/
この場合パスは / です。
https://example.com/foo/bar
この場合パスは /for/bar です。
ちなみにJavaScriptでは location.pathname でパスを取得できます。
クエリー (Query)
? 文字で区切られた文字列が続くことがあります。場合によっては = や & が含まれます。これは「クエリー」です。
https://localhost:8000/search?q=text#hello
例えばこの例では q=text がクエリーです。
= は日本語でいう「は」みたいなものです。
Google検索の例: https://www.google.com/search?q=answer+to+life+the+universe+and+everything
この場合クエリーは q=answer+to+life+the+universe+and+everything です。
q は “answer to life the universe and everything” ですよ、という意味です。
JavaScriptでは location.search でクエリーを取得できます。
フラグメント (Fragment)
# 文字で区切られた文字列が続くことがあります。これは「フラグメント」です。
URLの末尾にフラグメントがあるとき、そのリソースの中の一部分を意味します。
HTMLの場合はフラグメントと id 属性の名前が一致するときその箇所を指定することができます。
https://localhost:8000/search?q=text#hello
例えばこの例では hello がフラグメントです。
JavaScriptでは location.hash でフラグメントを取得できます。
ポイント
- URLはインターネット上のリソースの位置を特定するための識別子
https://から始まるURLはhttpsスキームのURLhttpsスキームのURLの構成要素 … ホスト、ポート、パス、クエリー、フラグメント
HTTP - Hypertext Transfer Protocol
HTTPはWebの転送用のプロトコルです。
URLがあればそのリソースがWeb上の「どこに」あるか知ることができます。 ではそのリソースには「どのように」アクセスしたらよいのでしょうか。
https スキームや http スキームのURLに対応するリソースにアクセスする手順、それがHTTPです。
プロトコル
― この画像は © 2012 Karl Dubost クリエイティブ・コモンズ CC BY 3.0 ライセンスのもとに利用を許諾されています。
二者間でのコミュニケーションが成立するためには3つの要素が含まれています。
- シンタックス (コードの文法)
- セマンティクス (コードの意味)
- タイミング (速度合わせと順序付け)
「挨拶」を例に考えてみましょう。 腰を曲げるジェスチャー、これはお辞儀のためのシンタックスです。日本ではそういう慣習ですね。お辞儀をすることで「どうも、こんにちは」という意味づけが行われます。これはセマンティクスです。二者間で特定のタイミングでこれらが発生したとき、一連の出来事として成立します。どちらもお辞儀をし、お互いに理解することによって「挨拶」として成立した、となるわけです。
Web上でのやり取りも同じです。 HTTPはサーバー・クライアントの二者関係で行われます。 クライアントはサーバーに対して要求を送り、クライアントからの要求を受け取るとサーバーは応答を返します。
HTTPの仕様にある具体例を挙げます。 次のようなコードの送受信を行います。
クライアントリクエスト (クライアント側からサーバー側への送信):
GET /hello.txt HTTP/1.1
User-Agent: curl/7.64.1
Host: www.example.com
Accept-Language: en, mi
サーバーレスポンス (サーバー側からクライアント側への送信):
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 51
Vary: Accept-Encoding
Content-Type: text/plain
Hello World! My content includes a trailing CRLF.
リクエストの構成 (送る側):
- メソッド (Method)
- URL (Request Target)
- ヘッダー (Header Fields)
- ボディ (Body)
レスポンスの構成 (返す側):
- ステータスライン (例:
HTTP/1.1 200 OK— ステータスコードを含む) - ヘッダー (Header Fields)
- ボディ (Body / Content)
詳しく見ていきましょう。
メソッドとURL(Request Line)
クライアントリクエストの1行目の GET /hello.txt HTTP/1.1 の部分は、リクエストライン (Request Line) と呼ばれます。どこに(URL)、どのような方法でアクセスしたいかをサーバーに伝えるためのものです。
クライアントリクエスト:
GET /hello.txt HTTP/1.1
この例はURL http://www.example.com/hello.txt にアクセスするためのクライアントリクエストです。GET メソッドでパス /hello.txt へのアクセスを要求しています。
GET メソッドは取得するために使われる最も基本的なメソッドで、リンクをクリックしたときやWebブラウザーのアドレスバーにURLを入力したとき送信されます。Webでのやり取りはこの「メソッドとURL」を含むリクエストラインをWebサーバーに伝えるところから始まります。
Note
HTTP/1.1 と HTTP/2HTTP/1.1は1995年に公開され、2022年に最新版に改定されました。 HTTP/1.1は現在も使われ続けています。 一方、HTTP/2は2022年に公開されました。 HTTP/2はHTTP/1.1とは異なり複数のメッセージを同時に扱える、コンピューターにとってより効率的な形式のシンタックスが特徴の新しい仕様です。 HTTP/2ではリクエストラインの代わりに一貫してフィールドを使うなどHTTP/1.1と文法が大きく異なりますがその意味は全く変わりません。
GET /resource HTTP/1.1 HEADERS Host: example.org ==> + END_STREAM Accept: image/jpeg + END_HEADERS :method = GET :scheme = https :authority = example.org :path = /resource host = example.org accept = image/jpeg
ヘッダー(Headers / Fields)
: 文字で区切られた行が続きます。これは「ヘッダー(ヘッダーフィールド、Fields)」です。リクエストとレスポンスに関連する付帯情報を意味します。
Host: www.example.com
例えばこの場合、送信先 Host (ホスト) は www.example.com ですよ、という意味です。以降、本書では用語を統一して「ヘッダー」と呼びます(HTTP/1.1仕様では header field とも表記されます)。
ステータスラインとステータスコード
― 画像: HTTP Cats より
「ステータスコード (Status Codes)」はそのリソースの存在やアクセス可否などをサーバーが伝えるためのものです。 サーバーはレスポンスを返すとき、最初にステータスコードを返します。
サーバーレスポンスの先頭行(ステータスライン):
HTTP/1.1 200 OK
この例ではステータスコード 200 を返しています。
ステータスコードは100〜599までの3桁の整数で表されます。
レスポンスはステータスコードの100の位で大きく分類されます。
- 1xx (情報): リクエストを受信しました。プロセスを続行します。
- 2xx (成功): リクエストは正常に受信、理解され、受け入れられました。
- 3xx (リダイレクト): リクエストを完了するにはさらにアクションを実行する必要があります。
- 4xx (クライアントエラー): リクエストに不正な構文が含まれているか、リクエストを実行できません。
- 5xx (サーバーエラー): サーバーは有効なリクエストを実行できません。
Note
418 I’m a teapot私はティーポットなのでコーヒーを入れることを拒否しました、という意味のステータスコードです。 1998年のエイプリルフールに公開されました。 現在でもステータスコード
418は IANA HTTP Status Code Registry によって管理されています。
ボディ(Body / Content)
ヘッダーの後に空行があり、その後に「ボディ (本文)」が続きます。 ボディはHTML、画像、動画、JSONなど、あらゆるデータになり得ます。
ポイント
- HTTPはWebの転送用のプロトコル
- HTTPはクライアントからのリクエストとサーバーからのレスポンスによってやり取りを行う
- 用語の対応: ヘッダー ≒ フィールド(header fields)
- HTTPの構成要素
- リクエスト: メソッド/URL/ヘッダー/ボディ
- レスポンス: ステータスライン/ヘッダー/ボディ
HTML
HTMLはWebページの構造を記述するための言語です。
「どこに」「どのように」アクセスするかというと、Webでは「URLに」「HTTPで」アクセスするわけですね。 では一体「何を」Webブラウザーは見せているのでしょうか。 それは「HTML」です。(この入門ガイドもそうですよ。)
もともとHTMLは主に科学文書の意味や構造を正確に記述するための言語として設計されました。 現在では、あらゆる文書やアプリの記述に応用されています。
文法と意味
HTMLはマークアップ言語 (Markup Language)と呼ばれるカテゴリーの言語です。 HTMLの仕様から具体的なコードの例を挙げます。
例:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Sample page</title>
</head>
<body>
<h1>Sample page</h1>
<p>This is a <a href="demo.html">simple</a> sample.</p>
<!-- this is a comment -->
</body>
</html>
「タグ (Tag)」と呼ばれる印でコンテンツのかたまりを囲みます。 このかたまりは「要素 (Element)」と呼ばれます。
― 画像: 「HTML の基本」より

要素の中に別の要素を含めることもあります。
<p>This is a <a href="demo.html">simple</a> sample.</p>
この例では<p>: 段落要素の中に<a>: アンカー要素が含まれています。 リンクが含まれている文、その文を含む段落、という構造なわけです。
やってみよう!
基本的なルールが分かってきたところで、さっそく遊んでみましょう!
<p>ここは段落なのですよ。</p> <p>HTMLを使えばインターネット上のあらゆるコンテンツに<a href="https://kou029w.github.io/intro-to-web-dev/web/html.html">リンク</a>できるのです。</p>
MDNで調べてみよう
MDN (MDN Web Docs) は、HTML、CSS、JavaScriptなどWeb技術に関するあらゆる文書を網羅的にまとめているサイトです。オープンソースで提供されており、誰でも自由に貢献することができます。MDNにアクセスすればWebブラウザーに組み込まれているあらゆるAPIの仕様やその機能を調べることができます。
Googleなどの検索エンジンで「MDN [調べたいキーワード]」または「site:developer.mozilla.org [調べたいキーワード]」を検索してみましょう。
ポイント
- MDN … Webブラウザーに組み込まれているAPIの仕様や機能を調べることができる
API - Application Programming Interface
システムには情報やエネルギーなど外部とのやりとりするための境界面があり、それを「インターフェース」と呼びます。
API (Application Programming Interface) とは、アプリケーションソフトウェアのインターフェースを指す概念です。
家電製品を例に考えてみましょう。 家電製品はそのシステムの外部から供給された電力を消費して仕事をします。 このとき外部との境界には外部から電力を供給するためのインターフェースが存在します。 それはコンセントですね。 コンセントには定格電圧や形状など規格があります。 インターフェースとはそういったルールのことです。 家電製品にはコンセントがあるので専門的な技能が無くても手軽に電気的エネルギーにアクセスできるのです。 これは物理的な例ですが、外部との境界にインターフェースがあるのはWebも同じです。 JavaScriptから簡単に外部と情報をやりとりしたり、外部のサービスの機能を使うためにAPIがあります。
参考文献
- Web API の紹介 - Web開発を学ぶ | MDN
- APIの基本的な概念の説明を参考にしています
開発者ツールに慣れる
Webブラウザーには開発者ツールが内蔵されています。 これを使うことでWebブラウザーが表示しているHTMLの状態を調べたり、どのリソース (URL) に、どのようにアクセスしているのか (HTTPメッセージの内容) 知ることができます。
ここではGoogle ChromeやMicrosoft EdgeなどChromium系ブラウザーの開発者ツールの基本的な使い方を説明します。
開発者ツールの起動方法
開発者ツールを起動するにはいくつかの方法があります。
- 右クリック > [検証] を選択
- [その他のツール] > [デベロッパー ツール] を選択
- Windows/Linuxの場合:
Ctrl+Shift+I - macOSの場合:
⌘ (Command)+⌥ (Option)+I
どの方法でもOKです。
Note
開発者ツールの翻訳
はじめて開発者ツールを起動したとき、メニューがすべて英語で表示されることがあります。 開発者ツールのメニューを翻訳するには開発者ツール上部の [Always match Chrome’s language] を選択しましょう。
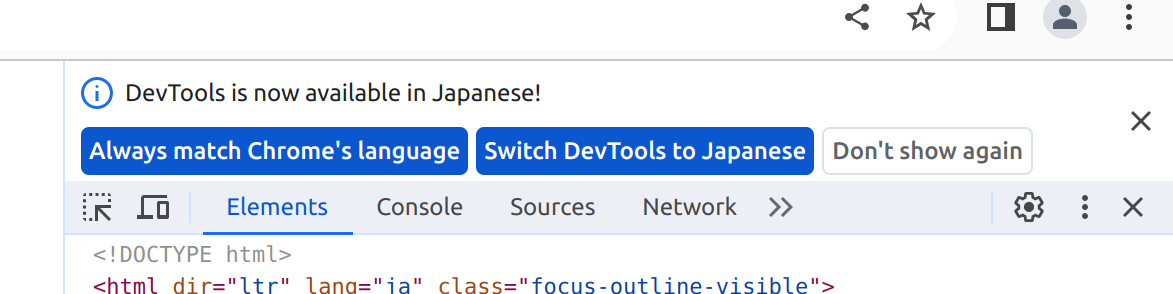
実際に手元のWebブラウザーから開発者ツールを起動してみましょう。
要素 (Elements)
画面上に表示されているHTML要素とその状態を知ること、一時的に編集することができます。
コンソール (Console)
JavaScriptの実行と、エラーメッセージなど実行しているコードを解析するための情報を知ることができます。
ソース (Sources)
実行しているコードの表示と一時停止 (ブレークポイントの設定)、そのコードを解析することができます。
ネットワーク (Network)
WebブラウザーがアクセスしているURLとそのHTTPメッセージの内容知ることができます。
- 上側のペイン: タイムライン
- 左側のペイン: リクエストの一覧
- 右側のペイン: (リクエストの一覧から選択) リクエストヘッダー・プレビュー・レスポンスなどHTTPメッセージの詳細
ヘッダー
URLとリクエストのメソッド、レスポンスのステータスコードなどHTTPメッセージの基本的な情報を知ることができます。
プレビュー
(表示可能であれば) そのコンテンツを表示します。
レスポンス
そのコンテンツの生のデータを表示します。
ポイント
- 開発者ツール … Webブラウザーが表示しているHTMLの状態を調べたり、どのリソースに、どのようにアクセスしているのか知ることができる
やってみよう!
- 実際に手元のWebブラウザーで開発者ツールを起動していくつかのWebページにアクセスしてみよう
JavaScript
JavaScript Primer > 基本文法 > JavaScriptとは
JavaScriptを学びはじめる前に、まずJavaScriptとはどのようなプログラミング言語なのかを紹介します。
JavaScriptは主にWebブラウザーの中で動くプログラミング言語です。 ウェブサイトで操作をしたら表示が書き換わったり、ウェブサイトのサーバーと通信してデータを取得したりと現在のウェブサイトには欠かせないプログラミング言語です。 このようなJavaScriptを活用してアプリケーションのように操作できるウェブサイトをWebアプリとも言います。
JavaScriptはWebブラウザーだけではなく、Node.jsというサーバー側のアプリケーションを作る仕組みでも利用されています。 また、デスクトップアプリやスマートフォンアプリ、IoT(Internet of Things)デバイスでもJavaScriptを使って動かせるものがあります。 このように、JavaScriptはかなり幅広い環境で動いているプログラミング言語で、さまざまな種類のアプリケーションを作成できます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > JavaScriptとは を参照しましょう。
歴史
JavaScriptは、1995年にブレンダン・アイクによって、当初Netscape Navigatorのためのスクリプト言語として開発されました。当時のWebは非常にシンプルで静的なものであり、動的なユーザーインタラクションはほとんどありませんでした。
そんな中、当時Netscape Communicationsで働いていたブレンダン・アイクは上司から新しいスクリプト言語を開発するよう依頼され、C、Java、Self、Schemeなどの既存のプログラミング言語の概念を取り入れつつ、わずか10日間で初期バージョンのJavaScriptを開発しました。
動的なユーザーインタラクションやサーバーへの非同期通信(Ajax)など現在では当たり前となっている多くの機能が初めてWebブラウザー上で可能となり、またその後のWebブラウザー以外の技術の発展にも大きな影響を与えました。
ポイント
- ECMAScript仕様による標準化
- 仕様は毎年更新されている
値の評価と表示
JavaScript Primer > 基本文法 > 値の評価と表示
値の評価とは、入力した値を評価してその結果を返すことを示しています。 たとえば、次のような値の評価があります。
1 + 1という式を評価したら2という結果を返すbookTitleという変数を評価したら、変数に代入されている値を返すconst x = 1;という文を評価することで変数を定義するが、この文には返り値はない
この値の評価方法を確認するために、Webブラウザー(以下ブラウザ)を使ってJavaScriptを実行する方法を見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 値の評価と表示 を参照しましょう。
ポイント
- Webブラウザーの開発者ツールのコンソール上でJavaScriptコードを評価する方法
やってみよう!
- 実際に手元のWebブラウザーでJavaScriptを実行してみよう
変数と宣言
JavaScript Primer > 基本文法 > 変数と宣言
プログラミング言語には、文字列や数値などのデータに名前をつけることで、繰り返し利用できるようにする変数という機能があります。
JavaScriptには「これは変数です」という宣言をするキーワードとして、
const、let、varの3つがあります。
varはもっとも古くからある変数宣言のキーワードですが、意図しない動作を作りやすい問題が知られています。
そのためECMAScript 2015で、varの問題を改善するためにconstとletという新しいキーワードが導入されました。
この章ではconst、let、varの順に、それぞれの方法で宣言した変数の違いについて見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 変数と宣言 を参照しましょう。
ポイント
constは、再代入できない変数を宣言できるletは、再代入ができる変数を宣言できる
やってみよう!
// 真空の光速度 (m/s)
const c = 299792458;
// 時間 (s)
let t = 0;
// 光の速度は変わらない
// c = 42;
// 時間は変わる
t = 0.001;
document.body.textContent = `${t} 秒間に光の進む距離: ${c * t} m`;
データ型とリテラル
JavaScript Primer > 基本文法 > データ型とリテラル
JavaScriptは動的型付け言語に分類される言語であるため、静的型付け言語のような変数の型はありません。 しかし、文字列、数値、真偽値といった値の型は存在します。 これらの値の型のことをデータ型と呼びます。
データ型を大きく分けると、プリミティブ型とオブジェクトの2つに分類されます。
プリミティブ型(基本型)は、真偽値や数値などの基本的な値の型のことです。 プリミティブ型の値は、一度作成したらその値自体を変更できないというイミュータブル(immutable)の特性を持ちます。 JavaScriptでは、文字列も一度作成したら変更できないイミュータブルの特性を持ち、プリミティブ型の一種として扱われます。
一方、プリミティブ型ではないものをオブジェクト(複合型)と呼び、 オブジェクトは複数のプリミティブ型の値またはオブジェクトからなる集合です。 オブジェクトは、一度作成した後もその値自体を変更できるためミュータブル(mutable)の特性を持ちます。 オブジェクトは、値そのものではなく値への参照を経由して操作されるため、参照型のデータとも言います。
データ型を細かく見ていくと、7つのプリミティブ型とオブジェクトからなります。
- プリミティブ型(基本型)
- 真偽値(Boolean):
trueまたはfalseのデータ型 - 数値(Number):
42や3.14159などの数値のデータ型 - 巨大な整数(BigInt): ES2020から追加された
9007199254740992nなどの任意精度の整数のデータ型 - 文字列(String):
"JavaScript"などの文字列のデータ型 - undefined: 値が未定義であることを意味するデータ型
- null: 値が存在しないことを意味するデータ型
- シンボル(Symbol): ES2015から追加された一意で不変な値のデータ型
- 真偽値(Boolean):
- オブジェクト(複合型)
- プリミティブ型以外のデータ
- オブジェクト、配列、関数、クラス、正規表現、Dateなど
プリミティブ型でないものは、オブジェクトであると覚えていれば問題ありません。
typeof演算子を使うことで、次のようにデータ型を調べることができます。
console.log(typeof true); // => "boolean"
console.log(typeof 42); // => "number"
console.log(typeof 9007199254740992n); // => "bigint"
console.log(typeof "JavaScript"); // => "string"
console.log(typeof Symbol("シンボル")); // => "symbol"
console.log(typeof undefined); // => "undefined"
console.log(typeof null); // => "object"
console.log(typeof ["配列"]); // => "object"
console.log(typeof { key: "value" }); // => "object"
console.log(typeof function () {}); // => "function"
プリミティブ型の値は、それぞれtypeof演算子の評価結果として、その値のデータ型を返します。
一方で、オブジェクトに分類される値は"object"となります。
配列([])とオブジェクト({})は、どちらも"object"という判定結果になります。
そのため、typeof演算子ではオブジェクトの詳細な種類を正しく判定することはできません。
ただし、関数はオブジェクトの中でも特別扱いされているため、typeof演算子の評価結果は"function"となります。
また、typeof nullが"object"となるのは、歴史的経緯のある仕様のバグ[^1]です。
このことからもわかるようにtypeof演算子は、プリミティブ型またはオブジェクトかを判別するものです。
typeof演算子では、オブジェクトの詳細な種類を判定できないことは、覚えておくとよいでしょう。
各オブジェクトの判定方法については、それぞれのオブジェクトの章で見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > データ型とリテラル を参照しましょう。
ポイント
- プリミティブ型とオブジェクトがある
- リテラルはデータ型の値を直接記述できる構文として定義されたもの
- プリミティブ型リテラル
- 真偽値 …
truefalse - 数値 …
423.14159など - 文字列 …
"JavaScript"など - BigInt …
9007199254740992nなど - null …
null
- 真偽値 …

コメント
JavaScript Primer > 基本文法 > コメント
コメントはプログラムとして評価されないため、ソースコードの説明を書くために利用されています。 この書籍でも、JavaScriptのソースコードを解説するためにコメントを使っていきます。
コメントの書き方には、一行コメントと複数行コメントの2種類があります。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > コメント を参照しましょう。
ポイント
//以降から行末までが一行コメント/*と*/で囲まれた範囲が複数行コメント
やってみよう!
// これは一行コメント
/*
これは
複数行
コメント
*/
// JavaScriptを使えば…
// 自由にテキストを書き換えることもできます!
document.body.textContent = "JavaScriptの世界からこんにちは!✨";
演算子
JavaScript Primer > 基本文法 > 演算子
演算子はよく利用する演算処理を記号などで表現したものです。
たとえば、足し算をする + も演算子の一種です。これ以外にも演算子には多くの種類があります。
演算子は演算する対象を持ちます。この演算子の対象のことを被演算子(オペランド)と呼びます。
次のコードでは、+演算子が値同士を足し算する加算演算を行っています。
このとき、+演算子の対象となっている1と2という2つの値がオペランドです。
1 + 2;
このコードでは+演算子に対して、前後に合計2つのオペランドがあります。
このように、2つのオペランドを取る演算子を二項演算子と呼びます。
// 二項演算子とオペランドの関係
左オペランド 演算子 右オペランド
また、1つの演算子に対して1つのオペランドだけを取るものもあります。
たとえば、数値をインクリメントする++演算子は、次のように前後どちらか一方にオペランドを置きます。
let num = 1;
num++;
// または
++num;
このように、1つのオペランドを取る演算子を単項演算子と呼びます。 単項演算子と二項演算子で同じ記号を使うことがあるため、呼び方を変えています。
この章では、演算子ごとにそれぞれの処理について学んでいきます。 また、演算子の中でも比較演算子は、JavaScriptでも特に挙動が理解しにくい暗黙的な型変換という問題と密接な関係があります。 そのため、演算子をひととおり見た後に、暗黙的な型変換と明示的な型変換について学んでいきます。
演算子の種類は多いため、すべての演算子の動作をここで覚える必要はありません。 必要となったタイミングで、改めてその演算子の動作を見るのがよいでしょう。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 演算子 を参照しましょう。
ポイント
- 演算子はよく利用する演算処理を記号などで表現したもの
- 四則演算や論理演算などさまざまな種類の演算子がある
- 演算子には優先順位が定義されており、グループ化演算子で明示できる
条件分岐
JavaScript Primer > 基本文法 > 条件分岐
この章ではif文やswitch文を使った条件分岐について学んでいきます。 条件分岐を使うことで、特定の条件を満たすかどうかで行う処理を変更できます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 条件分岐 を参照しましょう。
ポイント
- if文

やってみよう!
let color = "white";
if (Math.random() < 0.5) {
color = "green";
}
document.body.style.backgroundColor = color;
document.body.textContent = `今日のラッキーカラー: ${color}`;
- Math - JavaScript | MDN
Math.random()は0以上1未満の疑似乱数を返します。
関数と宣言
JavaScript Primer > 基本文法 > 関数と宣言
関数とは、ある一連の手続き(文の集まり)を1つの処理としてまとめる機能です。 関数を利用することで、同じ処理を毎回書くのではなく、一度定義した関数を呼び出すことで同じ処理を実行できます。
これまで利用してきたコンソール表示をするConsole APIも関数です。
console.logは「受け取った値をコンソールへ出力する」という処理をまとめた関数です。
この章では、関数の定義方法や呼び出し方について見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 関数と宣言 を参照しましょう。
ポイント
- 関数の宣言方法
やってみよう!
function 円の面積(r) {
return Math.PI * r * r;
}
const r1 = 1;
const r2 = 3;
document.body.textContent = `
半径 ${r1} m の円の面積: ${円の面積(r1)} m²
半径 ${r2} m の円の面積: ${円の面積(r2)} m²
`;
Math.PIは円周率(およそ3.14159)を表すMathオブジェクトの静的プロパティです。
ループと反復処理
JavaScript Primer > 基本文法 > ループと反復処理
この章では、while文やfor文などの基本的な反復処理と制御文について学んでいきます。
プログラミングにおいて、同じ処理を繰り返すために同じコードを繰り返し書く必要はありません。 ループやイテレータなどを使い、反復処理として同じ処理を繰り返し実行できます。
また、for文などのような構文だけではなく、配列のメソッドを利用して反復処理を行う方法もあります。 配列のメソッドを使った反復処理もよく利用されるため、合わせて見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > ループと反復処理 を参照しましょう。
ポイント
- while文
- for文

やってみよう!
const text = "いろはにほへと";
for (const c of text) {
document.body.textContent += `【${c}】`;
}
非同期処理
JavaScript Primer > 基本文法 > 非同期処理:Promise/Async Function
この章ではJavaScriptの非同期処理について学んでいきます。 非同期処理はJavaScriptにおけるとても重要な概念です。 また、ブラウザやNode.jsなどのAPIには非同期処理でしか扱えないものもあるため、非同期処理を避けることはできません。 JavaScriptには非同期処理を扱うためのPromiseというビルトインオブジェクト、さらにはAsync Functionと呼ばれる構文的なサポートがあります。
この章では非同期処理とはどのようなものかという話から、非同期処理での例外処理、非同期処理の扱い方を見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 非同期処理:Promise/Async Function を参照しましょう。
ポイント
- 非同期処理はその処理が終わるのを待つ前に次の処理を評価すること
await式- 書式:
await 関数() - 意味:
await式は Async Function関数()が完了するまで待つ
- 書式:
- Async Function …
async function 関数() { <awaitの含まれる文>; }- 非同期処理を行う関数
await式は Async Function の中で利用できる
一定時間待機
一定時間待機するAsync Function sleep() の作り方を解説します。
setTimeout(<コールバック関数>, <ミリ秒>) 関数は指定されたミリ秒後にコールバック関数を実行するための関数です。コールバック関数とは、簡単に言うと「後で使うために渡しておく関数」です。
次のコードは「3秒後にメッセージを表示する」という処理のプログラムです。メッセージの表示処理を resolve() 関数として宣言し、その関数名をコールバック関数として書きます。
function resolve() {
console.log("3秒!");
}
setTimeout(resolve, 3000); // 3秒 = 3,000ミリ秒
実行すると3秒後にメッセージ“3秒!“が表示されたかと思います。 これでも十分短いコードですが、今度はPromiseとawaitを使って書き換えてみます。
await new Promise((resolve) => setTimeout(resolve, 3000));
console.log("3秒!");
こうすることで上から下へと順番に実行する処理順で書けます。 これにより時間がかかるようなプログラムをもっと簡単に読みやすく書くことができます。
Note
現実世界と非同期処理コンピューターの上ではどのようなタイミングで何を行うかプログラマーが自由に決めることができますが、現実の世界では同じ時刻でも様々な事象が常に起こっています。 私たちの日常生活は多くの非同期的なイベントで構成されていると言えます。 非同期処理の概念を理解しておくことは現実の問題をコンピューターの上で扱うのにとても役に立ちます。
関数を使用して指定されたミリ秒(ms)だけ待つように一般化してみましょう。
ここで await 式は通常の関数のなかでは利用できず、代わりにAsync Functionの中で利用できるという点に注意しましょう。
まとめるとこのようになります:
async function sleep(ms) {
await new Promise((resolve) => setTimeout(resolve, ms));
}
使用方法:
await sleep(ミリ秒);
インターネットからのデータの取得
インターネットからデータを取得する際にも、その処理が完了するまで待つ必要があります。
書式:
let res = await fetch(取得するURL);
let data = await res.json();
最初の await 式でAPIからの応答を待ち、次に res.json() の処理の完了を待ちます。
このようにしてデータが完全に取得されるまでコードの実行が一時停止し、データが利用可能になると処理を再開します。
やってみよう!
const button = document.createElement("button");
button.textContent = "スタート";
document.body.append(button);
async function sleep(ms) {
await new Promise(resolve => setTimeout(resolve, ms));
}
button.addEventListener("click", async function () {
await sleep(3000); // クリックしてから3秒待つ
document.body.append("3秒!");
});
暗黙的な型変換
JavaScript Primer > 基本文法 > 暗黙的な型変換
この章では、明示的な型変換と暗黙的な型変換について学んでいきます。
「演算子」の章にて、 等価演算子(==)ではなく厳密等価演算子(===)の利用を推奨していました。
これは厳密等価演算子(===)が暗黙的な型変換をせずに、値同士を比較できるためです。
厳密等価演算子(===)では異なるデータ型を比較した場合に、その比較結果は必ずfalseとなります。
次のコードは、数値の1と文字列の"1"という異なるデータ型を比較しているので、結果はfalseとなります。
// `===`では、異なるデータ型の比較結果はfalse
console.log(1 === "1"); // => false
しかし、等価演算子(==)では異なるデータ型を比較した場合に、同じ型となるように暗黙的な型変換をしてから比較します。
次のコードでは、数値の1と文字列の"1"の比較結果がtrueとなっています。
これは、等価演算子(==)は右辺の文字列"1"を数値の1へと暗黙的な型変換をしてから、比較するためです。
// `==`では、異なるデータ型は暗黙的な型変換をしてから比較される
// 暗黙的な型変換によって 1 == 1 のように変換されてから比較される
console.log(1 == "1"); // => true
このように、暗黙的な型変換によって意図しない結果となるため、比較には厳密等価演算子(===)を使うべきです。
別の暗黙的な型変換の例として、数値と真偽値の加算を見てみましょう。 多くの言語では、数値と真偽値の加算のような異なるデータ型同士の加算はエラーとなります。 しかし、JavaScriptでは暗黙的な型変換が行われてから加算されるため、エラーなく処理されます。
次のコードでは、真偽値のtrueが数値の1へと暗黙的に変換されてから加算処理が行われます。
// 暗黙的な型変換が行われ、数値の加算として計算される
1 + true; // => 2
// 次のように暗黙的に変換されてから計算される
1 + 1; // => 2
JavaScriptでは、エラーが発生するのではなく、暗黙的な型変換が行われてしまうケースが多くあります。 暗黙的に変換が行われた場合、プログラムは例外を投げずに処理が進むため、バグの発見が難しくなります。 このように、暗黙的な型変換はできる限り避けるべき挙動です。
この章では、次のことについて学んでいきます。
- 暗黙的な型変換とはどのようなものなのか
- 暗黙的ではない明示的な型変換の方法
- 明示的な変換だけでは解決しないこと
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 暗黙的な型変換 を参照しましょう。
ポイント
- 暗黙的な型変換がある
- できるだけ
===での比較や明示的な型変換をしたほうが読みやすい
文と式
JavaScript Primer > 基本文法 > 文と式
本格的に基本文法について学ぶ前に、JavaScriptというプログラミング言語がどのような要素からできているかを見ていきましょう。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 文と式 を参照しましょう。
ポイント
- JavaScriptは文(Statement)と式(Expression)から構成される
- 式は値を生成し、変数に代入できるもの
- 文は処理の単位
- 文の末尾にはセミコロン
;をつける
オブジェクト
JavaScript Primer > 基本文法 > オブジェクト
オブジェクトはプロパティの集合です。プロパティとは名前(キー)と値(バリュー)が対になったものです。
プロパティのキーには文字列またはSymbolが利用でき、値には任意のデータを指定できます。
また、1つのオブジェクトは複数のプロパティを持てるため、1つのオブジェクトで多種多様な値を表現できます。
今までも登場してきた、配列や関数などもオブジェクトの一種です。
JavaScriptには、あらゆるオブジェクトの元となるObjectというビルトインオブジェクトがあります。
ビルトインオブジェクトは、実行環境にあらかじめ定義されているオブジェクトのことです。
ObjectというビルトインオブジェクトはECMAScriptの仕様で定義されているため、あらゆるJavaScriptの実行環境で利用できます。
この章では、オブジェクトの作成や扱い方、Objectというビルトインオブジェクトについて見ていきます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > オブジェクト を参照しましょう。
ポイント
- オブジェクトはプロパティの集合
{}(オブジェクトリテラル)でのオブジェクトの作成や更新方法
配列
配列はJavaScriptの中でもよく使われるオブジェクトです。
配列とは値に順序をつけて格納できるオブジェクトです。
配列に格納したそれぞれの値のことを要素、それぞれの要素の位置のことをインデックス(index)と呼びます。
インデックスは先頭の要素から0、1、2のように0からはじまる連番となります。
またJavaScriptにおける配列は可変長です。 そのため配列を作成後に配列へ要素を追加したり、配列から要素を削除できます。
この章では、配列の基本的な操作と配列を扱う場合においてのパターンについて学びます。
― この文章は © 2023 jsprimer project クリエイティブ・コモンズ CC BY 4.0 ライセンスのもとに利用を許諾されています。
続きは JavaScript Primer > 基本文法 > 配列 を参照しましょう。
ポイント
- 配列は値に順序をつけて格納できるオブジェクト
[](配列リテラル)での配列の作成や更新方法
やってみよう!
function drawFortune() {
const fortunes = ["大吉", "中吉", "吉", "小吉", "凶", "大凶"];
const i = Math.floor(Math.random() * fortunes.length);
document.body.textContent = `あなたの運勢は... ${fortunes[i]}です!`;
}
drawFortune();
- Math - JavaScript | MDN
Math.floor(x)はx以下の最大の整数を返します。Math.random()は0以上1未満の疑似乱数を返します。
Webサイトを公開する
作成したWebサイトを無料で公開する方法を紹介します。
GitHubを使う
GitHub https://github.com を使うことでより本格的にWebサイトを公開できます (このガイドもそうです)。
GitHubを使うにはアカウントの作成が必要です。まずGitHubの無料アカウントを作成しましょう。
Webページを公開する流れ:
自分に合った方法でWebサイトを公開してみましょう!
GitHubでのアカウントの作成
GitHub Pagesサイトの作成
Google Apps Script (GAS) で作るWebアプリ
Webブラウザー上で動作するアプリの作り方を紹介します。地図を表示するためのサードパーティAPI、Google Apps Script、そしてWebブラウザーの位置情報APIの使い方を説明します。
地図上に位置を表示する
地図を表示するためのサードパーティAPI (Leaflet) を使用し、地図上に位置を表示します。
書式
地図:
<link rel="stylesheet" href="https://unpkg.com/leaflet/dist/leaflet.css" />
<script src="https://unpkg.com/leaflet"></script>
<script type="module">
const map = L.map("map").setView([36, 138], 15);
// OpenStreetMapのデータはOpen Database Licenseのもとに利用を許諾されています。
L.tileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png", {
attribution: `© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors`,
}).addTo(map);
</script>
<h1>位置情報メモ</h1>
<div id="map" style="width: 500px; height: 500px"></div>
現在地の取得:
async function getLatLng() {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return [position.coords.latitude, position.coords.longitude];
}
// [<緯度>, <経度>]
const here = await getLatLng();
丸いマーカーの表示:
L.circleMarker([<緯度>, <経度>]).addTo(map);
地図の移動:
map.flyTo([<緯度>, <経度>]);
サンプルコード (全体)
<!doctype html>
<meta charset="UTF-8" />
<title>GASで作るWebアプリ - 位置情報メモ</title>
<link rel="stylesheet" href="https://unpkg.com/leaflet/dist/leaflet.css" />
<script src="https://unpkg.com/leaflet"></script>
<script type="module">
/** 経緯度の取得 */
async function getLatLng() {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return [position.coords.latitude, position.coords.longitude];
}
const map = L.map("map").setView([36, 138], 15);
// OpenStreetMapのデータはOpen Database Licenseのもとに利用を許諾されています。
L.tileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png", {
attribution: `© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors`,
}).addTo(map);
// 現在地
const here = await getLatLng();
// 現在地にマーカーを表示
L.circleMarker(here).addTo(map);
// 現在地に移動
map.flyTo(here);
</script>
<h1>位置情報メモ</h1>
<div id="map" style="width: 500px; height: 500px"></div>
Note
[36, 138]は日本の地理的中心、北緯36度東経138度、長野県上伊那郡辰野町の区有林。
位置情報API (Geolocation API) を使用すると、自分の位置情報をWebアプリから取得することができます。 位置情報APIの初回使用時には、位置情報の許可を求められるので[許可]を選択します。
位置情報が地図上に表示されることを確認してみましょう。
スプレッドシートの作成
Googleスプレッドシートを作成し、Google Apps Scriptのプロジェクトを作成します。
事前準備
- Googleアカウント
スプレッドシートの作成
https://sheet.new にアクセス、または「スプレッドシートのホーム画面」を開き、+をクリックします。
参考: Google スプレッドシートの使い方 - パソコン - Google ドキュメント エディタ ヘルプ
プロジェクトの作成
[拡張機能] > [Apps Script] を選択し、Google Apps Scriptのプロジェクトを作成します。
以下のコードをコピーして貼り付け、💾 [プロジェクトを保存] します。
// 最初のシート
const [sheet] = SpreadsheetApp.getActiveSpreadsheet().getSheets();
/**
* @example 行全体の取得
* const res = await fetch("https://script.google.com/{SCRIPTID}/exec");
* const rows = await res.json();
* // [
* // ["2006-01-02T15:04:05.999Z",1,2],
* // ["2006-01-02T15:04:06.000Z",3,4],
* // ...
* // ]
*/
function doGet() {
const rows = sheet.getDataRange().getValues().slice(1);
return ContentService.createTextOutput(JSON.stringify(rows)).setMimeType(
ContentService.MimeType.JSON,
);
}
/**
* @example 行の挿入
* const row = [5,6];
* await fetch("https://script.google.com/{SCRIPTID}/exec", { method: "POST", body: JSON.stringify(row) })
*/
function doPost(e) {
const row = JSON.parse(e.postData.contents);
sheet.appendRow([new Date(), ...row]);
return doGet();
}
プロジェクトを保存できたら、そのプロジェクトを利用可能にします。
プロジェクトのデプロイ
プロジェクトを新しくデプロイするには [デプロイ] > [新しいデプロイ] から行います。
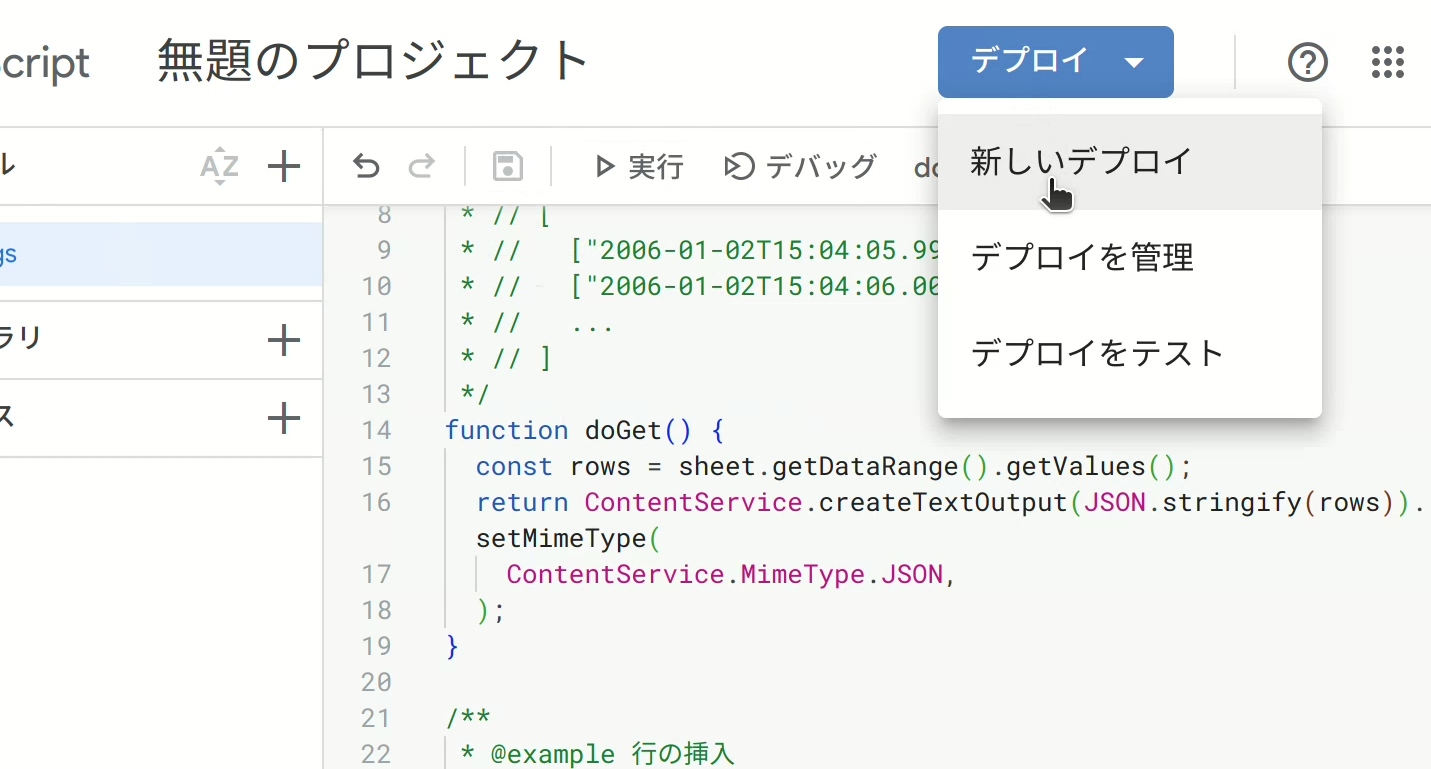
[種類の選択] ⚙ > [ウェブアプリ] を選択します。
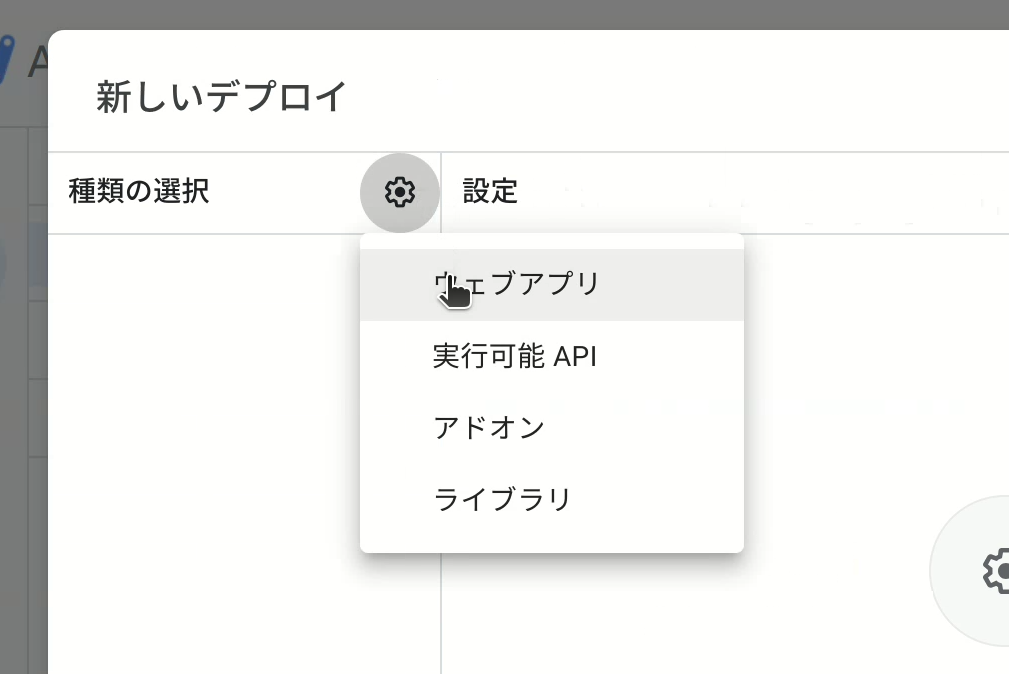
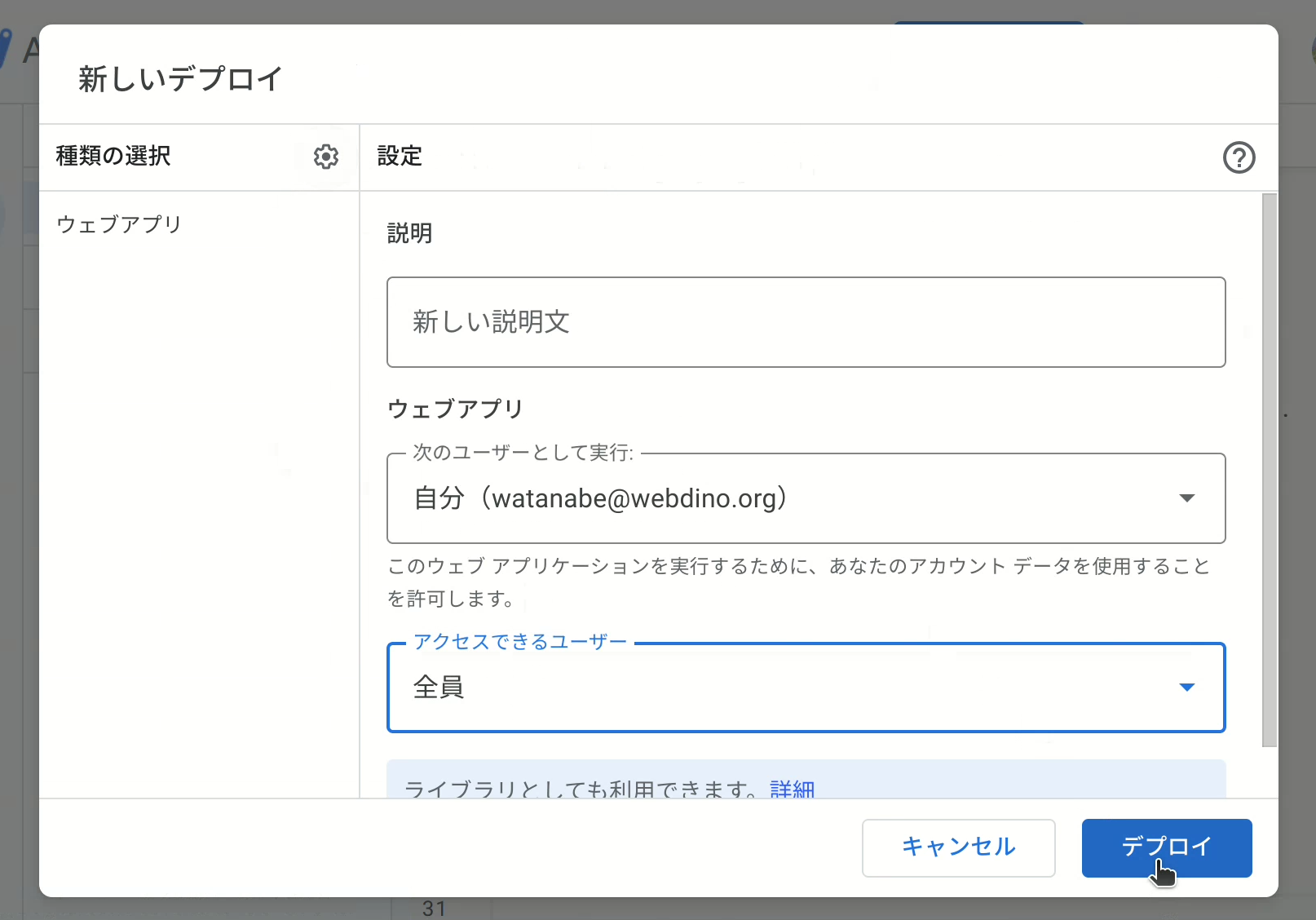
[アクセスできるユーザー] > [全員] を選択し、[デプロイ] を選択します。
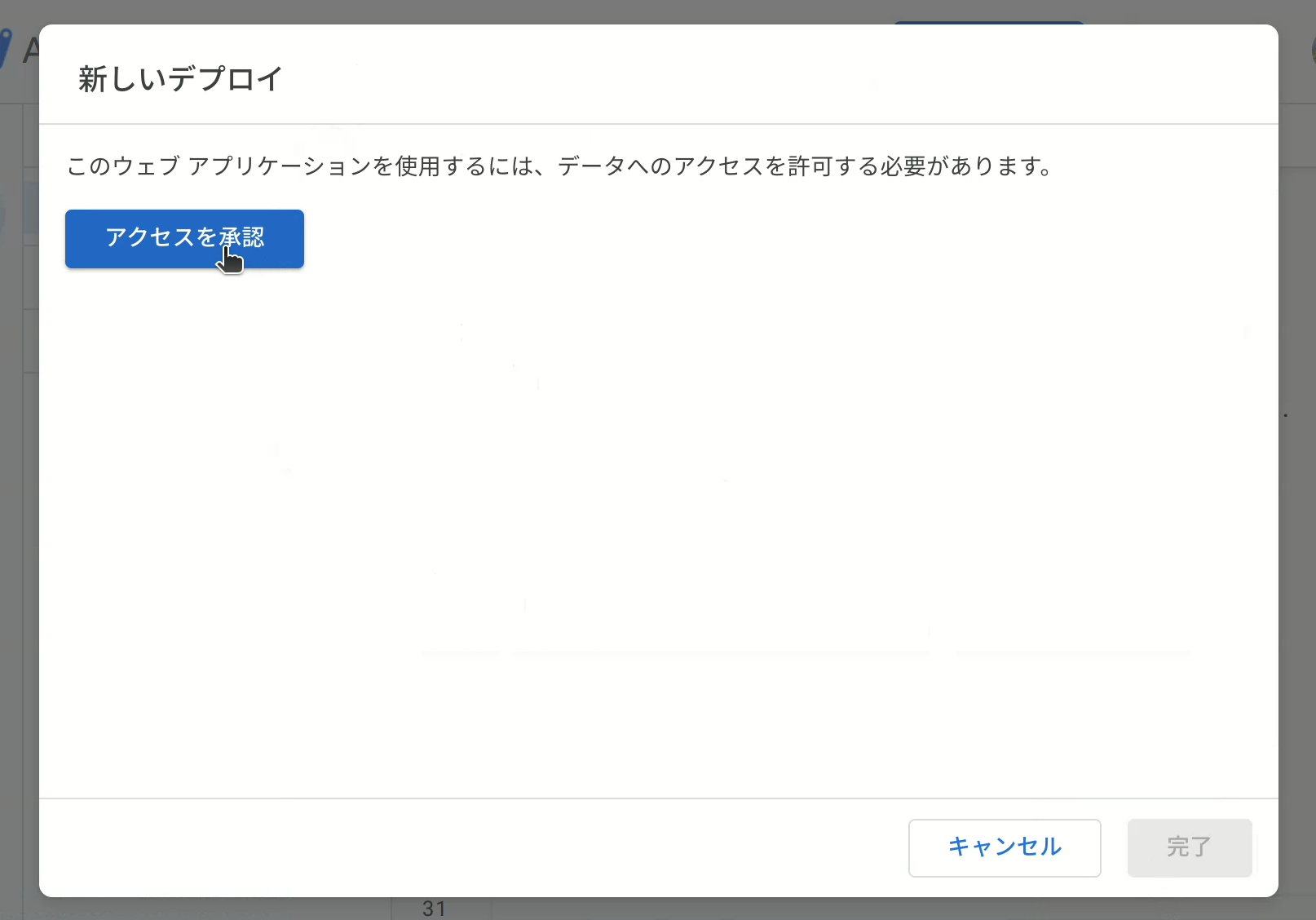
Googleアカウントへのアクセス許可を求められるのでアカウントを選択し、[Allow] をクリックします
WebアプリのURLが表示されればデプロイ完了です。

データの送信にはこのWebアプリのURL (https://script.google.com/macros/s/AKf...) を使用します。
このURLはコピーしておきましょう。
使用方法
データの取得:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const res = await fetch(endpoint);
const rows = await res.json();
データの送信:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const row = [...<送信する内容>...];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
WebアプリのURLと送信する内容の部分は適宜変更して使用します。
送信してみよう!
サンプルコード:
const row = [42];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
endpoint =
レスポンス:
nullデータを送信する
フォームからデータを送信してみましょう。
書式
HTMLとJavaScriptでコメント入力欄を作ります。
HTML:
<form>
<input name="comment" placeholder="コメント" required />
<button type="submit">送信</button>
</form>
JavaScript:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const form = document.querySelector("form");
form.addEventListener("submit", async function submit(e) {
e.preventDefault();
document.body.style.cursor = "wait";
const formData = new FormData(form);
const comment = formData.get("comment");
const row = [comment];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
location.reload();
});
サンプルコード (全体)
<!doctype html>
<meta charset="UTF-8" />
<title>GASで作るWebアプリ - 位置情報メモ</title>
<meta name="viewport" content="width=device-width" />
<link rel="stylesheet" href="https://unpkg.com/leaflet/dist/leaflet.css" />
<script src="https://unpkg.com/leaflet"></script>
<script type="module">
/** 経緯度の取得 */
async function getLatLng() {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return [position.coords.latitude, position.coords.longitude];
}
const map = L.map("map").setView([36, 138], 15);
// OpenStreetMapのデータはOpen Database Licenseのもとに利用を許諾されています。
L.tileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png", {
attribution: `© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors`,
}).addTo(map);
// 現在地
const here = await getLatLng();
// 現在地にマーカーを表示
L.circleMarker(here).addTo(map);
// 現在地に移動
map.flyTo(here);
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const form = document.querySelector("form");
form.addEventListener("submit", async function submit(e) {
e.preventDefault();
document.body.style.cursor = "wait";
const formData = new FormData(form);
const comment = formData.get("comment");
const row = [comment];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
location.reload();
});
</script>
<h1>位置情報メモ</h1>
<div id="map" style="width: 500px; height: 500px"></div>
<form>
<input name="comment" placeholder="コメント" required />
<button type="submit">送信</button>
</form>
コメントを入力し、[送信] を選択します。
スプレッドシートにコメントのデータが記録されていることを確認してみましょう。
位置情報を送信する
ここまで説明に沿ってやってきていたら comment の後ろに現在地を書き加えれば現在地の緯度・経度を送信できます。
const row = [comment];
↓
const row = [comment, here[0], here[1]];
このように書き加えればOKです。
書式
// コメント, 緯度, 経度
const row = [comment, here[0], here[1]];
サンプルコード (全体)
<!doctype html>
<meta charset="UTF-8" />
<title>GASで作るWebアプリ - 位置情報メモ</title>
<meta name="viewport" content="width=device-width" />
<link rel="stylesheet" href="https://unpkg.com/leaflet/dist/leaflet.css" />
<script src="https://unpkg.com/leaflet"></script>
<script type="module">
/** 経緯度の取得 */
async function getLatLng() {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return [position.coords.latitude, position.coords.longitude];
}
const map = L.map("map").setView([36, 138], 15);
// OpenStreetMapのデータはOpen Database Licenseのもとに利用を許諾されています。
L.tileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png", {
attribution: `© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors`,
}).addTo(map);
// 現在地
const here = await getLatLng();
// 現在地にマーカーを表示
L.circleMarker(here).addTo(map);
// 現在地に移動
map.flyTo(here);
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const form = document.querySelector("form");
form.addEventListener("submit", async function submit(e) {
e.preventDefault();
document.body.style.cursor = "wait";
const formData = new FormData(form);
const comment = formData.get("comment");
const row = [comment, here[0], here[1]];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
location.reload();
});
</script>
<h1>位置情報メモ</h1>
<div id="map" style="width: 500px; height: 500px"></div>
<form>
<input name="comment" placeholder="コメント" required />
<button type="submit">送信</button>
</form>
スプレッドシートに位置情報が記録されていることを確認してみましょう。
データを取得する
最後にスプレッドシートのデータを地図上に表示してみましょう。
書式
データの取得:
const res = await fetch(endpoint);
const rows = await res.json();
// 日付と時刻, コメント, 緯度, 経度
for (const [timestamp, comment, lat, lng] of rows) {
// 日付と時刻
const date = new Date(timestamp).toLocaleString();
// …
}
マーカーの追加:
const popup = document.createElement("span");
popup.textContent = <表示する内容>;
L.marker([<緯度>, <経度>]).addTo(map).bindPopup(popup);
サンプルコード (全体)
<!doctype html>
<meta charset="UTF-8" />
<title>GASで作るWebアプリ - 位置情報メモ</title>
<meta name="viewport" content="width=device-width" />
<link rel="stylesheet" href="https://unpkg.com/leaflet/dist/leaflet.css" />
<script src="https://unpkg.com/leaflet"></script>
<script type="module">
/** 経緯度の取得 */
async function getLatLng() {
const position = await new Promise((resolve, reject) =>
navigator.geolocation.getCurrentPosition(resolve, reject),
);
return [position.coords.latitude, position.coords.longitude];
}
const map = L.map("map").setView([36, 138], 15);
// OpenStreetMapのデータはOpen Database Licenseのもとに利用を許諾されています。
L.tileLayer("https://tile.openstreetmap.org/{z}/{x}/{y}.png", {
attribution: `© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors`,
}).addTo(map);
// 現在地
const here = await getLatLng();
// 現在地にマーカーを表示
L.circleMarker(here).addTo(map);
// 現座地に移動
map.flyTo(here);
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const res = await fetch(endpoint);
const rows = await res.json();
for (const [timestamp, comment, lat, lng] of rows) {
const date = new Date(timestamp).toLocaleString();
const popup = document.createElement("span");
popup.textContent = `${date}: ${comment}`;
L.marker([lat, lng]).addTo(map).bindPopup(popup);
}
const form = document.querySelector("form");
form.addEventListener("submit", async function submit(e) {
e.preventDefault();
document.body.style.cursor = "wait";
const formData = new FormData(form);
const comment = formData.get("comment");
const row = [comment, here[0], here[1]];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
location.reload();
});
</script>
<h1>位置情報メモ</h1>
<div id="map" style="width: 500px; height: 500px"></div>
<form>
<input name="comment" placeholder="コメント" required />
<button type="submit">送信</button>
</form>
やってみよう!
- より魅力的にしていくにはどうすればよいか考えてみましょう
- 例: CSSを使ってきれいな見た目にする?
- 例: コードを整理する?
- 思いついたら「とりあえずやってみる」
参考文献
Raspberry Piで温度センサーのデータの送信
Google Apps Scriptを利用してRaspberry Piからスプレッドシートにデータを送信する方法を説明します。
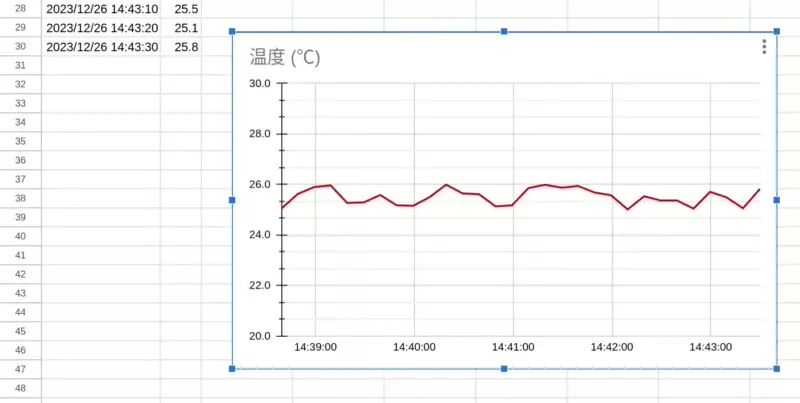
スプレッドシートの作成
Googleスプレッドシートを作成し、Google Apps Scriptのプロジェクトを作成します。
事前準備
- Googleアカウント
スプレッドシートの作成
https://sheet.new にアクセス、または「スプレッドシートのホーム画面」を開き、+をクリックします。
参考: Google スプレッドシートの使い方 - パソコン - Google ドキュメント エディタ ヘルプ
プロジェクトの作成
[拡張機能] > [Apps Script] を選択し、Google Apps Scriptのプロジェクトを作成します。
以下のコードをコピーして貼り付け、💾 [プロジェクトを保存] します。
// 最初のシート
const [sheet] = SpreadsheetApp.getActiveSpreadsheet().getSheets();
/**
* @example 行全体の取得
* const res = await fetch("https://script.google.com/{SCRIPTID}/exec");
* const rows = await res.json();
* // [
* // ["2006-01-02T15:04:05.999Z",1,2],
* // ["2006-01-02T15:04:06.000Z",3,4],
* // ...
* // ]
*/
function doGet() {
const rows = sheet.getDataRange().getValues().slice(1);
return ContentService.createTextOutput(JSON.stringify(rows)).setMimeType(
ContentService.MimeType.JSON,
);
}
/**
* @example 行の挿入
* const row = [5,6];
* await fetch("https://script.google.com/{SCRIPTID}/exec", { method: "POST", body: JSON.stringify(row) })
*/
function doPost(e) {
const row = JSON.parse(e.postData.contents);
sheet.appendRow([new Date(), ...row]);
return doGet();
}
プロジェクトを保存できたら、そのプロジェクトを利用可能にします。
プロジェクトのデプロイ
プロジェクトを新しくデプロイするには [デプロイ] > [新しいデプロイ] から行います。
[種類の選択] ⚙ > [ウェブアプリ] を選択します。
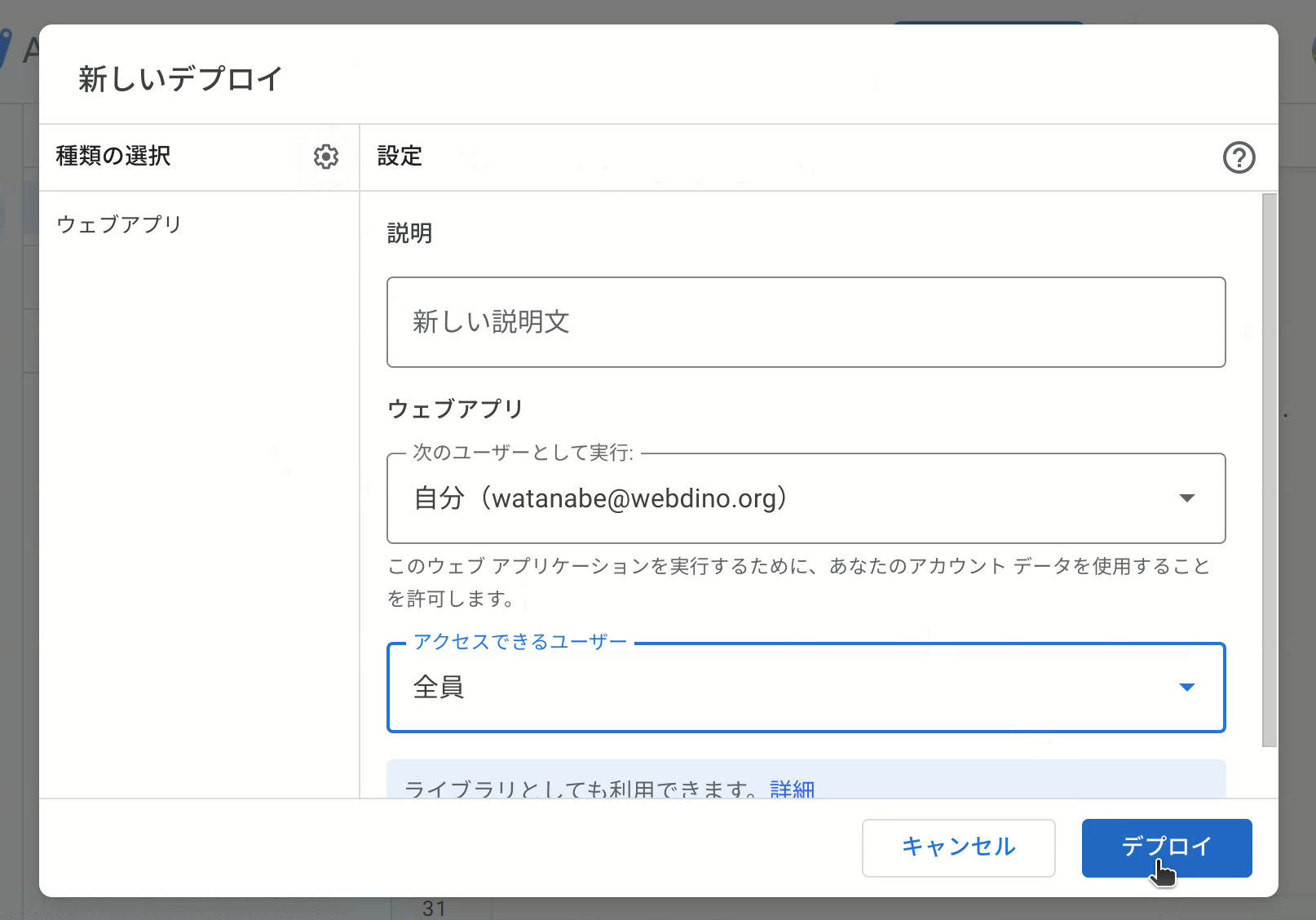
[アクセスできるユーザー] > [全員] を選択し、[デプロイ] を選択します。
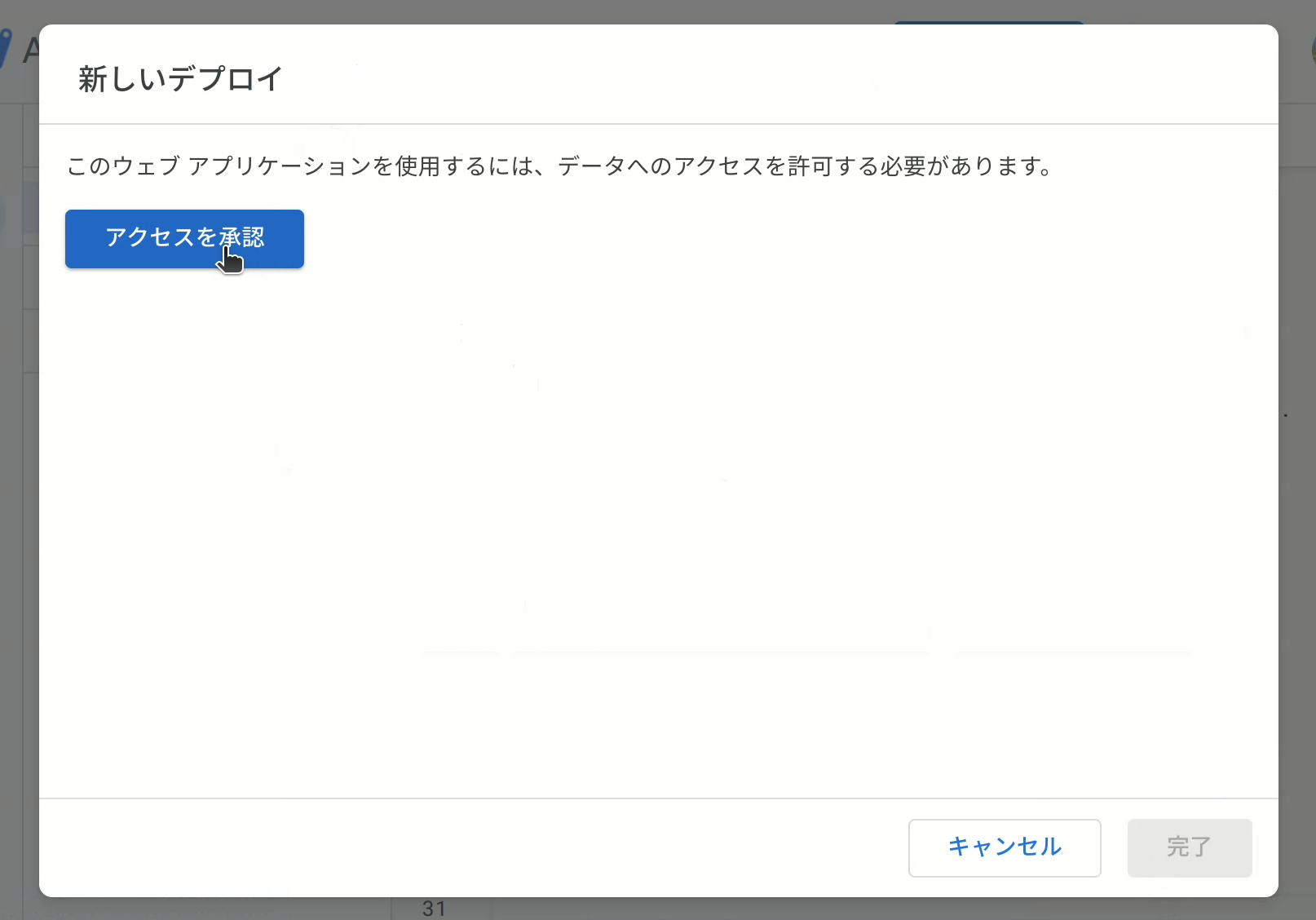
Googleアカウントへのアクセス許可を求められるのでアカウントを選択し、[Allow] をクリックします
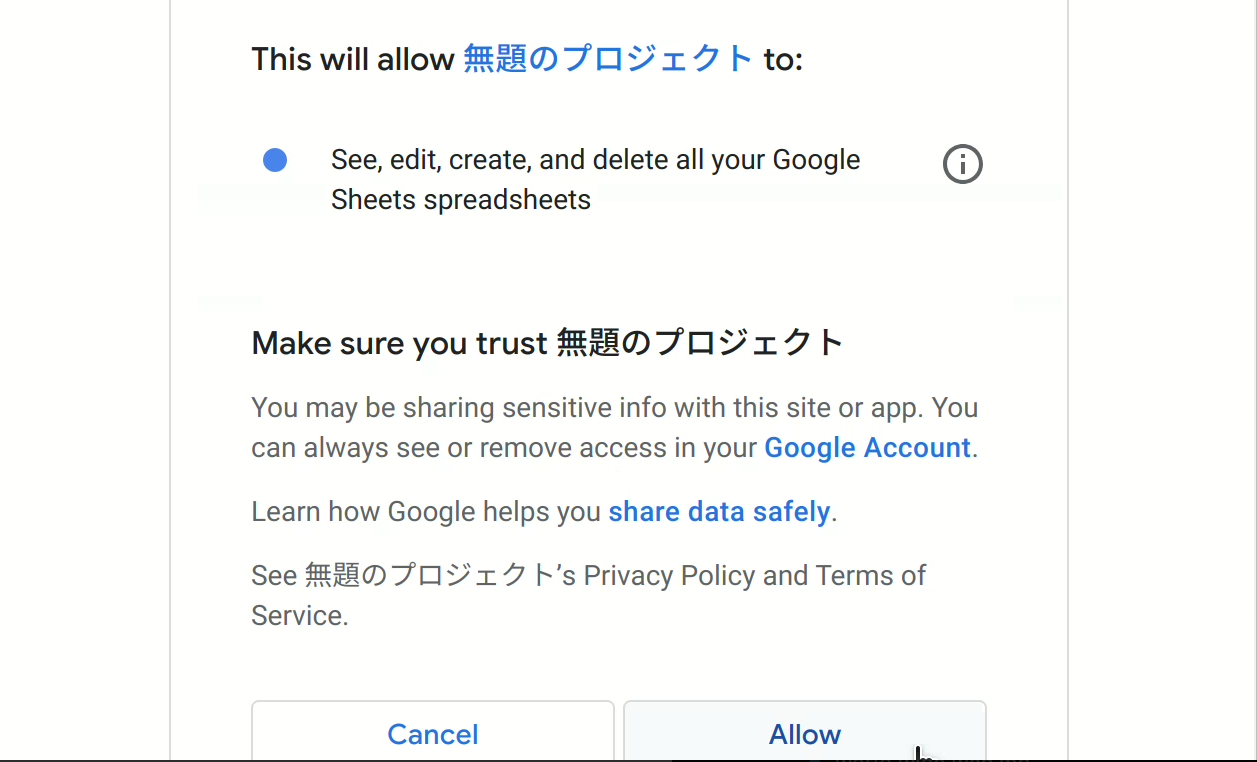
WebアプリのURLが表示されればデプロイ完了です。

データの送信にはこのWebアプリのURL (https://script.google.com/macros/s/AKf...) を使用します。
このURLはコピーしておきましょう。
使用方法
データの取得:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const res = await fetch(endpoint);
const rows = await res.json();
データの送信:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
const row = [...<送信する内容>...];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
WebアプリのURLと送信する内容の部分は適宜変更して使用します。
送信してみよう!
サンプルコード:
const row = [42];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
endpoint =
レスポンス:
null温度センサーのデータの送信
それではRaspberry Piからスプレッドシートにデータを送信してみましょう。
温度センサー SHT30 を利用して温度のデータを送信します。
事前準備
- Raspberry Pi
- SHT30 (温度・湿度センサ)
- 配線用のワイヤー
サンプルコード
次のようなNode.jsのコードを実行することでデータを送信します:
// ここはWebアプリのURLに書き換えます
const endpoint = "https://script.google.com/{SCRIPTID}/exec";
import { requestI2CAccess } from "node-web-i2c";
import SHT30 from "@chirimen/sht30";
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
const i2cAccess = await requestI2CAccess();
const port = i2cAccess.ports.get(1);
const sht30 = new SHT30(port, 0x44);
await sht30.init();
while (true) {
const { humidity, temperature } = await sht30.readData();
const row = [temperature];
await fetch(endpoint, { method: "POST", body: JSON.stringify(row) });
const message = `現在の温度は${temperature.toFixed(2)}度です`;
console.log(endpoint, message);
// 10秒待機
await sleep(10000); // ms
}
スプレッドシートに温度センサーのデータが記録されていることを確認してみましょう。
グラフの作成
Googleスプレッドシートでグラフを作成します。
- グラフの列を選択します
- [挿入] > [グラフ] を選択します
グラフのタイトル
グラフの見た目を変更する方法をいくつか紹介します。
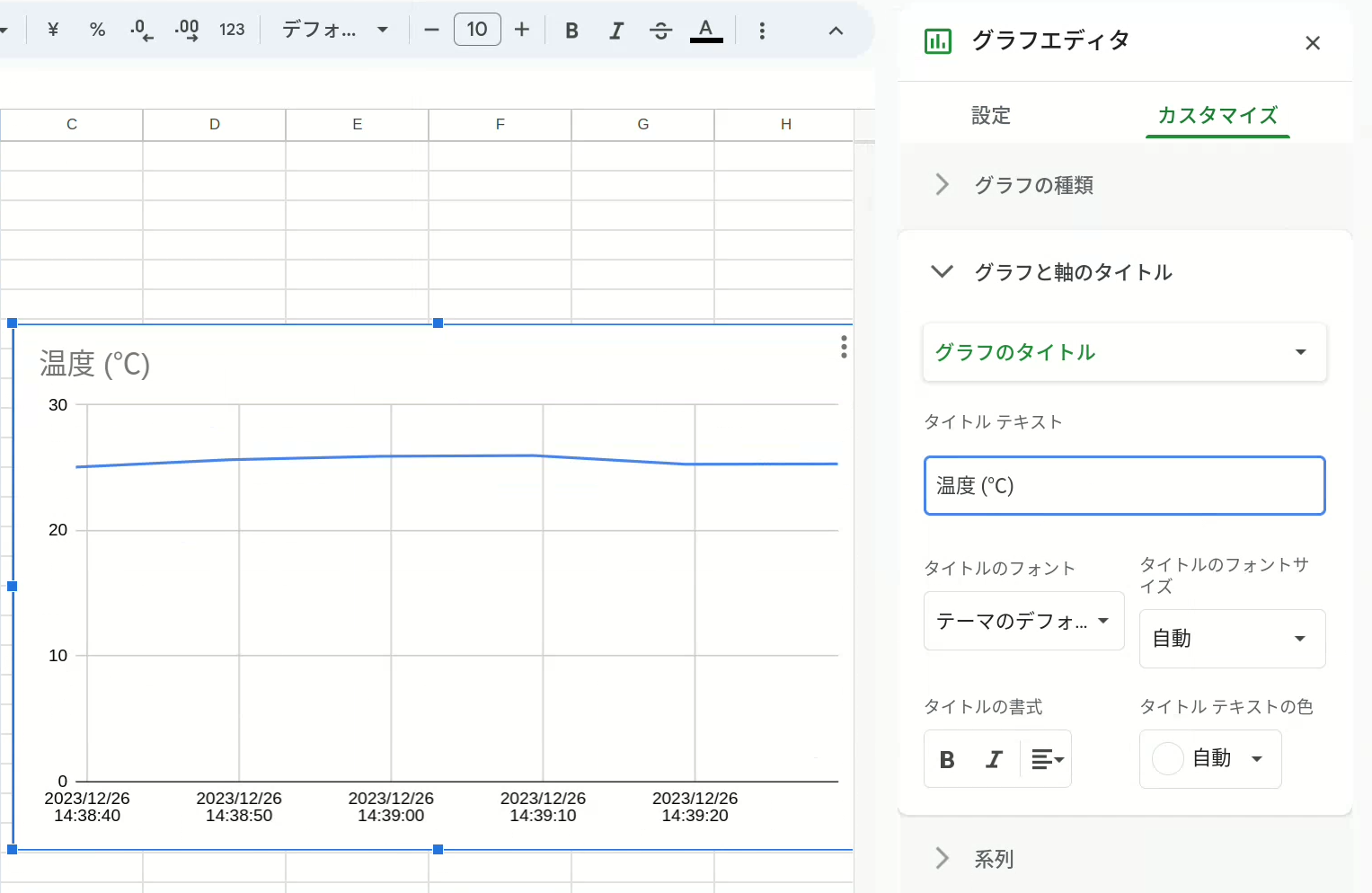
- 変更するグラフをダブルクリックします
- 右側の [カスタマイズ] を選択します
- [グラフと軸のタイトル] を選択します
- [グラフのタイトル] > タイトルテキストを入力します
縦軸の範囲の変更
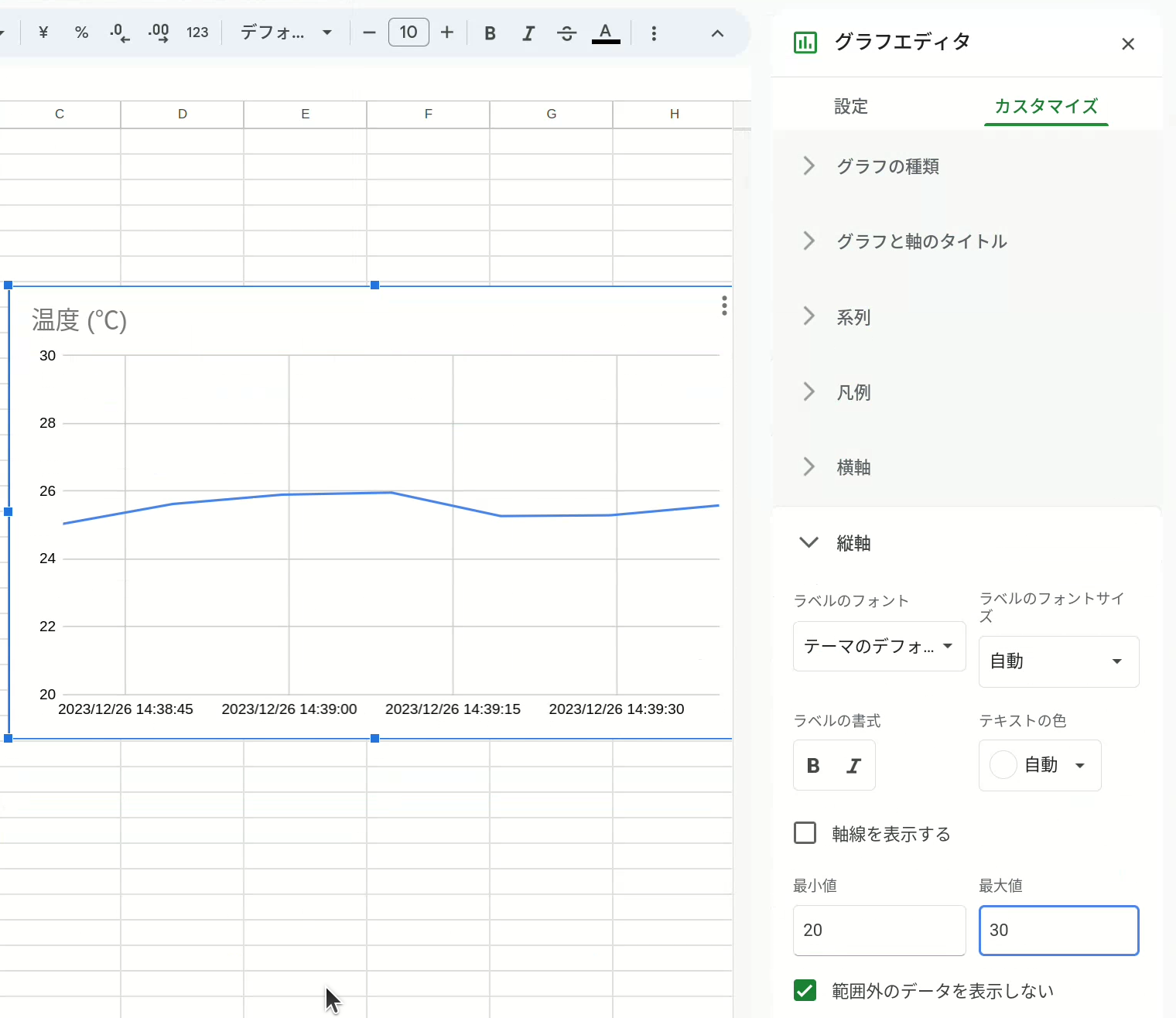
縦軸の表示範囲は [縦軸] > [最小値]/[最大値] を入力します。
目盛り
目盛りの追加は [グリッドラインと目盛] > [主目盛り]/[補助目盛り] を選択します。
表示形式
- グラフの列を選択します
- [表示形式] メニューから表示形式を選択します
参考文献
Raspberry Piからスマートフォンにデータを送信する
ntfy.shを利用してRaspberry Piからスマートフォンにデータを送信する方法を説明します。
ntfy.shは、ユーザーに通知を送信するためのシンプルなサービスです。このサービスは特定のイベントや条件が発生したときに通知を送るために利用できます。
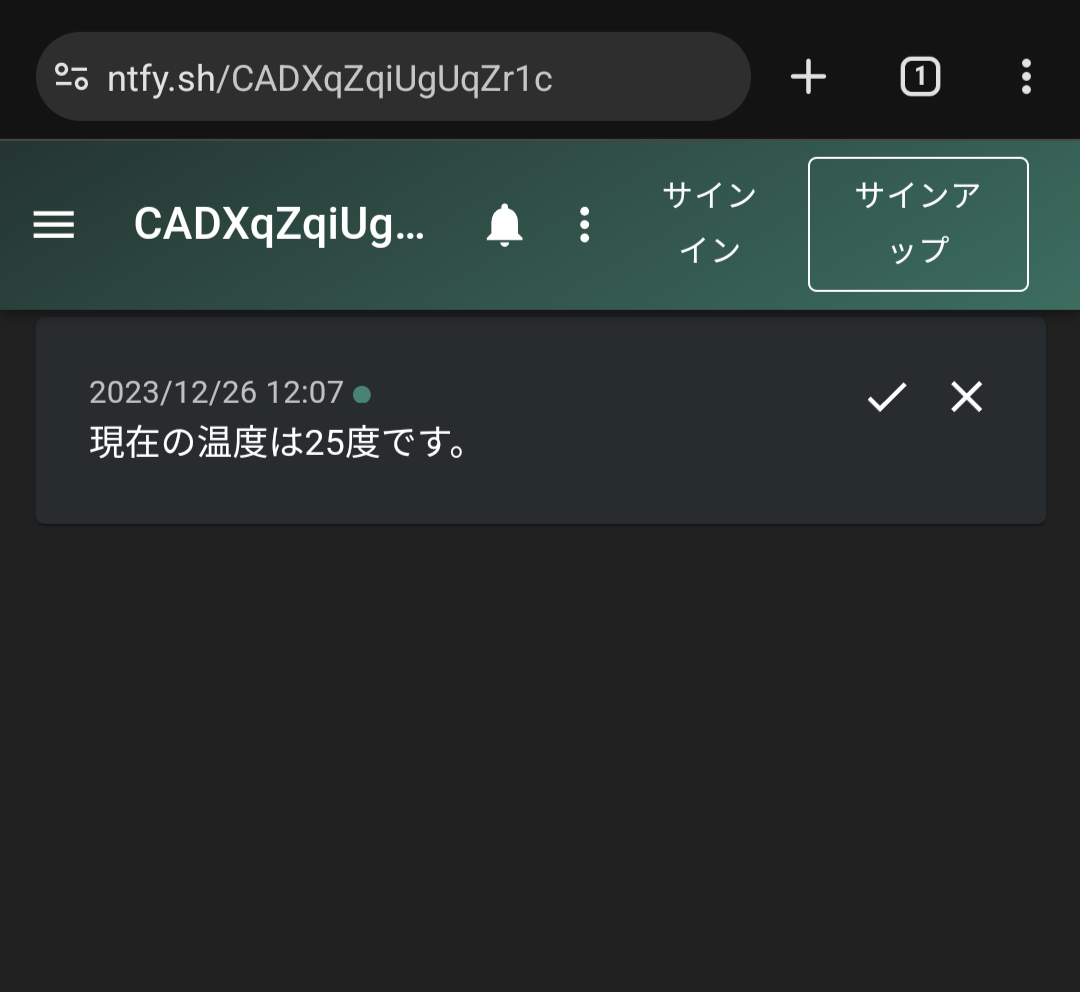
制約事項
(無料枠) 1日あたりのメッセージの上限は250件です。 10分あたり1件程度の通知を目安にしましょう。
その他にもAPIにはいくつかの制限があります。注意して利用しましょう。
| 制限 | 説明 |
|---|---|
| メッセージの長さ | 各メッセージの長さは最大 4,096 バイトです。長いメッセージは添付ファイルとして扱われます。 |
| リクエスト | デフォルトでは、サーバーは訪問者あたり一度に 60 件のリクエストを許可し、その後 5 秒に 1 件の割合で許可されたリクエスト バケットを補充するように設定されています。 |
| 1 日あたりのメッセージ | デフォルトでは、メッセージ数はリクエスト制限によって制御されます。これはオーバーライドできます。 ntfy.sh では、1 日あたりのメッセージ制限は 250 です。 |
| メール | デフォルトでは、サーバーは訪問者ごとに一度に 16 通の電子メールを送信できるように設定されており、許可された電子メール バケットは 1 時間に 1 通の割合で補充されます。 ntfy.sh では、1 日あたりの制限は 5 です。 |
| 電話通話 | デフォルトでは、通話制限のある層を持つユーザーを除き、サーバーは電話通話を許可しません。 |
| サブスクリプション制限 | デフォルトでは、サーバーは各訪問者がサーバーへの 30 接続を開いたままにすることを許可します。 |
| 添付ファイルのサイズ制限 | デフォルトでは、サーバーは添付ファイルのサイズが最大 15 MB、訪問者あたり合計で最大 100 MB、訪問者全体で最大 5 GB まで許可します。 ntfy.sh では、添付ファイルのサイズ制限は 2 MB で、訪問者あたりの合計は 20 MB です。 |
| 添付ファイルの有効期限 | デフォルトでは、サーバーは 3 時間後に添付ファイルを削除するため、訪問者の添付ファイルの合計制限からスペースが解放されます。 |
| 添付ファイルの帯域幅 | デフォルトでは、サーバーは 24 時間以内に訪問者ごとに 500 MB の添付ファイルの GET/PUT/POST トラフィックを許可します。それを超えるトラフィックは拒否されます。 ntfy.sh では、1 日の帯域幅制限は 200 MB です。 |
| トピックの総数 | デフォルトでは、サーバーは 15,000 のトピックを許可するように構成されています。ただし、ntfy.sh サーバーにはより高い制限があります。 |
https://docs.ntfy.sh/publish/#limitations より
トピックの作成
ntfy.shを利用するには、まずトピックを作成します。
新しいトピックを作成してみましょう:
トピックにアクセスし[購読]することで通知を受け取ることができるようになります。 このときのURLは忘れないようにメモしておきます。
使用方法
メッセージの送信:
// ここはntfy.shのURLに書き換えます
const endpoint = "https://ntfy.sh/mytopic";
const message = `<メッセージ本文>`;
const res = await fetch(endpoint, { method: "POST", body: message });
送信してみよう!
サンプルコード:
const message = `現在の時刻は ${new Date().toTimeString()} です`;
await fetch(endpoint, { method: "POST", body: message });
endpoint =
レスポンス:
null温度センサーのデータの送信
それではRaspberry Piからスマートフォンにデータを送信してみましょう。
温度センサー SHT30 を利用して温度のデータを送信します。
事前準備
- Raspberry Pi
- SHT30 (温度・湿度センサ)
- 配線用のワイヤー
配線図
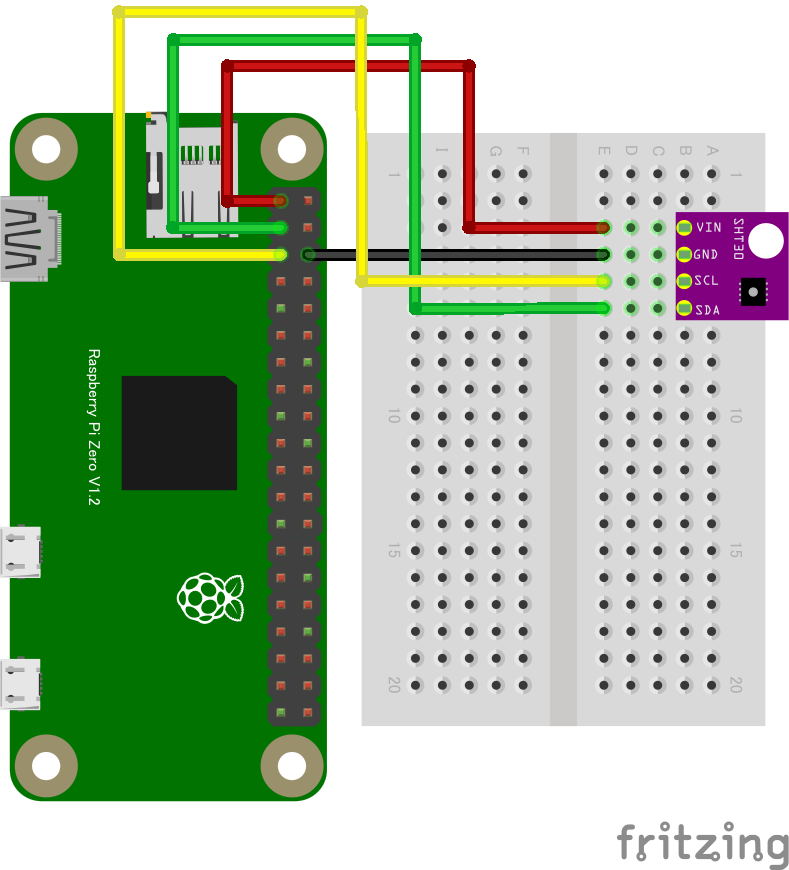
書式
// ここはntfy.shのURLに書き換えます
const endpoint = <ntfy.shのURL>;
await fetch(endpoint, { method: "POST", body: <送信する内容> });
ntfy.shのURLと送信する内容の部分を書き換えて使用します。
スマートフォンに温度センサーのデータが送信されていることを確認してみましょう。
サンプルコード
次のようなNode.jsのコードを実行することでデータを送信します:
// ここはntfy.shのURLに書き換えます
const endpoint = "https://ntfy.sh/536804b7-65aa-403f-97f6-7bd945e83491";
import { requestI2CAccess } from "node-web-i2c";
import SHT30 from "@chirimen/sht30";
const i2cAccess = await requestI2CAccess();
const port = i2cAccess.ports.get(1);
const sht30 = new SHT30(port, 0x44);
await sht30.init();
const { humidity, temperature } = await sht30.readData();
const message = `現在の温度は${temperature.toFixed(2)}度です`;
await fetch(endpoint, { method: "POST", body: message });
console.log(endpoint, message);
制約事項
(無料枠) 1日あたりのメッセージの上限は250件です。 10分あたり1件程度の通知を目安にしましょう。
参考: https://docs.ntfy.sh/publish/#limitations より
Node.jsハンズオン
ソフトウェアテスト概論
Vitestハンズオン
Jestハンズオン
GraphQL概論
Hasura概論
Hasura RESTハンズオン
GitHub と CodeSandbox の使い方 (スライド資料)
CHIRIMENハンズオン
アジャイル開発概論
Scrapbox
質問・提案・問題の報告
もし気になることなどあれば、Cosense または GitHub Issues からお気軽にお寄せください。
Scrapbox
- 利用にはGoogleアカウントが必要です
- 詳しくはCosenseの使い方をご参照ください
GitHub
- 利用にはGitHubアカウントが必要です